Four Multi-GPU Z77 Boards from $280-$350 - PLX PEX 8747 featuring Gigabyte, ASRock, ECS and EVGA
by Ian Cutress on August 22, 2012 9:15 AM ESTWith only sixteen PCIe 3.0 lanes available on a Z77 motherboard paired with an Ivy Bridge CPU, when we get to three or four-way GPU solutions these GPUs are itching to get more bandwidth. The Z77 specification limits us to three GPUs anyway, at x8/x4/x4. For some extra cost on the motherboard, we can add in a PLX PEX 8747 chip that effectively increases our PCIe 3.0 lane count, giving 32 PCIe 3.0 lanes overall. Today we discuss this technology, and look at four motherboards on sale today that utilize this PLX chip - the Gigabyte G1.Sniper 3, the ASRock Z77 Extreme9, the ECS Z77H2-AX and the EVGA Z77 FTW.
Multi-GPU on Z77
Aiming for users for 3-way and 4-way GPU setups is aiming for a very niche sub-section of an enthusiast crowd. Here we are pinpointing those that have the hard cash to create a very nice system, capable of powering several large monitors at high resolution for fast paced and detailed gaming. Many of these setups are bespoke, specifically designed in modded cases, and a good number use water-cooling to get around the generation of heat. Let us not forget the power draw, with multiple GPU setups requiring significant power supplies or even a dual power supply solution. It gets even worse if everything is overclocked as well.
These users often keep up to date with the latest and greatest hardware. No processor, no graphics card and no chipset is too new for them. If any of our enthusiasts here were asked about which platform would be best for a multi-GPU setup, we would respond with X79 and Sandy Bridge-E, should money be no object. Even for high throughput users, such as scientific simulators or video editing - Sandy Bridge-E holds all the performance. There is one thing Sandy Bridge-E lacks though - PCIe bandwidth.
With the majority of X79 stuck in PCIe 2.0 land, we start to hit bottlenecks transferring data between memory and GPU. Our limit is 8 GB/s for a full sixteen lane PCIe 2.0 port. If we jump into Z77 and Ivy Bridge, we have PCIe 3.0. For a full sixteen lane PCIe 3.0 port, we have double the bandwidth at 16 GB/s.
The other issue is lanes - X79 and SBE have 40 PCIe 2.0 lanes to distribute, giving x16/x8/x8/x8 in a four-way GPU scenario. Even with double the bandwidth per lane of PCIe 3.0, Z77 and Ivy Bridge can only play around with sixteen lanes in total, as shown by the chipset diagram:
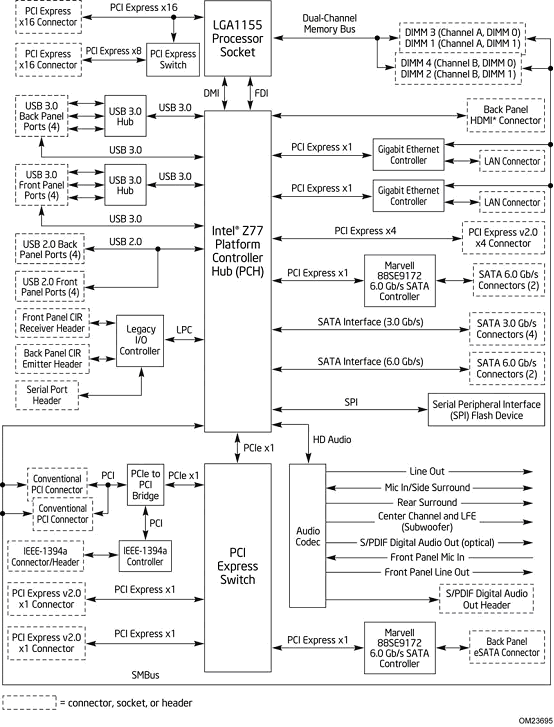
The Z77 specification states that these lanes can be split in any of the following ways:
| PCIe Layout Comparison Chart | |||||
| Configuration | GPUs | GPU 1 | GPU 2 | GPU 3 | GPU 4 |
| 1 | 1 | 16x PCIe 3.0 | - | - | - |
| 2 | 2 | 8x PCIe 3.0 | 8x PCIe 3.0 | - | - |
| 3 | 2 | 16x PCIe 3.0 | 4x PCIe 2.0 | - | - |
| 4 | 3 | 8x PCIe 3.0 | 4x PCIe 3.0 | 4x PCIe 3.0 | - |
| 5 | 3 | 8x PCIe 3.0 | 8x PCIe 3.0 | 4x PCIe 2.0 | - |
| 6 | 4 | 8x PCIe 3.0 | 4x PCIe 3.0 | 4x PCIe 3.0 | 4x PCIe 2.0 |
For many of these setups, motherboard manufacturers can also choose to direct four of the PCIe 2.0 lanes from the chipset to also aid with CrossFire scenarios (SLI is not certified in this configuration). The downside of this comes from the limited bandwidth of the PCIe 2.0 lanes, which have half the bandwidth of the PCIe 3.0 lanes, but there is also added latency of navigating data through the chipset rather than across the PCIe bus.
