AMD's Steamroller Detailed: 3rd Generation Bulldozer Core
by Anand Lal Shimpi on August 28, 2012 4:39 PM EST- Posted in
- CPUs
- Bulldozer
- AMD
- Steamroller
Today at the annual Hot Chips conference, AMD’s new CTO Mark Papermaster unveiled the first details about the Steamroller x86 CPU core.
Steamroller is the third instantiation of AMD’s Bulldozer architecture, first conceived in the mid-2000s and finally brought to market in late 2011. Committed to this architecture for at least one more design after Steamroller, AMD has settled on roughly yearly updates to the architecture. For 2012 we have the introduction of Piledriver, the optimized Bulldozer derivative that formed the CPU foundation for AMD’s Trinity APU. By the end of the year we’ll also see a high-end desktop CPU without processor graphics based on Piledriver.
Piledriver saw a switch to hard edge flip flops, which allowed for a considerable decrease in power consumption at the expense of careful design and validation work. Performance didn’t change, but AMD saw a 10% - 20% reduction in active power. Piledriver also brought some scheduling efficiency improvements, but prefetching and branch prediction were the two other major design improvements in Piledriver.
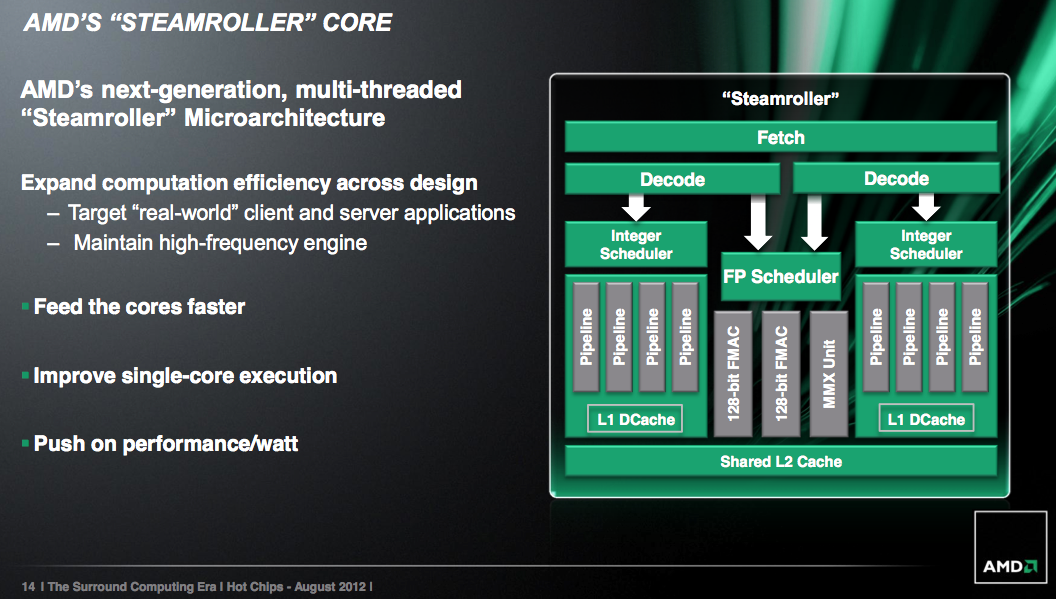
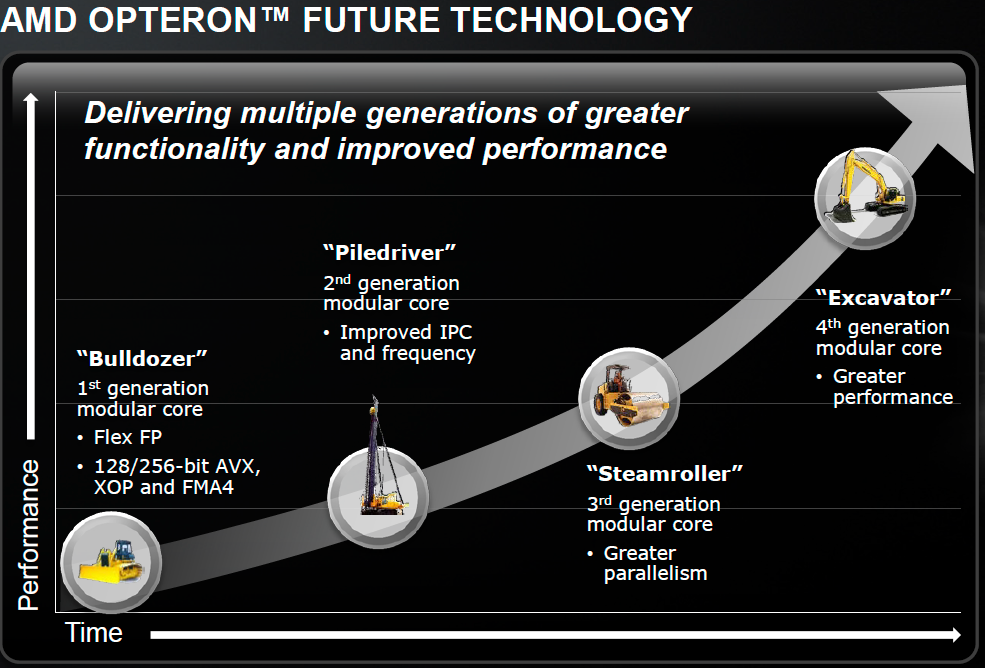
Steamroller is designed to keep the ball rolling. It takes fundamentals from the Bulldozer/Piledriver architectures and offers a healthy set of evolutionary improvements on top of them. In Intel speak Steamroller wouldn’t be a tick as it isn’t accompanied by a significant process change (28nm bulk is pretty close to 32nm SOI), but it’s not a tock as the architecture is mostly enhanced but largely unchanged. Steamroller fits somewhere in between those two extremes when it comes to changes.
