OCZ Vector (256GB) Review
by Anand Lal Shimpi on November 27, 2012 9:10 PM ESTRandom Read/Write Speed
The four corners of SSD performance are as follows: random read, random write, sequential read and sequential write speed. Random accesses are generally small in size, while sequential accesses tend to be larger and thus we have the four Iometer tests we use in all of our reviews.
Our first test writes 4KB in a completely random pattern over an 8GB space of the drive to simulate the sort of random access that you'd see on an OS drive (even this is more stressful than a normal desktop user would see). I perform three concurrent IOs and run the test for 3 minutes. The results reported are in average MB/s over the entire time. We use both standard pseudo randomly generated data for each write as well as fully random data to show you both the maximum and minimum performance offered by SandForce based drives in these tests. The average performance of SF drives will likely be somewhere in between the two values for each drive you see in the graphs. For an understanding of why this matters, read our original SandForce article.

Low queue depth random read performance sees a significant regression compared to the Vertex 4. OCZ derives the Vector's specs at a queue depth of 32, at which it'll push 373MB/s of 4KB random reads. As Intel has established in the past, low queue depth random read performance of around 40 - 50MB/s is sufficient for most client workloads as we'll soon see in our trace based storage bench suite.
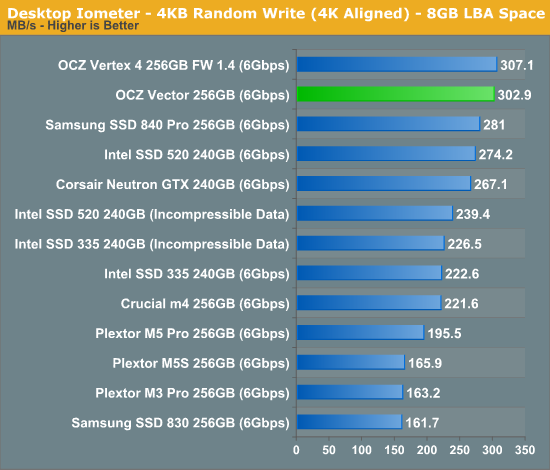
Low queue depth random write performance is a very different story, here the Vector pretty much equals the Vertex 4's already excellent score.
Many of you have asked for random write performance at higher queue depths. What I have below is our 4KB random write test performed at a queue depth of 32 instead of 3. While the vast majority of desktop usage models experience queue depths of 0 - 5, higher depths are possible in heavy I/O (and multi-user) workloads:
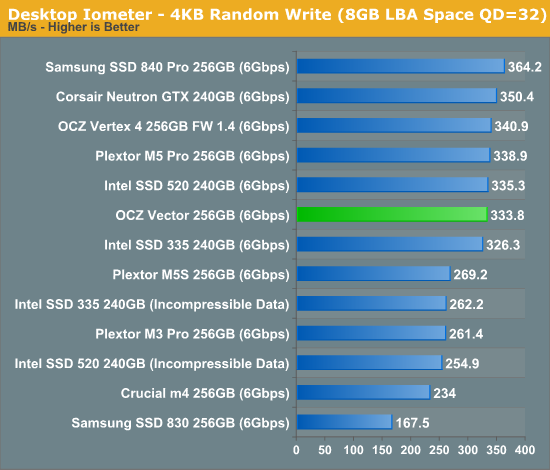
Crank up the queue depth and the Vector does well, but Samsung's SSD 840 Pro manages a nearly 10% performance advantage here.
Steady State 4KB Random Write Performance
OCZ will surely derive enterprise versions of the Vector and its Barefoot 3 controller, but I was curious to see what steady state 4KB random write performance looked like on the drive. I grabbed some of our Enterprise Iometer results from the S3700 review and trimmed out the non-SATA drives. The results are hugely improved compared to the Vertex 4:
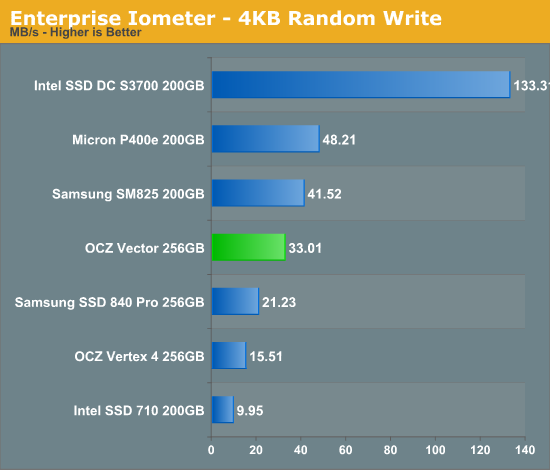
Keep in mind this isn't an enterprise drive, and thus it's not too surprising to see significantly higher numbers here from other enterprise drives but the improvement over the Vertex 4 is substantial. Note that Samsung's SSD 840 Pro lands somewhere in between the Vector and Vertex 4.