For mini-ITX solutions, we will see the one GPU scenario. For many microATX solutions, one of the dual GPU scenarios will dominate. In full ATX mode, manufacturers have all the configurations listed above to choose from. Luckily, here at AnandTech, we have reviewed the majority of the configurations (1, 2, 4 and 5) in the table above in order to provide comparison points.
Back in the days of X58 and P55, when PCIe 2.0 dominated the landscape, certain motherboards contained a special chip called an NF200. This was a PCIe switch that allowed the motherboard to double its quota of PCIe 2.0 lanes from 16 to 32, which could then be arranged appropriately. The downsides of using this chip were that it added cost to the board, it drew more power, and there was some slight processing overhead from using it. However, if it allowed full bandwidth to a second GPU and increased FPS by 40%, then a small ~1-3% deficit on top was not worried about.
Fast forward a few years and we have another chip on the market, this time doing exactly the same thing with PCIe 3.0 lanes. This chip is the PEX 8747, designed by the company PLX (you may see it referred to as a PLX PEX 8747 or a PLX 8747). It offers PCI Express switching capability, giving motherboard manufacturers 32 PCIe 3.0 lanes to play with. This allows the following combinations:
| PCIe Layout Comparison Chart | ||||||
| Configuration | GPUs | PEX 8747 | GPU 1 | GPU 2 | GPU 3 | GPU 4 |
| 7 | 1 | Y | 16x PCIe 3.0 | - | - | - |
| 8 | 2 | Y | 16x PCIe 3.0 | 16x PCIe 3.0 | - | - |
| 9 | 3 | Y | 16x PCIe 3.0 | 16x PCIe 3.0 | 4x PCIe 2.0 | - |
| 10 | 3 | Y | 16x PCIe 3.0 | 8x PCIe 3.0 | 8x PCIe 3.0 | - |
| 11 | 4 | Y | 16x PCIe 3.0 | 8x PCIe 3.0 | 8x PCIe 3.0 | 4x PCIe 2.0 |
| 12 | 4 | Y | 8x PCIe 3.0 | 8x PCIe 3.0 | 8x PCIe 3.0 | 8x PCIe 3.0 |
In reality, configuration 8 may be selected on micro-ATX sized boards, and configurations 10 and 12 will be applied to ATX boards. The rest are not likely to be on a product in market.
Now we have a direct competitor to the 40 PCIe 2.0 lanes of X79, in that we have 32 PCIe 3.0 lanes - equivalent to 64 PCIe 2.0 lanes (or x16/x16/x16/x16 on PCIe 2.0).
How Does a PCI Express Switch (like the PEX 8747) Work
The key confusion surrounding devices such as the PEX 8747 is that no matter how many lanes there are to be seen by the CPU, the CPU still only has 16 lanes for data travel. Data is always limited by this bottleneck, so how do we get more lanes? I see many posts of forums saying 'well it multiplies it by two', but that is not a proper answer.
