GTC 2012 Part 1: NVIDIA Announces GK104 Based Tesla K10, GK110 Based Tesla K20
by Ryan Smith on May 17, 2012 3:15 AM ESTThe other Tesla announced this week is Tesla K20, which is the first and so far only product announced that will be using GK110. Tesla K20 is not expected to ship until October-November of this year due to the fact that GK110 is still a work in progress, but since NVIDIA is once again briefing developers of the new capabilities of their leading compute GPU well ahead of time there’s little reason not to announce the card, particularly since they haven’t attached any solid specifications to it beyond the fact that it will be composed of a single GK110 GPU.

GK110 itself is a bit of a complex beast that we’ll get into more detail about later this week, but for now we’ll quickly touch upon some of the features that make GK110 the true successor to GF110. First and foremost of course, GK110 has all the missing features that GK104 lacked – ECC cache protection, high double precision performance, a wide memory bus, and of course a whole lot of CUDA Cores. Because GK110 is still in the lab NVIDIA doesn’t know what will be viable to ship later this year, but as it stands they’re expecting triple the double precision performance of Tesla M2090, with this varying some based on viable clockspeeds and how many functional units they can ship enabled. Single precision performance should also be very good, but depending on the application there’s a decent chance that K10 could beat K20, at least in the type of applications that are well suited for GK104’s limitations.
As it stands a complete GK110 is composed of 15 SMXes – note that these are similar but not identical to GK104 SMXes – bound to 1.5MB of L2 cache and a 384bit memory bus. GK110 SMXes will contain 192 CUDA cores (just like GK104), but deviating from GK104 they will contain 64 CUDA FP64 cores (up from 8, which combined with the much larger SMX count is what will make K20 so much more powerful at double precision math than K10. Of interesting note, NVIDIA is keeping the superscalar dispatch method that we first saw in GF104 and carried over to GK104, so unlike Fermi Tesla products, compute performance on K20 is going to be a little more erratic as a result of the fact that maximizing SMX utilization will require a high degree of both TLP and ILP.

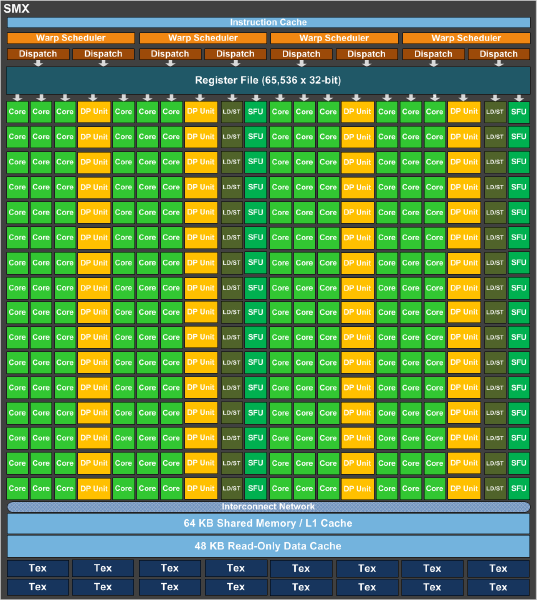
Along with the slew of new features native to the Kepler family and some new Kepler family compute instructions being unlocked with CUDA 5, GK110/K20 will be bringing with it two major new features that are unique to just GK110: Hyper-Q and Dynamic Parallelism. We’ll go over both of these in depth in the near future with our look at GK110, but for the time being we’ll quickly touch on what each of them does.
Hyper-Q is NVIDIA’s name for the expansion of the number of work queues in the GPU. With Fermi NVIDIA’s hardware only supported 1 hardware work queue, whereas GK110 will support 32 work queues. The important fact to take away from this is that 1 work queue meant that Fermi could be under occupied at times (that is, hardware units were left without work to do) if there wasn’t enough work in that queue to fill every SM, even with parallel kernels in play. By having 32 work queues to select from, GK110 can in many circumstances achieve higher utilization by being able to put different program streams on what would otherwise be an idle SMX.


The other major new feature here was Dynamic Parallelism, which is NVIDIA’s name for the ability for kernels to be able to dispatch other kernels. With Fermi only the CPU could dispatch a new kernel, which incurs a certain amount of overhead by having to communicate back and forth with the CPU. By giving kernels the ability to dispatch their own child kernels, GK110 can both save time by not having to go back to the GPU, and in the process free up the CPU to work on other tasks.
Wrapping things up, there are a few other features new to GK110 such as a new grid management unit, RDMA, and a new ISA encoding scheme, all of which are intended to further improve NVIDIA’s compute performance, both over Fermi and even GK104. But we’ll save these for another day when we look at GK110 in depth.








