No more mysteries: Apple's G5 versus x86, Mac OS X versus Linux
by Johan De Gelas on June 3, 2005 7:48 AM EST- Posted in
- Mac
IBM PowerPC 970FX: Superscalar monster
Meet the G5 processor, which is in fact IBM's PowerPC 970FX processor. The RISC ISA, which is quite complex and can hardly be called "Reduced" (The R of RISC), provides 32 architectural registers. Architectural registers are the registers that are visible to the programmer, mostly the compiler programmer. These are the registers that can be used to program the calculations in the binary (and assembler) code.
The 970FX is deeply pipelined, quite a bit deeper than the Athlon 64 or Opteron. While the Opteron has a 12 stage pipeline for integer calculations, the 970FX goes deeper and ends up with 16 stages. Floating point is handled through 21 stages, and the Opteron only needs 17. 21 stages might make you think that the 970FX is close to a Pentium 4 Northwood, but you should remember that the Pentium 4 also had 8 stages in front of the trace cache. The 20 stages were counted from the trace cache. So, the Pentium 4 has to do less work in those 20 stages than what the 970FX performs in those 16 or 21 stages. When it comes to branch prediction penalties, the 970FX penalty will be closer to the Pentium 4 (Northwood). But when it comes to frequency headroom, the 970FX should do - in theory - better than the Opteron, but does not come close to the "old" Pentium 4.
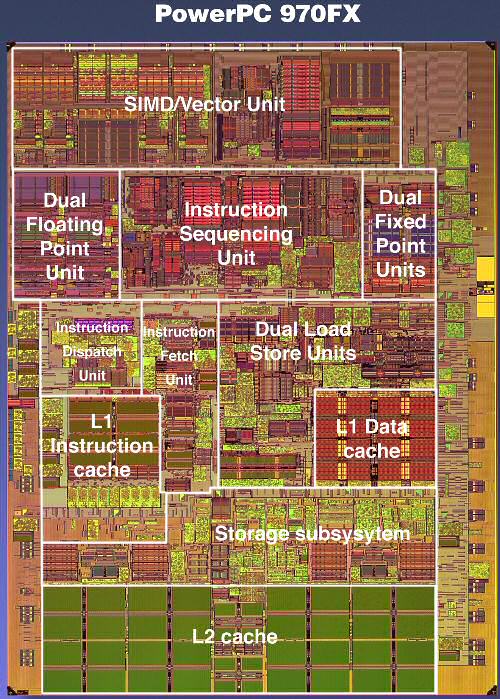
The 970FX works out of order and up to 200 instructions can be kept in flight, compared to 126 in the Pentium 4. The rate at which instructions are fetched will not limit the issue rate either. The PowerPC 970 FX fetches up to 8 instructions per cycle from the L1 and can decode at the same rate of 8 instructions per cycle. So, is the 970FX the ultimate out-of-order CPU?
While 200 instructions in flight are impressive, there is a catch. If there was no limitation except die size, CPUs would probably keep thousands of instructions in flight. However, the scheduler has to be able to pick out independent instructions (instructions that do not rely on the outcome of a previous one) out of those buffers. And searching and analysing the buffers takes time, and time is very limited at clock speeds of 2.5 GHz and more. Although it is true that the bigger the buffers, the better, the number of instructions that can be tracked and analysed per clock cycle is very limited. The buffer in front of the execution units is about 100 instructions big, still respectable compared to the Athlon 64's reorder buffer of 72 instructions, divided into 24 groups of 3 instructions.
The same grouping also happens on the 970FX or G5. But the grouping is a little coarser here, with 5 instructions in one group. This grouping makes reordering and tracking a little easier than when the scheduler would have to deal with 100 separate instructions.
The grouping is, at the same time, one of the biggest disadvantages. Yes, the Itanium also works with groups, but there the compilers should help the CPU with getting the slots filled. In the 970FX, the group must be assembled with pretty strict limitations, such as at one branch per group. Many other restrictions apply, but that is outside the scope of this article. Suffice it to say that it happens quite a lot that a few of the operations in the group consist of NOOP, no-operation, or useless "do nothing" instructions. Or that a group cannot be issued because some of the resources that one member of the group needs is not available ( registers, execution slots). You could say that the whole grouping thing makes the Superscalar monster less flexible.
Branch prediction is done by two different methods each with a gigantic 16K entry history table. A third "selector" keeps another 16K history to see which of the two methods has done the best job so far. Branch prediction seems to be a prime concern for the IBM designers.