When searching for data on the PEX 8747, or the NF200, there is a lot of forum talk and not a lot of technical information. The PLX website hosts some high-level information, and low-level technical data is under NDA. Thus, what we write here is from what I have discussed with technical minded colleagues, and potentially does not represent the true actions of the PEX 8747.
The heart of the PLX chip is how it manages the data between the CPU and the PCIe slots. It does this through multiplexing, or the art of dealing with multiple signals wanting to travel through one point. We already deal with multiplexing on some motherboards with respect to the power delivery. Here are some basic examples of multiplexing:
Signal multiplexing: Combining multiple analogue signals into a single signal. This signal can then be optimized for high speed travel. The single signal is then de-multiplexed (de-muxed) at the other end to extract the original data. This is performed on a large scale with telecommunications.
Time-division multiplexing: Instead of installing several fast connects between two points that have multiple users at each end, one line is installed and this line switches between each of the pairs of users such that the signal is not inadvertently disrupted. This gif from the Wikipedia helps describe this scenario:
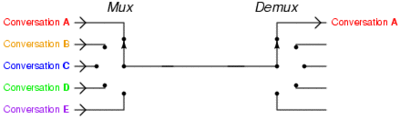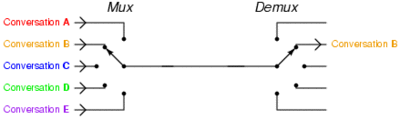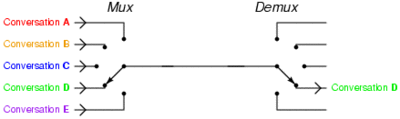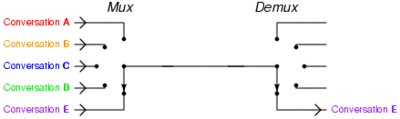
So what does the PLX chip do on a motherboard? Our best reasoning is that it acts as a data multiplexer with a buffer that organizes a first in, first out (FIFO) data policy for the connected GPUs. Let us take the simplest case, where the PLX chip is powering two GPUs, both at ‘x16’. The GPUs are both connected to 16 lanes each to the PLX chip.
The PLX chip, in hardware, allows the CPU and memory to access the physical addresses of both GPUs. Data is sent to the first GPU only at the bandwidth of 16 lanes. The PLX chip recognizes this, and diverts all the data to the first GPU. The CPU then sends data from memory to the second GPU, and the PLX changes all the lanes to work with the second GPU.
Now let us take the situation where data is needed to be sent to each GPU asynchronously (or at the same time). The CPU can only send this data to the PLX at the bandwidth of 16 lanes, perhaps either weighted to the master/first GPU, or divided equally (or proportionally how the PLX tells the CPU at the hardware level). The PLX chip will then divert the correct proportion of lanes to each GPU. If one GPU requires less bandwidth, then more lanes are diverted to the other GPU.
This ultimately means that in the two-card scenario, at peak throughput, we are still limited to x8/x8. However, in the situation when only one GPU needs the data, it can assign all 16 lanes to that GPU. If the data is traveling upstream from the GPU to the CPU, the PLX can fill its buffer at full x16 speed from each GPU, and at the same time send as much of the data up to the CPU in a continuous stream at x16, rather than switching between the GPUs which could add latency.
This is advantageous – without a PLX chip, the GPUs have a fixed lane count that is modified only by a simple switch when other cards are added. This means in a normal x8/x8 setup that if data is needed by one GPU, the bandwidth is limited to those eight lanes at maximum.
With all this data transference (and that should data be going the other way to memory then the PLX chip will have to have a buffer in order to prevent data loss) the PEX introduces a latency to the process. This is a combination of the extra routing and the action of the PEX to adjust ‘on-the-fly’ as required. According to the PLX documentation, this is in the region of 100 nanoseconds and is combined with large packet memory.
Back in the days of the NF200, we experienced a 1-3% overhead in like-for-like comparisons in many of our game testing. The PEX 8747 chip attempts to promise a reduction in this overhead, especially as it only comes into play in extreme circumstances. The situation is more complex in different circumstances (x16/x8/x8).