51 Comments
View All Comments
PsiAmp - Saturday, May 19, 2012 - link
K10 and GTX 680 share the same chip. So DP in K10 is terrible.belmare - Friday, August 3, 2012 - link
Mmmm, I thought they said that you'd be getting 3x the power efficiency of Fermi. M2090 had 660GFLOPS so it should follow that it gets somewhere around 1.9TFLOPS.Also, it wouldn't be much competition for the 7970GE which takes 1TFLOPS of DP, especially for a die this large. 550 square mm is enormous and the K20 should pay it back in huge performance gains.
We might be able to get a 780 next year at close to the same FLOPS-age, just so it's able to compete with the next year GCN.
Kepler might be the first to not cap SP or DP. However, I think this is just part of the plan to drop Maxwell tortuously and rip GPGPU at the seams.
wiyosaya - Thursday, May 17, 2012 - link
IMHO, I think this might be a losing bet for NVIDIA as Kepler is taking DP performance away from everyone, and, HPC computing power away from enthusiasts on a budget. IMHO, they are walking the Compaq, HP, and Apple line now with overpriced products in the compute area. As DP is important to me, I just bought a 580 rather than a 680. I'll wait for benchmarks on this card, however, as an enthusiast on a budget looking for the best value for the money, I'll be passing on this card.Perhaps NVIDIA is trying to counter the last gen situations where Tesla cards performed about as well, and sometimes not even as well, as the equivalent gaming card, and the Tesla 'performance' came at an extreme premium. The gamer cards were a far better value than the Tesla cards for compute performance in general.
I wish NVIDIA luck in this venture. There are not many public distributed computing projects out there that need DP support, however, for those projects, NVIDIA may be driving business to AMD - which presently has far superior DP performance. I think this is an instance where NVIDIA is definitely making a business decision to move in this direction; I hope it works out for them, or if it fails, I hope that they come to their senses. $2,500 is an expensive card no matter how you look at it, and the fact that they are courting oil and gas exploration is an indication that they are after the $$$.
Parhel - Thursday, May 17, 2012 - link
There are plenty of products on the market that are for the professional rather than the "enthusiast on a budget."I have a professional photographer friend who recently showed me a lens that he paid over $5,000 for. Now, I like cameras a lot, and have since I was a kid. And, I'm willing to spend more on them than most people do. But I'm an enthusiast on a budget when it comes to cameras. As much as I'd love to own that lens, that product clearly wasn't designed for me.
Good for nVidia if they can design a card that oil and gas companies are willing to pay crazy money for. In the end, nVidia being "after the $$$" is the best thing for us mere enthusiasts.
SamuelFigueroa - Thursday, May 17, 2012 - link
Unlike gamer cards, Tesla cards have to work reliably 24x7 for months on end, and companies that buy them need to be able to trust the results of their computations without resorting to running their weeks-long computation again just in case.By the way, did you notice that K10 does not have an integrated fan? So even if you had the money to buy one, it wouldn't work in your enthusiast computer case.
Dribble - Thursday, May 17, 2012 - link
Last gen was exactly the same - the GF104 had weak floating point performance too. The only differences so far is that nvidia haven't released the high end GK110 as a gaming chip yet, and due to the GK104 being so fast in comparison to ati's cards they called it the 680, not the 660 (which they would have if ati had been faster).I'm sure they will release a GK110 to gamers in the end - probably call it the 780, and rebrand the 680 as a 760.
chizow - Thursday, May 17, 2012 - link
Exactly, the poor DP performance of GK104 just further drives the point home it was never meant to be the flagship ASIC for this generation of Kepler GPUs. Its obvious now GK110 was mean to be the true successor to GF100/110 and the rest of Nvidia's lineage of true flagship ASICs (G80, GT200, GT200b etc.)CeriseCogburn - Saturday, May 19, 2012 - link
What is obvious and drives the very point not made home without question is amd cards suck so badly nVidia has a whole other top tier they could have added on long ago now, right ?ROFL - you've said so, many times, nVidia is a massive king on performance right now, and since before the 680 release, so much extra gaming performance up their sleeve already, amd should be ashamed of itself.
This is what you've delivered, while you little attacking know it alls pretend amd is absolutely coreless and cardless in the near future, hence you can blame the release level on nVidia, while ignoring the failure company amd, right ?
As amd "silently guards" any chip it may have designed or has in test production right now, all your energies can be focused on attacking nVidia, while all of you carelessly pretend amd gaming chips for tomorrow don't exist at all.
I find that very interesting.
I find the glaring omission that is now standard practice quite telling.
Impulses - Thursday, May 17, 2012 - link
I'll happy buy a 680/760 for $300 or less when/if that happens... :p Upgrading my dual 6950s in CF (which cost me like $450 for both) to anything but an $800+ SLI/CF setup right now would just be a sidegrade at best, so I'll probably just skip this gen.CeriseCogburn - Wednesday, May 23, 2012 - link
All that yet you state you just bought an nVidia GTX 580.ROFL
BTW, amd is losing it's proprietay openCL Winzip compute benchmarks to Ivy Bridge cpu's.
Kepler GK110 is now displayig true innovation and the kind of engineering amd can only dream of - with 32 cpu calls available instead of 1 - and it also sends commands to other Keplers to keep them working.
Obviously amd just lost their entire top end in compute - it's over.