No more mysteries: Apple's G5 versus x86, Mac OS X versus Linux
by Johan De Gelas on June 3, 2005 7:48 AM EST- Posted in
- Mac
IBM PowerPC 970FX: Superscalar monster
Meet the G5 processor, which is in fact IBM's PowerPC 970FX processor. The RISC ISA, which is quite complex and can hardly be called "Reduced" (The R of RISC), provides 32 architectural registers. Architectural registers are the registers that are visible to the programmer, mostly the compiler programmer. These are the registers that can be used to program the calculations in the binary (and assembler) code.
The 970FX is deeply pipelined, quite a bit deeper than the Athlon 64 or Opteron. While the Opteron has a 12 stage pipeline for integer calculations, the 970FX goes deeper and ends up with 16 stages. Floating point is handled through 21 stages, and the Opteron only needs 17. 21 stages might make you think that the 970FX is close to a Pentium 4 Northwood, but you should remember that the Pentium 4 also had 8 stages in front of the trace cache. The 20 stages were counted from the trace cache. So, the Pentium 4 has to do less work in those 20 stages than what the 970FX performs in those 16 or 21 stages. When it comes to branch prediction penalties, the 970FX penalty will be closer to the Pentium 4 (Northwood). But when it comes to frequency headroom, the 970FX should do - in theory - better than the Opteron, but does not come close to the "old" Pentium 4.
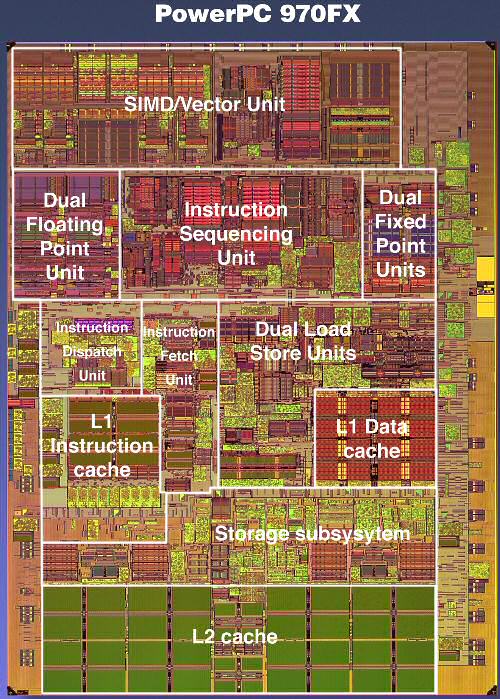
The 970FX works out of order and up to 200 instructions can be kept in flight, compared to 126 in the Pentium 4. The rate at which instructions are fetched will not limit the issue rate either. The PowerPC 970 FX fetches up to 8 instructions per cycle from the L1 and can decode at the same rate of 8 instructions per cycle. So, is the 970FX the ultimate out-of-order CPU?
While 200 instructions in flight are impressive, there is a catch. If there was no limitation except die size, CPUs would probably keep thousands of instructions in flight. However, the scheduler has to be able to pick out independent instructions (instructions that do not rely on the outcome of a previous one) out of those buffers. And searching and analysing the buffers takes time, and time is very limited at clock speeds of 2.5 GHz and more. Although it is true that the bigger the buffers, the better, the number of instructions that can be tracked and analysed per clock cycle is very limited. The buffer in front of the execution units is about 100 instructions big, still respectable compared to the Athlon 64's reorder buffer of 72 instructions, divided into 24 groups of 3 instructions.
The same grouping also happens on the 970FX or G5. But the grouping is a little coarser here, with 5 instructions in one group. This grouping makes reordering and tracking a little easier than when the scheduler would have to deal with 100 separate instructions.
The grouping is, at the same time, one of the biggest disadvantages. Yes, the Itanium also works with groups, but there the compilers should help the CPU with getting the slots filled. In the 970FX, the group must be assembled with pretty strict limitations, such as at one branch per group. Many other restrictions apply, but that is outside the scope of this article. Suffice it to say that it happens quite a lot that a few of the operations in the group consist of NOOP, no-operation, or useless "do nothing" instructions. Or that a group cannot be issued because some of the resources that one member of the group needs is not available ( registers, execution slots). You could say that the whole grouping thing makes the Superscalar monster less flexible.