Memory Subsystem
The caches are relatively small compared to the x86 competition. A 64 KB I-cache and 32 KB D-cache is relatively "normal", while the 512 KB L2-cache is a little small by today's standards. But, no complaints here. A real complaint can be lodged against the latency to the memory. Apple's own webpage talks about 135 ns access time to the RAM. Now, compare this to the 60 ns access time that the Opteron needs to access the RAM, and about 100-115 ns in the case of the Pentium 4 (with 875 chipset).A quick test with LM bench 2.04 confirms this:
| Host | OS | Mem read (MB/s) | Mem write (MB/s) | L2-cache latency (ns) | RAM Random Access (ns) |
| Xeon 3.06 GHz | Linux 2.4 | 1937 | 990 | 59.940 | 152.7 |
| G5 2.7 GHz | Darwin 8.1 | 2799 | 1575 | 49.190 | 303.4 |
| Xeon 3.6 GHz | Linux 2.6 | 3881 | 1669 | 78.380 | 153.4 |
| Opteron 850 | Linux 2.6 | 1920 | 1468 | 50.530 | 133.2 |
Memory latency is definitely a problem on the G5.
On the flipside of the coin is the excellent FSB bandwidth. The G5/Power PC 970FX 2.7 GHz has a 1.35 GHz FSB (Full Duplex), capable of sending 10.8 GB/s in each direction. Of course, the (half duplex) dual channel DDR400 bus can only use 6.4 GB/s at most. Still, all this bandwidth can be put to good use with up to 8 data prefetch streams.








116 Comments
View All Comments
seanp789 - Saturday, June 4, 2005 - link
well thats great and all but yours news says apple is switchign to intel so i dont think much will be changing in the power pc lineupBrazilian Joe - Saturday, June 4, 2005 - link
I would like to see this Article re-done, with more benches to give a clearer picture. I think MACOS X should be pitched against Darwin in the PPC platform, since there may be hidden differences. Darwin works on x86 too (and x86_64?), it would be very interesting to see the SAME OS under the Mac Platform running on different hardware. And having the software compiled with the same compiler present on Darwin, we should get a more consistent result. Linux and BSD should not be ditched, however. The perfornance difference Of linux/FreeBSD/OpenBSD in PPC vs PC is also a very interesting subject to investigate.I think this article, along with all the complaints of inconsistency in the results, sohuld fuel a new series of articles: One, Just comparing Darwin/MacOS X on Both platforms. Another For Linux, using a GCC version as close as possible to that used on Darwin. Another for FreeBSD, and yet another for OpenBSD. The last article Would get everything and summarize. I think this would be much more complete and satisfying/informative for the reader crowd.
iljitsch - Saturday, June 4, 2005 - link
There seems to be considerable confusion between threads and processes in the review. I have no trouble believing that MacOS doesn't do so well with process gymnastics, but considering the way Apple itself leverages threads, I would assume those perform much better.I don't understand why Apache 1.3 was used here, Apache 2.0 has much better multiprocessor capabilities and would have allowed to test the difference between the request-are-handled-in-processes and requests-are-handled-in-threads ways of doing things.
Phil - Saturday, June 4, 2005 - link
#79: Wow. I had no idea that they were actually going to do it, I had assumed that it was typical industry nonsense!If this is true, then IMHO Apple won't be in much of a better position (with regards to this article) as they'll still need to work on the OS, regardless.
Can anyone speculate as to why they *really* want to switch to x86/Intel? I wonder if they'll consider AMD too...
rorsten - Saturday, June 4, 2005 - link
Uhm, the estimation for power consumption is completely wrong. The only significant CMOS power consumption - especially for an SOI chip - is the current required to charge or discharge the gates of the FETs, which only happens when a value changes (the clock accounts for most of the power consumption on a modern synchronous chip). Since we're talking about current only, this is purely resistive power, I^2R style, and since the current is related to the number of transitions per second, increasing the clock rate linearly increases the current which quadratically increases the power consumption.kamper - Saturday, June 4, 2005 - link
Here's another story about Apple and Intel from cnet:http://news.com.com/Apple+to+ditch+IBM%2C+switch+t...
Interesting in the context of this article but I won't believe it without much more substantial proof :)
+1 on getting a db test using the same os on all architectures whether it be linux or bsd
+1 on fixing the table so that it renders in firefox
shanep - Saturday, June 4, 2005 - link
Re: NetBSD.Sorry, I just noticed it is not supported yet by NetBSD.
Forget I mentioned it.
shanep - Saturday, June 4, 2005 - link
"Wessonality: Our next project if we can keep the G5 long enough in the labs."How about testing these machines with NetBSD 2.0.2 to keep the hardware comparison on as close an equal footing as possible.
This should mostly remove many red herrings associated with multiple differences in software across different hardware.
michaelok - Saturday, June 4, 2005 - link
"i've had for awhile about OS X server handling large numbers of thread. My OS X servers ALWAYS tank hard with lots of open sessions, so i keep them around only for emergencies. T"Moshe Bar (openMosix) has been an avid Mac follower for years, I see he has a few suggestions for OSX, including ditching the Mach so you can run FreeBSD natively, which has much better peformance. In fact, thread performance is one of FreeBSDs strong points, although Linux has largely caught up.
Also research his Byte articles, you can see how a proper comparison can be done, although he does not claim to be a benchmarking expert.
http://www.moshebar.com/tech/?q=node/5
http://www.byte.com/documents/s=7865/byt1064782374...
johannesrexx - Saturday, June 4, 2005 - link
Everybody should use Firefox by default because it's far more secure. Use IE only when you must.