Front End Improvements
One of the biggest issues with the front end of Bulldozer and Piledriver is the shared fetch and decode hardware. This table from our original Bulldozer review helps illustrate the problem:
| Front End Comparison | |||||
| AMD Phenom II | AMD FX | Intel Core i7 | |||
| Instruction Decode Width | 3-wide | 4-wide | 4-wide | ||
| Single Core Peak Decode Rate | 3 instructions | 4 instructions | 4 instructions | ||
| Dual Core Peak Decode Rate | 6 instructions | 4 instructions | 8 instructions | ||
| Quad Core Peak Decode Rate | 12 instructions | 8 instructions | 16 instructions | ||
| Six/Eight Core Peak Decode Rate | 18 instructions (6C) | 16 instructions | 24 instructions (6C) | ||
Steamroller addresses this by duplicating the decode hardware in each module. Now each core has its own 4-wide instruction decoder, and both decoders can operate in parallel rather than alternating every other cycle. Don’t expect a doubling of performance since it’s rare that a 4-issue front end sees anywhere near full utilization, but this is easily the single largest performance improvement from all of the changes in Steamroller.
The penalties are pretty obvious: area goes up as does power consumption. However the tradeoff is likely worth it, and both of these downsides can be offset in other areas of the design as you’ll soon see.

Steamroller inherits the perceptron branch predictor from Piledriver, but in an improved form for better performance (mostly in server workloads). The branch target buffer is also larger, which contributes to a reduction in mispredicted branches by up to 20%.
Execution Improvements
AMD streamlined the large, shared floating point unit in each Steamroller module. There’s no change in the execution capabilities of the FPU, but there’s a reduction in overall area. The MMX unit now shares some hardware with the 128-bit FMAC pipes. AMD wouldn’t offer too many specifics, just to say that the shared hardware only really applied for mutually exclusive MMX/FMA/FP operations and thus wouldn’t result in a performance penalty.
The reduction of pipeline resources is supposed to deliver the same throughput at lower power and area, basically a smarter implementation of the Bulldozer/Piledriver FPU.
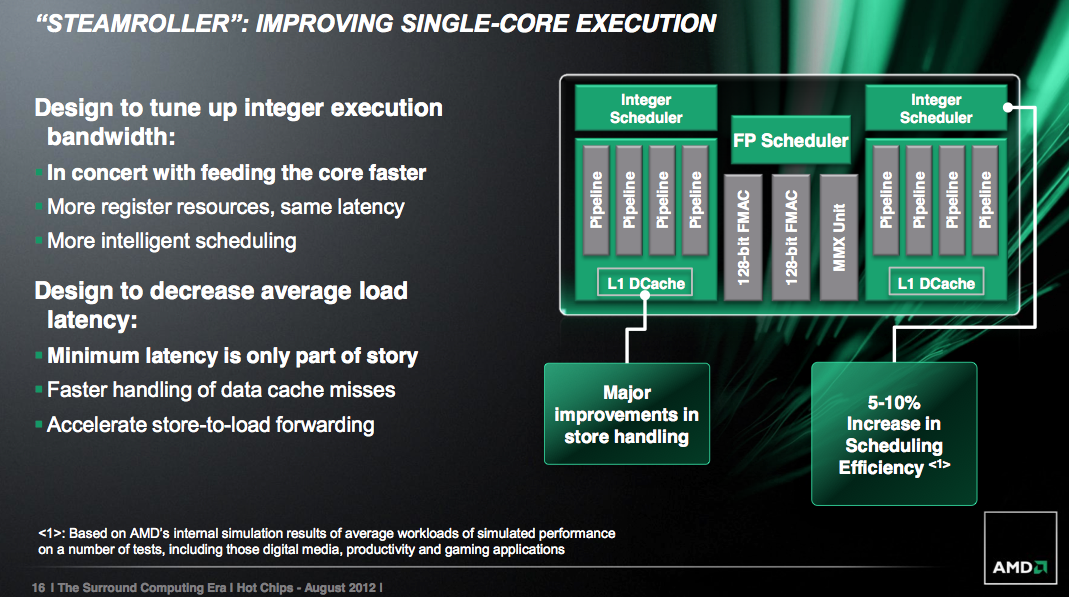
There’s no change to the integer execution units themselves, but there are other improvements that improve integer performance.
