NVIDIA Launches Tesla K20 & K20X: GK110 Arrives At Last
by Ryan Smith on November 12, 2012 9:00 AM ESTEfficiency Through Hyper-Q, Dynamic Parallelism, & More
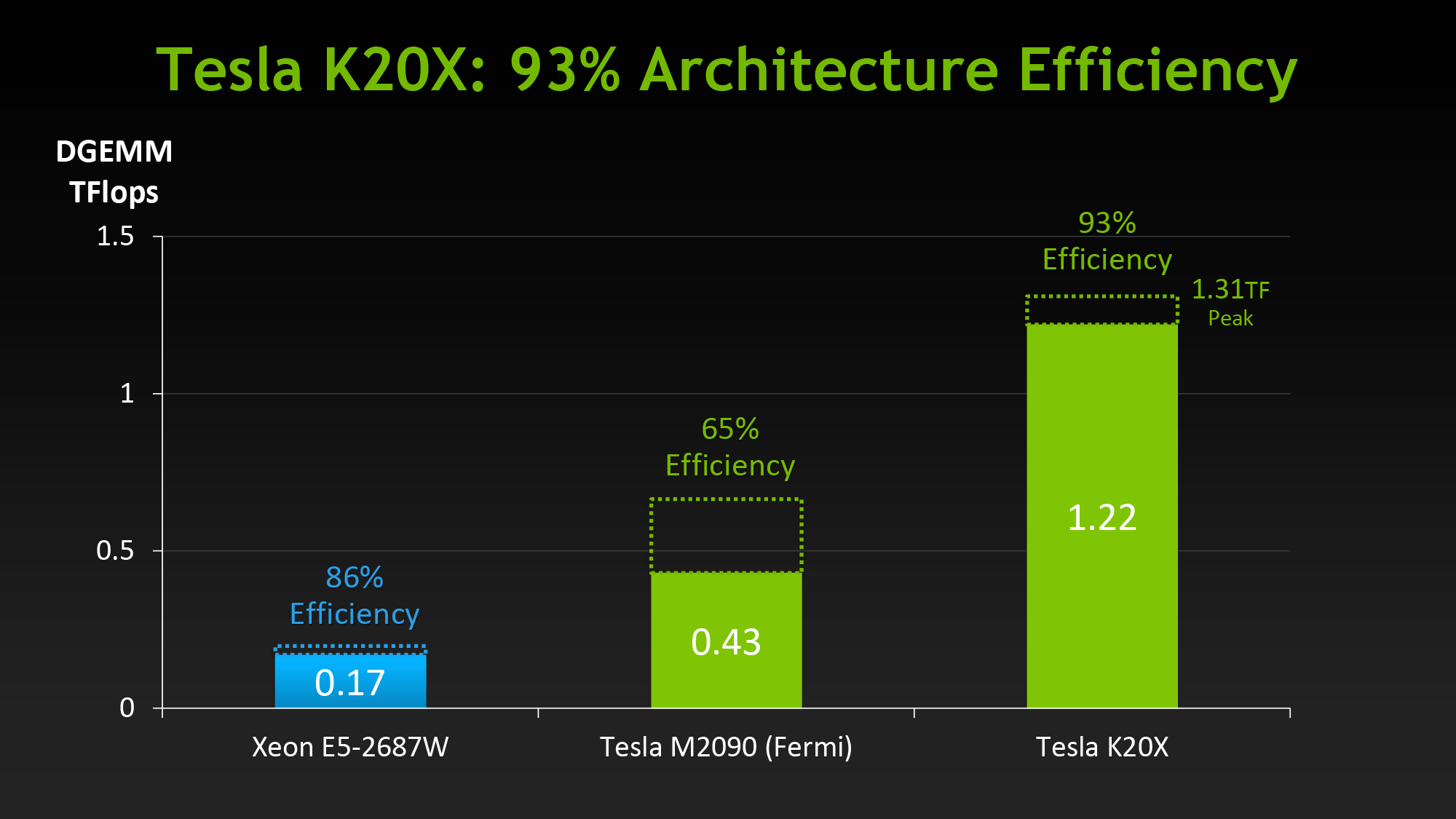
When NVIDIA first announced K20 they stated that their goal was to offer 3x the performance per watt of their Fermi based Tesla solutions. With wattage being held nearly constant from Fermi to Kepler, NVIDIA essentially needed to triple their total performance to reach that number.
However as we’ve already seen from NVIDIA’s hardware specifications, K20 triples their theoretical FP32 performance but not their theoretical FP64 performance, due to the fact that NVIDIA’s FP64 execution rate falls from ½ to 1/3their FP32 rate. Does that mean NVIDIA has given up on tripling their performance? No, but with Kepler the solution isn’t just going to be raw hardware, but the efficient use of existing hardware.