Take for example one of the boards we will review - the Gigabyte G1.Sniper 3. Gigabyte on this board chooses to route all the 16 PCIe 3.0 lanes from the CPU into the PLX PEX 8747 chip, and distribute them accordingly:

From this diagram alone, we can see that the PEX 8747 chip directs 16 PCIe 3.0 lanes to one PCIe slot and 16 to another slot. Should cards be entered in the PCIe slots underneath these primary cards, then the sixteen lanes will be split by the switch into x8/x8 accordingly. The PEX 8747 then decides how to distribute the bandwidth given these lane options and prioritized data through multiplexing and the FIFO buffer contained on chip. The downside of this comes with a single GPU setup, whereby the added latency and routing caused by the PLX chip can reduce single card performance.
One other option with lane routing is to split the lanes from the CPU. As we will see on the EVGA Z77 FTW in a later review, eight PCIe 3.0 lanes can be directed to the first PCIe slot, and the other eight PCIe 3.0 lanes can be sent to the PLX PEX 8747 chip. This solution uses the 32 lane output to populate other PCIe slots in the following manner:
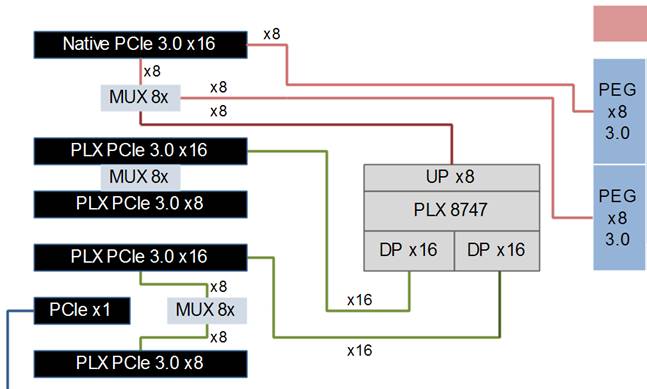
Many thanks to EVGA for the diagram
In this lineup, the CPU provides eight PCIe 3.0 lanes to the first PCIe slot, and the other eight lanes to a multiplexer that either directs the lanes to the first PCIe, or the PEX 8747 chip. The eight upstream lanes in the PLX chip are organized into 32 downstream lanes, which are sent 16 each to the second PCIe x16 slot and the fourth PCIe x16 slot. Those 16 lanes are each shared with the slot directly below.
What this means is that the second, third and fourth PCIe lanes, even if they are rated ‘x16’, are limited by the eight lanes upstream from the PLX. While the chip can handle multiple inputs and outputs, that eight lane restriction to the CPU could become an issue. EVGA tell us that their configuration gives better single and dual GPU performance than other manufacturers. Most GPU communication is between GPUs through SLI fingers which is not effected by the 8 lanes upstream, and the PLX chip is clever enough to shut down parts it doesn’t need depending on the configuration, saving power.
This allows for the following configurations:
| PCIe Layout Comparison Chart | ||||||
| Configuration | GPUs | PEX 8747 | GPU 1 | GPU 2 | GPU 3 | GPU 4 |
| 13 | 1 | Y |
16x 8x from CPU 8x via MUX |
- | - | - |
| 14 | 2 | Y | 8x from CPU | - | 16x from PLX | - |
| 15 | 2 | Y | - | 16x from PLX | 16x from PLX | - |
| 16 | 3 | Y | 8x from CPU | 16x from PLX | 16x from PLX | - |
| 17 | 4 | Y | 8x from CPU | 16x from PLX | 8x from PLX | 8x from PLX |
The differences between configurations 14 and 15 should be explained. While configuration 15 has a total of 16 lanes per GPU on average, if we refer back to the diagram above, these GPUs are limited to the CPU by the 8 lanes upstream from the PLX. By placing the GPUs in configuration 14, we are minimizing latency to the CPU for the first GPU while giving each GPU a maximum of 8 lanes each direct to the CPU (even if they are through the PLX for the second GPU).