151 Comments
View All Comments
Brahmzy - Wednesday, November 28, 2012 - link
I should note that this works best after a secure erase and during the Windows install, don't let Windows take up the entire partition. Create a smaller pertition from the get-go. Don't shrink it later in Windows, once the OS has been installed. I believe the SSD controller knows that it can't do it's work in the same way if there is/was an empty partition taking up those cells. I could be wrong - this was the case with the older SSDs - maybe the newer controllers treat any free space as fair game to do their garbage collection/wear leveling.jwilliams4200 - Wednesday, November 28, 2012 - link
If the SSD has a good TRIM implementation, you should be able to reap the same OP benefits (as a secure erase followed by creating a smaller-than-SSD partition) by shrinking a full-SSD partition and then TRIMming the freed LBAs. I don't know for a fact the Windows 7 Disk Management does a TRIM on the freed LBAs after a shrink, but I expect that it does.I tend to use linux more than Windows with SSDs, and when I am doing tests I often use linux hdparm to TRIM whichever sectors I want to TRIM, so I do not have to wonder whether Windows TRIM did I wanted or not. But I agree that the safest way to OP in Windows is to secure erase and then create a partition smaller than the SSD -- then you can be absolutely sure that your SSD has erased LBAs, that are never written to, for the SSD to use as spare area.
seapeople - Sunday, December 2, 2012 - link
Wouldn't it be better if you just paid half price and bought the 60GB drive (or 80GB if you actually *need* 60GB) for the amount of space you needed at the present, and then in a year or two when SSD's are half as expensive, more reliable, and twice as fast you upgrade to the amount of space your needs have grown to?Your new drive without overprovisioning would destroy your old overprovisioned drive in performance, have more space (because we're double the size and not 30% OP'ed), you'd have spent the same amount of money, AND you now have an 80GB drive for free.
Of course, you should never go over 80-90% usage on an SSD anyway, so if that's what you're talking about then never mind...
kozietulski - Wednesday, November 28, 2012 - link
Nice results and great pictures. Really shows importance of free space/OP for random write preformance. Even more amazing is that the results you got seem to fit quite good with simplified model of SSD internal workings:Lets assume we have SDD with only the usual ~7% of OP which was nearly 100% filled (one can say trashed) by purely random 4KB writes (should we now write KiB just to make a few strange guys happy?) and assuming also that the drive operates on 4KB pages and 1MB blocks (today drives seem to be using rather 8KB/2MB but 4KB makes things simpler to think about) so having 256 pages per block. If trashing was good enough to achieve perfect randomisation we can expect that each block contains about 18-19 free pages (out of 256). Under heavy load (QD32, using ncq etc) decent firmware should be able to make use of all that free pages in given block before it (the firmware) decides to write the block back to NAND. Thus under heavy load and with above assumptions ( 7% OP) we can expect at worst case (SSD totaly trashed by random writes and thus free space fully randomized) Wear Amplification of about 256:18 ~= 14:1.
Now when we allow for 20% of free space (in addition to implicit ~7%OP) we should see on average about 71-72 out of 256 pages free in each and every block. This translates to WA ~= 3.6:1 (again assuming that firmware is able to consume all free space in the block before writing it back to nand. That is maybe not so obvious as there are limits in max number of i/o bundled in single ncq request but should not be impossible for the firmware to delay the block write few msecs till next request comes to see if there are more writes to be merged into the block).
Differences in WA translate directly to differences in performance (as long as there is no other bottleneck of course) so with 14:3.6 ~= 3.9 we may expect random 4KB write performance nearly 4 higher for drive with 20% free space compared to drive working with only bare 7% of implicit OP.
