Quick update: more Interlagos testing
by Johan De Gelas on December 8, 2011 5:11 AM EST- Posted in
- IT Computing
- IT Computing general
- Cloud Computing
As promised in our last Opteron "Interlagos" review, we have been taking the time to deepen our understanding of AMD's newest Interlagos server platform and the "Bulldozer" architecture. Server reviewing remains a complex undertaking: some of the benchmarks take hours to set up and run, and power management policies, I/O subsystems and configuration settings can completely alter the outcome of a benchmark. That sounds very obvious right? It is not in practice.
Let me give you an example how subtle server benchmarking can be. One of the benchmarks missing in the original review was the MS SQL server benchmark, and for a reason. We did some extensive scaling benchmarks and our gut feeling told us that some of the results were a bit off the mark. So we kept the benchmark out of the original review until we pinpointed the problem.
Just a few days ago, we found out that a tiny bit of time-outs (1%, caused mostly by a data provider time out setting) can boost the results by about 20% erroneously as the actual workload is decreased. So our MS SQL server benchmark was not as accurate as we thought it was. Luckily we have solved all problems, and the benchmark is now more accurate than ever. You can expect to see the MS SQL server benchmarks on different server platforms and an in depth analysis in a forthcoming article.
While solving the MS SQL Server benchmark issues required a lot of testing, analysis and debate with Dieter, the lead developer of our stress testing tool vApus, we missed a more obvious tweak that could have improved our blender benchmarking. Luckily, we still have a community that is willing to give us valuable feedback. Greg Wereszko point out that our Blender benchmark cuts the render job up into only 64 tiles (X=8, Y=8). The result is that near the end of the test several cores are inactive, especially on the Interlagos Opteron (32 cores/threads).
So we increased the number of tiles beyond 8x8, to check if this improves performance on our 32 and 24 thread machines, and it did. (Quick note: the Blender benchmark on Windows is one of the worst benchmarks for the Opteron Interlagos, so see this as "worst case" performance point.)
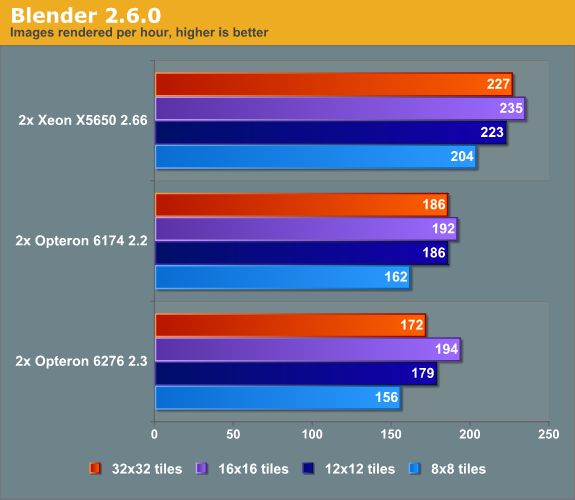
Instead of trailing behind the Opteron 6174, the Opteron "Interlagos" 6276 manages to perform a tiny bit better than its older sibling when we use 256 (16x16) tiles. The Opteron 6276 improves performance by 24%, the Xeon X5650 and Opteron 6174 by 19%.
Using more tiles, all CPUs are able to show their top performance. It also shows the rather "fragile performance profile" of the new Opteron. Many users are going to use standard settings and will never bother with this kind of tuning. As a result they are not going to use the full potential of the new Opteron. The Xeon's higher single-threaded performance makes it less vulnerable to less optimal software settings.
At the other side of the coin, once well tuned the Opteron 62xx offers an interesting performance per dollar ratio and this "fragile performance profile" may become very robust in FP intensive applications once the use of AVX gets widespread. We are taking quite a bit of time to make sure that the next server article can give more detailed information, but rest assured that we did not give up: we will update our server benchmarking...when it is finished.








30 Comments
View All Comments
twhittet - Thursday, December 8, 2011 - link
Has anyone seen any decent VMware benchmarks? This is the one place I was hoping Bulldozer architecture might end up being useful. I think Intel may have an advantage just because some software charges by # of cores per CPU socket, but AMD could still have a fighting chance otherwise.derbene - Thursday, December 8, 2011 - link
so testing servers means mostly rendering, a bit encryption, file archiver and VM to you? whats with real server benchmarks?take a look at these benchmarks:
http://www.tecchannel.de/server/prozessoren/203825...
bulldozer looks pretty brilliant compared to xeon there.
ender8282 - Thursday, December 8, 2011 - link
All a saw there was a single performance/watt benchmark. That is useful but this is a server processor not a SOC for a smartphone.derbene - Thursday, December 8, 2011 - link
then you should try to see better"Alle Diagramme"
or << >>
JohanAnandtech - Friday, December 9, 2011 - link
None of those benchmarks really covers a large part of the market: Specjbb based benchmarks only cover java benches that are very light on I/O, and that is a very small part of the market.SpecInt is hardly relevant either for the server market: it is a combination of HPC, video and game related benchmarks. And it runs all those instances with separate data in parallel.
We tried out two virtualization benchmarks with real world workloads, as used in real enterprises. Considering that most servers now ship with a hypervisor on top of them and I clearly indicated that the encryption and file archiving benchmarks carry less weight, I think your comment contains little constructive critism.
And didn't I indicate that we are working on extensive MS SQL Server 2008 benchmarks?
derbene - Friday, December 9, 2011 - link
i see, what you want to say. they all cover only a small part of the market... but all together they give you a hint. i dont understand, why you tested 4 different rendering benchmarks (cinebench, 3dsmax, maxwell render and blender as well). dont they have similar load-characteristics? how big should the market for this be? 50%?ashrafi - Thursday, December 8, 2011 - link
I was wondering if a quad opteron ( or even dual opteron ) 6174 setup benefit MAYA or 3Ds MAx rendering , if cpu rendering is considered there should be enough horse power in such a setup but i am not sure if Maya or 3ds max would even support as many cores.Any experience or ideas?
Drizzt321 - Thursday, December 8, 2011 - link
Single server benchmarks are great, and can be extremely valuable, but how about benchmarking clusters of servers? For me, Hadoop/Hbase would be ideal, but anything that clusters and spreads out the load across multiple machines could be interesting. I suppose you could say doing it all on 1 machine can give you an idea of performance, but it doesn't necessarily really stress absolutely every part of a system, since the network I/O is limited (usually), and the behavior of a cluster on >1 machine can be different than on a cluster of just 1 machine.kallestar - Friday, December 9, 2011 - link
"may become very robust in FP intensive applications once the use of AVX gets widespread"This is very unlikely, given how constrained the Bulldozer cores are with the shared floating point unit. If they can't cope currently with SSE instructions (4 32-bit floats) per cycle, how are they going to cope with the 8 that AVX use?
shodanshok - Sunday, December 11, 2011 - link
Great work Johan, it will be very interesting to see the complete benchmark results.Regarding the FPU, Bulldozzer can be more competitive with the use of XOP/FMAC instructions, but with "simple" AVX I didn't expect particular high gains (as a 256 bit AVX instructions is split into 2x128 bit macro operations).
Obviously some operations will be faster as AVX semanthic and functionality are better than existing SSE instructions, but this is true also for Intel's AVX implementation.