Yes, using a PLX PEX 8747 chip makes understanding how the lanes work on a motherboard very confusing. No longer can these motherboards really represent what is going on by quoting electrical lane connections. But alas, that is the only way to report them in marketing and PR.
If a manufacturer really wanted to push the limits, they could add multiple PEX 8747 chips to the motherboard. We will see this on the ASRock X79 Extreme11 in a future review, as they take 32 lanes from the Sandy Bridge-E GPU and use the PLX chip to produce 64 lanes, giving a peak of x16/x16/x16/x16 bandwidth. (The other eight lanes seem to be directed to an LSI SAS RAID chip - we will investigate this when we review the motherboard.)
But onward to the motherboard reviews – the first up is the Gigabyte G1.Sniper 3.








24 Comments
View All Comments
goinginstyle - Thursday, August 23, 2012 - link
I tried the G1 Sniper 3 and returned it a few days later. The audio was a significant downgrade from the Assassin series, EFI is clunky at best and the board had serious problems with a GSKill 16GB 2666 kit, not to mention the lousy fan controls.Purchased a Maximus Formula V and never looked back as the EFI, Fan Controls, Clocking and Audio are much better in every way compared to the Sniper board. There is no way Gigabyte has brought better value than ASUS with the Z77 chipset. You get what you pay for and the GB is overpriced once you actually use the board and compare it to ASUS or even ASRock.
JohnBS - Thursday, November 1, 2012 - link
I am looking for a rock solid MB, so of course I turned to ASUS. However, the reviews from verified buyers showed multiple issues with 3.0 USB ports losing power, system instability after months of use, and multiple instances of the board not working in one or more memory slots. Bent pins from the factory and complete DOA issues as well. A few reports of complete failure when the Wi-Fi card was inserted, yet gone with the card removed. This was mainly the Maximus IV series. Then I thought I'd look into the Maximus V series, because I really wanted ASUS, and was kinda sad to read reviews. Same issues from verified buyers of the Maximus V, more so with the USB 3.0 problems and the Wi-Fi/Bluetooth add-on card failures. In common were multiple complaints about customer service.So I emailed the ASUS rep who was replying to everyone's post, with specific attention on the recurring problems and how I was concerned about buying a MB. I got the email back, stating they were aware of the recurring problems listed on the user reviews, but that they are isolated occurrences.
I really need a rock solid x16 x 2 pci-e mb right now, and that's why I'm still searching. I'm planning on overclocking an i7-2700k with an gtx 690 and a 120z monitor for high res gaming. The sniper 3 looks good, but the front audio plug reaching the board's bottom audio header might be something I can't work around.
Just want something reliable. If there's a known issue, I'm always in that percentile that gets hit with the RMA process. I'm trying so hard to avoid that.
(Went with 690 instead of dual 680 for heat, noise, power draw considerations).
jonjonjonj - Friday, October 26, 2012 - link
you mean gigabyte in the evga conclusion?"the EVGA does not keep pace with ASUS and EVGA even at stock speeds."
couchassault9001 - Friday, November 2, 2012 - link
So for gaming benchmarks is it correct that the cpu multipliers were at 40 on the g1.sniper and 36 on the evga? if so it seems to be a rather unfair comparison. Being that the sniper cpu is running 11% fasterI'd be amazed if someone was looking at these boards with no intent to overclock like crazy, as i'm trying to decide between these 2 boards myself, and i'm sure i'll be pushing my 3770k as far as it will go.
The evga consumed ~8% less power than the sniper under load.
dirt 3 showed a 9% frame rate drop in the frame rate going from g1 to evga. metro 2033 showed a 3.6% drop in frame rate going from g1 to evga. Both of these are on the 4 7970 benchmarks. the 3 and below the gap is much tighter with it being under 1% with one card.
I know this may be nit picking to some, but i plan on running 5760x1080 3d so 4 7970 performance on a i7-3770k is exactly what i'm looking at.