Branch prediction is done by two different methods each with a gigantic 16K entry history table. A third "selector" keeps another 16K history to see which of the two methods has done the best job so far. Branch prediction seems to be a prime concern for the IBM designers.
Memory Subsystem
The caches are relatively small compared to the x86 competition. A 64 KB I-cache and 32 KB D-cache is relatively "normal", while the 512 KB L2-cache is a little small by today's standards. But, no complaints here. A real complaint can be lodged against the latency to the memory. Apple's own webpage talks about 135 ns access time to the RAM. Now, compare this to the 60 ns access time that the Opteron needs to access the RAM, and about 100-115 ns in the case of the Pentium 4 (with 875 chipset).A quick test with LM bench 2.04 confirms this:
| Host | OS | Mem read (MB/s) | Mem write (MB/s) | L2-cache latency (ns) | RAM Random Access (ns) |
| Xeon 3.06 GHz | Linux 2.4 | 1937 | 990 | 59.940 | 152.7 |
| G5 2.7 GHz | Darwin 8.1 | 2799 | 1575 | 49.190 | 303.4 |
| Xeon 3.6 GHz | Linux 2.6 | 3881 | 1669 | 78.380 | 153.4 |
| Opteron 850 | Linux 2.6 | 1920 | 1468 | 50.530 | 133.2 |
Memory latency is definitely a problem on the G5.
On the flipside of the coin is the excellent FSB bandwidth. The G5/Power PC 970FX 2.7 GHz has a 1.35 GHz FSB (Full Duplex), capable of sending 10.8 GB/s in each direction. Of course, the (half duplex) dual channel DDR400 bus can only use 6.4 GB/s at most. Still, all this bandwidth can be put to good use with up to 8 data prefetch streams.








116 Comments
View All Comments
Joepublic2 - Monday, June 6, 2005 - link
Wow, pixelglow, that's an awesome way to advertise your product. No marketing BS, just numbers!pixelglow - Sunday, June 5, 2005 - link
I've done a direct comparison of G5 vs. Pentium 4 here. The benchmark is cache-bound, minimal branching, maximal floating point and designed to minimize use of the underlying operating system. It is also single-threaded so there's no significant advantage to dual procs. More importantly it uses Altivec on G5 and SSE/SSE2 on the Pentium 4, and also compares against different compilers including the autovectorizing Intel ICC.http://www.pixelglow.com/stories/macstl-intel-auto...
http://www.pixelglow.com/stories/pentium-vs-g5/
Let the results speak for themselves.
webflits - Sunday, June 5, 2005 - link
"From the numbers, it seems like gcc was only capable of using Altivec in one test,"Nonsense!
The Altivec SIMD only supports single (32-bit) precision floating point and the benchmark uses double precision floating point.
webflits - Sunday, June 5, 2005 - link
Here are the resuls on a dual 2.0Ghz G5 running 10.4.1 using the stock Apple gcc 4.0 compiler.[Session started at 2005-06-05 22:47:52 +0200.]
FLOPS C Program (Double Precision), V2.0 18 Dec 1992
Module Error RunTime MFLOPS
(usec)
1 4.0146e-13 0.0163 859.4752
2 -1.4166e-13 0.0156 450.0935
3 4.7184e-14 0.0075 2264.2656
4 -1.2546e-13 0.0130 1152.8620
5 -1.3800e-13 0.0276 1051.5730
6 3.2374e-13 0.0180 1609.4871
7 -8.4583e-11 0.0296 405.4409
8 3.4855e-13 0.0200 1498.4641
Iterations = 512000000
NullTime (usec) = 0.0015
MFLOPS(1) = 609.8307
MFLOPS(2) = 756.9962
MFLOPS(3) = 1105.8774
MFLOPS(4) = 1554.0224
frfr - Sunday, June 5, 2005 - link
If you test a database you have to disable the write cache on the disk on almost any OS unless you don't care about your data. I've read that OS X is an exception because it allows the database software control over it, and that mySql indeed does use this. This would invalidate al your mySql results except for OS X.Besides all serious database's run on controllers with write cache with batteries (and with the write cache on the disks disabled).