May be just an accident but that seem to fit pretty close to results you achieved. :)
jwilliams4200 - Wednesday, November 28, 2012 - link
Interesting analysis. Without knowing exactly how the 840 Pro firmware works I cannot be certain, but it does sound like you have a reasonable explanation for the data I observed.kozietulski - Wednesday, November 28, 2012 - link
Yeah, there is lot of assumptions and simplifications in above... well surely woudn't call it analysis, perhaps hypothesis would be also a bit too much. Modern SSDs have lots of bells and whistles - as well as quirks - and most of them - particularly quirks - aren't documented well. All that means that conformity of the estimation with your results may very well be nothing more then just a coincidence.The one thing I'm reasonably sure however - and it is the reason I thought it is worth to write the post above - is that for random 4K writes on the heavily (ab)used SSD the factor which is limiting performance the most is Write Amplification. (at least as long as we talk about decent SSDs with decent controllers - Phisons does not qualify here I guess :)
In addition to obvious simplifications there was one another shortcut I took above: I based my reasoning on the "perfectly trashed" state of SSD - that is one where SSD's free space is in pages equally spread over all nand blocks. In theory the purpose of GC algos is to prevent drives reaching such a state. Still I think there are workloads which may bring SSDs close enough to that worst possible state and so that it is still meaningful for worst case scenario.
In your case however the starting point was different. AFAIU you used first sequential I/O to fill 100 / 80 % of drive capacity so we can safely assume that before random write session started drive contained about 7% (or ~27% in second case) of clean blocks (with all pages free) and the rest of blocks were completely filled with data with no free pages (thanks to nand-friendly nature of sequential I/O).
Now when random 4K writes start to fly... looking from the LBA space perspective these are by definition overwrites of random chunks of LBA space but from SSD managed perspective at first we have writes filling pool of clean blocks coupled by deletions of randomly selected pages within blocks which were until now fully filled with data. Surely such deletion is actually reduced to just marking of such pages as free in firmware FTL tables (any GC at that moment seem highly unlikely imho).
At last comes the moment when clean blocks pool is exhausted (or when size of clean pool falls below the threshold) which is waking up GC alhorithms to make their sisyphean work. At that moment situation looks like that (assuming that there was no active GC until now and that firmware was capable enough to fill clean blocks fully before writing to NAND): 7% (or 27% in second case) of blocks are fully filled with (random) data whereas 93/73 % of blocks are now pretty much "trashed" - they contain (virtually - just marked in FTL) randomly distributed holes of free pages. Net effect is that - compared to the starting point - free space condensed at first in the pool of clean blocks is now evenly spread (with page granularity) over most of drive nand blocks. I think that state does not look that much different then the state of complete, random trashing I assumed in post above...
From that point onward till the end of random session there is ongoing epic struggle against entropy: on one side stream of incoming 4K writes is punching more free page holes in SSD blocks thus effectively trying to randomize distribution of drive available free space and GC algorithms on the other side are doing their best to reduce the chaos and consolidate free space as much as possible.
As a side note I think it is really a pity that there is so little transparency amongst vendors in terms of comunicating to customers internal workings of their drives. I understand commercial issues and all but depriving users of information they need to efficiently use their ssds leads to lots of confused and sometimes simply disappointed consumers and that is not good - in the long run - for the vendors too. Anyway maybe it is time to think about open source ssd firmware for free community?! ;-)))
ps. Thanks for reference to fio. Looks like very flexible tool, may be also easier to use then iometer. Surely worth to try at least.
cbutters - Wednesday, November 28, 2012 - link
So based on 36TB to end the warranty, basically you can only fill up your 512GB drive 72 times before the warranty expires? That doesn't seem like a whole lot of durability. reinstalling a few large games several times could wear this out pretty quickly... or am I understanding something incorrectly.According to my calculations, assuming a gigabit network connection, running at 125MB per second storing data, that is .12GB per second, 7.3242GB per minute, 439GB per hour, or 10.299TB per day... Assuming this heavy write usage,... that 36 TB could potentially be worn out in as little as 3.5 days using a conservative gigabit network speed as the baseline.
Makaveli - Wednesday, November 28, 2012 - link
I've had an SSD 3 years and it currently has 3TB's of host writes!jimhsu - Wednesday, November 28, 2012 - link
I assume warranties such as this assume an unrealistically high write amplification (e.g. 10x) (to save the SSD maker some skin, probably). Your sequential write example (google "rogue data recorder") most likely has a write amplification very close to 1. Hence, you can probably push much more data (still though the warranty remains conservative).jwilliams4200 - Wednesday, November 28, 2012 - link
Even WA=10 is not enough to account for the 512GB warranty of 36TB. That only comes to about 720 erase cycles if WA=10.I think the problem is that the warrantied write amount should really scale with the capacity of the SSD.
Assuming WA=10, then 128GB @ 3000 erase cycles should allow about 3000 *128GB/10 = 38.4TB. The 256GB should allow 76.8TB. And the 512GB should get 153.6TB.