The integer and floating point register files are bigger in Steamroller, although AMD isn’t being specific about how much they’ve grown. Load operations (two operands) are also compressed so that they only take a single entry in the physical register file, which helps increase the effective size of each RF.
The scheduling windows also increased in size, which should enable greater utilization of existing execution resources.
Store to load forwarding sees an improvement. AMD is better at detecting interlocks, cancelling the load and getting data from the store in Steamroller than before.








126 Comments
View All Comments
AssBall - Wednesday, August 29, 2012 - link
You can run a 3.0 card on a 2.0 lane just fine. Dunno what you are talking about. And you can't even saturare a 2.0 x16 with a top end card, so what's the big deal?CeriseCogburn - Wednesday, August 29, 2012 - link
The big deal is amd is such an assball.Kiijibari - Tuesday, August 28, 2012 - link
Hi,I dont see how this:
"Now each core has its own 4-wide instruction decoder,"
and the statement of "+25% max-width dispatches per thread"
fit together. Seems a bit strange to have +100% Decode power if there is only +25% dispatch improvement.
DanNeely - Wednesday, August 29, 2012 - link
Read the footnote on the slide. The amount of hardware went up by 100%; the 25% number is the actual average throughput gain AMD saw in their testing. IOW ~25% of the time Bulldozer/Piledriver's shared decode maxed out in cases where a wider decode could have done more instructions at the same time.Southernsharky - Tuesday, August 28, 2012 - link
Well its not a great processor, but it does sound like AMD is putting some thought into it.They really need to hyper-evolve this Bulldozer junk and get something that is competitive out.
I'm still rolling along with my Phenom II 6 core, and it ain't bad really, even in basic gaming like League of Legends. But I imagine I'd be better off going Intel on my next rig. I'll still take a look at Excavator when it comes out though. I plan to keep my current system at least that long. Then maybe I'll go one way or the other.
Angrybird - Tuesday, August 28, 2012 - link
at low end, AMD has been a very competitive solution for internet cafe's here in the Philippines for the past years but now (2012), 8 out of 10 internet cafe's switches to Intel (its a fact, try and make a survey).. sandy bridge pentiums and celerons kick AMD in the lowend where AMD used to shine. Athlon II is very old, Llano is still a good option but who wants a dead end road?Death666Angel - Wednesday, August 29, 2012 - link
If it's a fact, you should have the survey you base that fact on.iwod - Tuesday, August 28, 2012 - link
Just from reading the improvement it is obvious the design is for Server workload. And that is great because that is where the money are heading. Consumer market is shrinking with ARM Tablet / Smartphones, as well as their Fusion APU to handle those needs.But will that be enough? I will have to wait and see the benchmarks on servers software loads. 15% performance is surely not enough, If they could do 15% performance increase while giving a 15% less power usage it may be good enough for now.
elerick - Wednesday, August 29, 2012 - link
Well I am rooting for AMD but this release to me feels like they are pulling their punch. I will not pretend to understand all the tweaks and how it will address their previous design flaws.But there was no mention of memory controller enhancements, the previous buzz was that AMD was potentially going to introduce quad channel memory controller support much like their servers. Don't quote me but I know I've read it somewhere. I do not see any mention of anything other than they are focusing on latency which is fantastic for power efficiency and mobile platforms however they have no focus on any major improvements to the desktop cpu (referring to the L3 cache reference in the article)
Where is the desktop CPU love? I know myself and many people have desktop computers which are good enough for the here and now, but by 2013/2014 we would love a healthy upgrade from AMD but it looks like 15% year after year is all that is planned but to make matters worse those numbers are completely focused on mobile platforms.
meloz - Wednesday, August 29, 2012 - link
> The improvements look good on paper, but the real question remains whether or not Steamroller will be enough to go up against Haswell.Why even *pretend* that this is a two horse race anymore?
We _all_ know it will be no match to Haswell. Even with a generous 20% improvement on CPU side, the Steamroller will at best match IVB, let alone IVB-E or whatever the large socket version of IVB will be eventually called. Forget Haswell, which will add another 10-15% over IVB.
And all that is in pure performance per $ metric; Intel will absolutely kill whatever AMD has to offer in the performance / watt.
At best, we will get some good Steamroller based APUs, but those also have limited benefit to users like me since AMD's linux graphic support is virtually non-existant when compared to Intel (http://intellinuxgraphics.org/), and Intel is steadily improving its weak iGPU...