nicksay - Sunday, June 5, 2005 - link
It is pretty clear that there are a lot of people who want Linux PPC benchmarks. I agree. I also think that if this is to be a "where should I position the G5/Mac OS X combination compared to x86/Linux/Windows" article, you should at least use the default OS X compiler. I got flops.c from http://home.iae.nl/users/mhx/flops.c to do my own test. I have a stock 10.4.1 install on a single 1.6 GHz G5.In the terminal, I ran:
gcc -DUNIX -fast flops.c -o flops
My results:
FLOPS C Program (Double Precision), V2.0 18 Dec 1992
Module Error RunTime MFLOPS
(usec)
1 4.0146e-13 0.0228 614.4905
2 -1.4166e-13 0.0124 565.3013
3 4.7184e-14 0.0087 1952.5703
4 -1.2546e-13 0.0135 1109.5877
5 -1.3800e-13 0.0383 757.4925
6 3.2374e-13 0.0220 1320.3769
7 -8.4583e-11 0.0393 305.1391
8 3.4855e-13 0.0238 1258.5012
Iterations = 512000000
NullTime (usec) = 0.0002
MFLOPS(1) = 736.3316
MFLOPS(2) = 578.9129
MFLOPS(3) = 866.8806
MFLOPS(4) = 1337.7177
A quick add-n-divide gives my system an average result of 985.43243.
985. On a single 1.6 G5.
So, the oldest, slowest PowerMac G5 ever made almost matches a top-of-the-line dual 2.7 G5 system?
To quote, "Something is rotten in the state of Denmark." Or should I say the state of the benchmark?
Eug - Saturday, June 4, 2005 - link
BTW, about the link I posted above:http://lists.apple.com/archives/darwin-dev/2005/Fe...
The guy who wrote that is the creator of the BeOS file system (and who now works for Apple).
It will be interesting to see if this is truly part of the cause of the performance issues.
Also, there is this related thread from a few weeks back on Slashdot:
http://hardware.slashdot.org/article.pl?sid=05/05/...
profchaos - Saturday, June 4, 2005 - link
The statement about Linux kernel modules is incorrect. It is a popular misconception that kernel modules make the Linux kernel something other than purely monolithic. The module loader links module code in kernelspace, not in userspace, the advantage being dynamic control of kernel memory footprint. Although some previously kernelspace subsystems, such as devfs, have been recently rewritten as userspace daemons, such as udev, the Linux kernel is for the most part a fully monolithic design. The theories that fueled the monolithic vs. microkernel flame wars of the mid-90s were nullified by the rapid ramping of single-thread performance relative to memory subsystems. From the perspective of the CPU, it take years for a context switch to occur since modifying kernel data structures in main memory is so slow relative to anything else. Userspace context switching is based on IPC in microkernel designs, and may require several context switches in practice. As you can see from the results, Linux 2.6 wipes the floor with Darwin just the same as it does with several of the BSDs (especially OpenBSD and FreeBSD4.x) and its older cousin Linux 2.4. It's also anyone's guess whether the Linux 2.6 systems were using pthreads (from NPTL) or linuxthreads in glibc. It takes a heavyweight UNIX server system, which today means IBM AIX on POWER, HP-UX on Itanium, or to a lesser degree Solaris on SPARC, to best Linux 2.6 under most server workloads.Eug - Saturday, June 4, 2005 - link
Responses/Musings from an Apple developer.http://ridiculousfish.com/blog/?p=17
http://lists.apple.com/archives/darwin-dev/2005/Fe...
Also:
They claim that making a new thread is called "forking". No, it’s not. Calling fork() is forking, and fork() makes processes, not threads.
They claim that Mac OS X is slower at making threads by benchmarking fork() and exec(). I don’t follow this train of thought at all. Making a new process is substantially different from making a new thread, less so on Linux, but very much so on OS X. And, as you can see from their screenshot, there is one mySQL process with 60 threads; neither fork() nor exec() is being called here.
They claim that OS X does not use kernel threads to implement user threads. But of course it does - see for yourself.
/* Create the Mach thread for this thread */
PTHREAD_MACH_CALL(thread_create(mach_task_self(), &kernel_thread), kern_res);
They claim that OS X has to go through "extra layers" and "several threading wrappers" to create a thread. But anyone can see in that source file that a pthread maps pretty directly to a Mach thread, so I’m clueless as to what "extra layers" they’re talking about.
They guess a lot about the important performance factors, but they never actually profile mySQL. Why not?
orenb - Saturday, June 4, 2005 - link
Thank you for a very interesting article. A follow up on desktop and workstation performance will be very appreciated... :-)Good job!