SUN’s UltraSparc T1 - the Next Generation Server CPUs
by Johan De Gelas on December 29, 2005 10:03 AM EST- Posted in
- CPUs
Introduction
SUN's Ultrasparc T1, formerly known as Niagara, is much more than just a new UltraSparc. It is the harbinger of a new generation of CPUs, which focus almost solely on Thread Level Parallelism. No less than 32 independent parts of a different program (threads) can be "in flight" on the chip. It is SUN's first implementation of their Throughput computing philosophy, and compared to what we are used to in the AMD/Intel world, it is a pretty extreme architecture that focuses on network and server performance.
Stubborn Server applications
The basic idea behind the UltraSparc T1 is that most modern superscalar Out-Of-Order CPUs may be excellent for games, digital content creation and scientific calculations, but they are not a good match for commercial server loads.
These complex CPUs can decode up to 3 (Opteron) to 8 (Power 5) instructions in parallel, put in a buffer and try to issue them across 9 or more units. In theory, these CPUs can decode, issue, execute and retire up to 3 (Opteron) to 5 (IBM Power) instructions per clock cycle. They have huge buffers (up to 200 instructions) to keep many instructions in flight.
Server workloads, however, cannot make good use of all this parallelism for several reasons. The main reason is that commercial server loads move a lot of data around and perform relatively little calculation on that data. Moving a lot of data around means that you may need a lot of accesses to the memory, which results in many cycles wasted while the CPU has to wait for the data to arrive. As many different users query different parts of the database, caching cannot be as efficient (low locality of reference). In the past years, memory latency has become worse as memory speed increased a lot slower than the speed of the CPU. Memory latency is even worse on MP (Multi-Processor) systems, and has risen from a few tens of CPU cycles to 200-400 clock cycles. The second reason is that many of the calculations performed on that data involve data dependent (read: hard to predict) branches, which makes it even harder to do a lot in parallel.
You might counter these two problems by eliminating the branches through predication and incorporate very large caches. That is what the Itanium family does, but even the mighty Itanium is not capable of running those server loads at high speeds despite predication and gigantic caches. Below, you can see Intel's own numbers for CPU utilization on the 3 different workloads.
The applications that can be found inside Spec Integer benchmark are still rather compute-intensive compared to server applications. Compression, FPGA Circuit Placement and Routing, Compiling and interpreting, and computer visualization are representatives of very CPU intensive integer loads. On average, the best desktop CPUs such as the Athlon 64 or Intel Dothan are capable of sustaining 0.8 to 1 instructions per clock cycle in this benchmark, while the Pentium 4 is around 0.5-0.7 IPC. Itanium is capable of a 1.3-1.5 IPC. That may sound like very low numbers, but let us compare SpecInt with typical server loads. In the table below, you find how the 4-way superscalar USIIIi does on the various benchmarks.
Rather than focus on the absolute numbers, it is more important to note that web applications have 3 times less IPC than CPU intensive integer apps. OLTP databases (TPC-C) do even worse: the CPU sustains on average 0.2 instructions per clock pulse, or 4.5 less than SpecInt. These numbers are no different for the Opteron or Xeon. So despite Out of Order execution, nifty branch prediction schemes and big caches, commercial server loads utilize a very meagre 10 to 15% of the potential of modern CPUs.
One possible solution is to focus on clock speed instead of trying to process as many instructions in parallel (ILP, instruction level parallelism). The long pipelines of such CPUs make the branch prediction problem worse, and the power consumption goes up exponentially as we discussed in a previous article about dynamic power and power leakage.
SUN's Ultrasparc T1, formerly known as Niagara, is much more than just a new UltraSparc. It is the harbinger of a new generation of CPUs, which focus almost solely on Thread Level Parallelism. No less than 32 independent parts of a different program (threads) can be "in flight" on the chip. It is SUN's first implementation of their Throughput computing philosophy, and compared to what we are used to in the AMD/Intel world, it is a pretty extreme architecture that focuses on network and server performance.

Fig 1. The 2U SUN T2000
Stubborn Server applications
The basic idea behind the UltraSparc T1 is that most modern superscalar Out-Of-Order CPUs may be excellent for games, digital content creation and scientific calculations, but they are not a good match for commercial server loads.
These complex CPUs can decode up to 3 (Opteron) to 8 (Power 5) instructions in parallel, put in a buffer and try to issue them across 9 or more units. In theory, these CPUs can decode, issue, execute and retire up to 3 (Opteron) to 5 (IBM Power) instructions per clock cycle. They have huge buffers (up to 200 instructions) to keep many instructions in flight.
Server workloads, however, cannot make good use of all this parallelism for several reasons. The main reason is that commercial server loads move a lot of data around and perform relatively little calculation on that data. Moving a lot of data around means that you may need a lot of accesses to the memory, which results in many cycles wasted while the CPU has to wait for the data to arrive. As many different users query different parts of the database, caching cannot be as efficient (low locality of reference). In the past years, memory latency has become worse as memory speed increased a lot slower than the speed of the CPU. Memory latency is even worse on MP (Multi-Processor) systems, and has risen from a few tens of CPU cycles to 200-400 clock cycles. The second reason is that many of the calculations performed on that data involve data dependent (read: hard to predict) branches, which makes it even harder to do a lot in parallel.