Of everything Kepler and GK110 in particular add to NVIDIA’s compute capabilities, their marquee features, HyperQ and Dynamic Parallelism, are firmly rooted in maximizing their efficiency. Now that we’ve seen what NVIDIA’s hardware can do at a low level, we’ll wrap up our look at K20 and GK110 by looking at how NVIDIA intends to maximize their efficiency and best feed the beast that is GK110.
Hyper-Q
Sometimes the simplest things can be the most powerful things, and this is very much the case for Hyper-Q. Simply put, Hyper-Q expands the number of hardware work queues from 1 on GF100 to 32 on GK110. The significance of this being that having 1 work queue meant that GF100 could be under occupied at times (that is, hardware units were left without work to do) if there wasn’t enough work in that queue to fill every SM or if there were dependency issues, even with parallel kernels in play. By having 32 work queues to select from, GK110 can in many circumstances achieve higher utilization by being able to put different program streams on what would otherwise be an idle SMX.
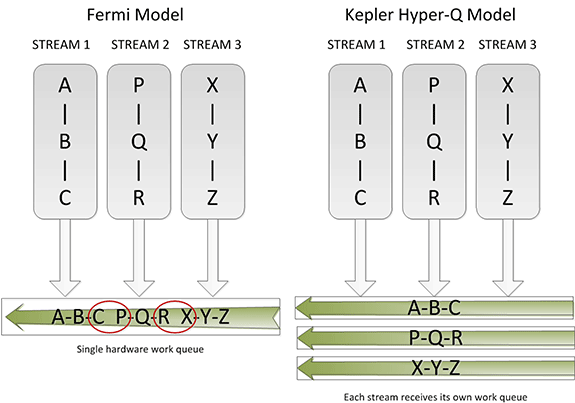
The simplistic nature of Hyper-Q is further reinforced by the fact that it’s designed to easily map to MPI, a common message passing interface frequently used in HPC. As NVIDIA succinctly puts it, legacy MPI-based algorithms that were originally designed for multi-CPU systems and that became bottlenecked by false dependencies now have a solution. By increasing the number of MPI jobs (a very easy modification) it’s possible to utilize Hyper-Q on these algorithms to improve the efficiency all without changing the core algorithm itself. Ultimately this is also one of the ways NVIDIA hopes to improve their HPC market share, as by tweaking their hardware to better map to existing HPC workloads is in this fashion NVIDIA’s hardware will become a much higher performing option.
Dynamic Parallelism
If Hyper-Q was the simple efficiency feature, then NVIDIA’s other marquee feature, Dynamic Parallelism, is the harder and more complex of the features.
Dynamic Parallelism is NVIDIA’s name for the ability for kernels to be able to dispatch other kernels. With Fermi only the CPU could dispatch a new kernel, which incurs a certain amount of overhead by having to communicate back and forth with the CPU. By giving kernels the ability to dispatch their own child kernels, GK110 can both save time by not having to go back to the GPU, and in the process free up the CPU to work on other tasks.

The difficult of course comes from the fact that dynamic parallelism implicitly relies on recursion, to which as the saying goes “to understand recursion, you must first understand recursion”. The use of recursion brings with it many benefits so the usefulness of dynamic parallelism should not be understated, but if nothing else it’s a forward looking feature. Recursion isn’t something that can easily be added to existing algorithms, so taking full advantage of dynamic parallelism will require new algorithms specifically designed around it. (ed: fork bombs are ready-made for this)
Reduced ECC Overhead
Although this isn’t strictly a feature, one final efficiency minded addition to GK110 is the use of a new lower-overhead ECC algorithm. As you may recall, Tesla GPUs implement DRAM ECC in software, allowing ECC to be added without requiring wider DRAM busses to account for the checkbits, and allowing for ECC to be enabled and disabled as necessary. The tradeoff for this is that enabling ECC consumes some memory bandwidth, reducing effective memory bandwidth to kernels running on the GPU. GK110 doesn’t significantly change this model, but what it does do is reduce the amount of ECC checkbit traffic that results from ECC being turned on. The amount of memory bandwidth saved is workload dependent, but NVIDIA’s own tests are showing that the performance hit from enabling ECC has been reduced by 66% for their internal test suite.
Putting It All Together: The Programmer
Bringing things to a close, while we were on the subject of efficiency the issue of coder efficiency came up in our discussions with NVIDIA. GK110 is in many ways a direct continuation of Fermi, but at the same time it brings about a significant number of changes. Given the fact that HPC is so performance-centric and consequently often so heavily tuned for specific processors (a problem that also spans to consumer GPGPU workloads) we asked NVIDIA about just how well existing programs run on K20.
The short answer is that despite the architectural changes between Fermi and GK110, existing programs run well on K20 and are usually capable of taking advantage of the additional performance offered by the hardware. It’s clear that peak performance on K20 will typically require some rework, particularly to take advantage of features like dynamic parallelism, but otherwise we haven’t been hearing about any notable issues transitioning to K20 thus far.