You might counter these two problems by eliminating the branches through predication and incorporate very large caches. That is what the Itanium family does, but even the mighty Itanium is not capable of running those server loads at high speeds despite predication and gigantic caches. Below, you can see Intel's own numbers for CPU utilization on the 3 different workloads.
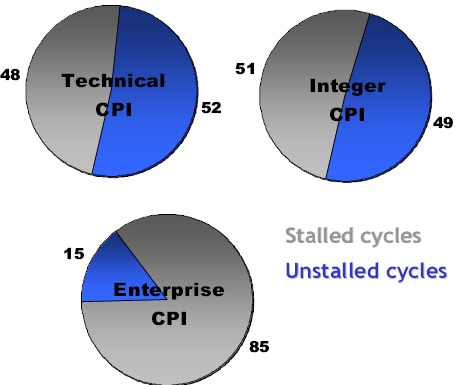
Fig 2: Intel reporting the percentage of stalled cycles of different applications on the Itanium 2 family. Source:Intel.
The applications that can be found inside Spec Integer benchmark are still rather compute-intensive compared to server applications. Compression, FPGA Circuit Placement and Routing, Compiling and interpreting, and computer visualization are representatives of very CPU intensive integer loads. On average, the best desktop CPUs such as the Athlon 64 or Intel Dothan are capable of sustaining 0.8 to 1 instructions per clock cycle in this benchmark, while the Pentium 4 is around 0.5-0.7 IPC. Itanium is capable of a 1.3-1.5 IPC. That may sound like very low numbers, but let us compare SpecInt with typical server loads. In the table below, you find how the 4-way superscalar USIIIi does on the various benchmarks.
| Benchmark | IPC |
| SPECint | 0.9 |
| SPECjbb | 0.5 |
| SPECweb | 0.3 |
| TPC-C | 0.2 |
Rather than focus on the absolute numbers, it is more important to note that web applications have 3 times less IPC than CPU intensive integer apps. OLTP databases (TPC-C) do even worse: the CPU sustains on average 0.2 instructions per clock pulse, or 4.5 less than SpecInt. These numbers are no different for the Opteron or Xeon. So despite Out of Order execution, nifty branch prediction schemes and big caches, commercial server loads utilize a very meagre 10 to 15% of the potential of modern CPUs.
One possible solution is to focus on clock speed instead of trying to process as many instructions in parallel (ILP, instruction level parallelism). The long pipelines of such CPUs make the branch prediction problem worse, and the power consumption goes up exponentially as we discussed in a previous article about dynamic power and power leakage.








49 Comments
View All Comments
Brian23 - Saturday, December 31, 2005 - link
While it's true that HT helps fight this issue, it's not the complete solution. Sun's approach is much better.Betwon - Thursday, December 29, 2005 - link
How terrible!The single issue pipeline/core!
Poeple always complains that: we fails to find the enough threads(2 or 4 threads) in the most apps for the multi-thread CPU.
Now, it is very difficult to find a app(8X4=32 threads parallel well).
Calin - Tuesday, January 3, 2006 - link
It is hard to find parallelism in one application so you could run it well on two cores. However, if you use 32 applications, you can run it very well on 32 cores.JarredWalton - Thursday, December 29, 2005 - link
Most servers don't run a lot of single-threaded apps, or if they do they run many instances of the single-threaded app/process at the same time. This is clearly not a chip designed for all markets, but it is instead focused on doing very well in a niche market.thesix - Thursday, December 29, 2005 - link
Johan,Nice article!
A small point: I don't think it's correct to refer Sun Microsystems Inc. as 'SUN', it should be 'Sun'.
Even though it originally stands for Standford University Network, 'SUN' is no longer the semi-official name, AFAIK.
When T1 based system is announced, I was hoping to see some independent benchmarks from Anandtech, especially the MySQL one you guys used to benchmark the server performance.
I know it's not scientific, and SPEC is as good as it gets, still I am curious :-)
Have you guys considered using T1000/T2000 to power Anandtech, given it's so cheap and designed for webserver type of workload?
That would be a good win-back story for Sun, I remembered you guys migraded from Sun Ultra boxes to PC server several years ago :-)
steveha - Thursday, December 29, 2005 - link
Why drop the opteron from the Specweb2005 results? Did it destroy the T1?stephenbrooks - Monday, January 2, 2006 - link
We think we should be told.NullSubroutine - Thursday, December 29, 2005 - link
How do these price? It seems the performance per watt is very good, but what if the cpu and the platform costs more?I might have missed it, but what was the die size?
icarus4586 - Thursday, December 29, 2005 - link
I'm assuming that should read,
I wouldn't guess Sun is using IBM technology or marketing terms.
JohanAnandtech - Thursday, December 29, 2005 - link
As thesix already commented (thanks :-), hypervisor is indeed IBM talk. AFAIK, IBM was first.