Meanwhile as part of their marketing plank NVIDIA is also going to be focusing on bringing over additional HPC users by leveraging their support for OpenACC, MPI, and other common HPC libraries and technologies, and showcasing just how easy porting HPC programs to K20 is when using those technologies. Note that these comparisons can be a bit misleading since the core algorithms of most programs are complex yet code dense, but the main idea is not lost. For NVIDIA to continue to grow their HPC market share they will need to covert more HPC users from other systems, which means they need to make it as easy as possible to accommodate their existing code and tools.








73 Comments
View All Comments
Assimilator87 - Monday, November 12, 2012 - link
nVidia already sells a $1k consumer graphics card, aka the GTX 690, so why can't they introduce one more?HisDivineOrder - Monday, November 12, 2012 - link
More to the point, they don't need to. The performance of the GK104 is more or less on par with AMD's best. If you don't need to lose money keeping up with the best your opponent has, then why should you lose money?Keep in mind, they're charging $500 (and have been charging $500) for a GPU clearly built to be in the $200-$300 segment when their chief opponent in the discrete GPU space can't go a month without either dropping the prices of their lines or offering up a new, even larger bundle. This is in spite of the fact that AMD has released not one but two spectacular performance driver updates and nVidia disappeared on the driver front for about six months.
Yet even still nVidia charges more for less and makes money hand over fist. Yeah, I don't think nVidia even needs to release anything based on Big Daddy Kepler when Little Sister Kepler is easily handing AMD its butt.
RussianSensation - Monday, November 12, 2012 - link
"Big Daddy Kepler when Little Sister Kepler is easily handing AMD its butt."Only in sales. Almost all major professional reviewers have handed the win to HD7970 Ghz as of June 2012. With recent drivers, HD7970 Ghz is beating GTX680 rather easily:
http://www.legionhardware.com/articles_pages/his_7...
Your statement that Little Kepler is handing AMD's butt is absurd when it's slower and costs more. If NV's loyal consumers want a slower and more expensive card, more power to them.
Also, it's evident based on how long it took NV to get volume production on K20/20X, that they used GK104 because GK100/110 wasn't ready. It worked out well for them and hopefully we will get a very powerful GTX780 card next generation based on GK110 (or perhaps some other variant).
Still, your comment flies in the face of facts since GK104 was never build to be a $200-300 GPU because NV couldn't possibly have launched a volume 7B chip since they are only now shipping thousands of them. Why would NV open pre-orders for K20 parts in Spring 2012 and let its key corporate customers wait until November 2012 to start getting their orders filled? This clearly doesn't add up with what you are saying.
Secondly, you make it sound like price drops on AMD's part are a sign of desperation but you don't acknowledge that NV's cards have been overpriced since June 2012. That's a double standard alright. As a consumer, I welcome price drops from both camps. If NV drops prices, I like that. Funny how some people view price drops as some negative outcome for us consumers...
CeriseCogburn - Thursday, November 29, 2012 - link
So legion has the 7970 vanilla winning nearly every benchmark.LOL
I guess amd fanboys can pull out all the stops, or as we know, they are clueless as you are.
http://www.hardocp.com/article/2012/10/08/his_rade...
Oh look at that, the super expensive amd radeon ICE Q X2 GIGAHERTZ EDITION overclocked can't even beat a vanilla MSI 680 .
LOL
Reality sucks for amd fanboys.
Gastec - Tuesday, November 13, 2012 - link
Right now ,in the middle of the night, an idea sprang into my abused brain. nVidia is like Apple. And their graphical cards are like the iPhones. There's always a few millions of people willing to buy their producs no matter what, no matter what price they put up. Even if the rest of the world would stop buying nVidia and iPhones at least there will always be some millions of amaricans to will buy them, and their sons and their sons' sons and so on and so forth until the end of days. Heck even one of my friends when we were chatting about computers components uttered the words: "So you are not a fan of nVidia? You know it has PhysX." In my mind I was like : "FAN? What the...I bought my ATI card because it was cheaper and consumed less power so I pay less money when the bloo...electricity bill comes" And after reading all your comments I understand now what you mean by "fanboy" or "fanboi" whatever. Typically american bs.CeriseCogburn - Thursday, November 29, 2012 - link
LOL - another amd fanboy idiot who needs help looking in the mirror.Kevin G - Monday, November 12, 2012 - link
A consumer card would make sense if yields are relatively poor. A die this massive has to have a very few fully functional chips (in fact, K20X only has 14 of 15 SMX clusters enabled). I can see a consumer card with 10 or 12 SMX clusters being active depending on yields for successful K20 and K20X dies.RussianSensation - Monday, November 12, 2012 - link
It would also make sense if the yields are very good. If your yields are exceptional, you can manufacture enough GK110 die to satisfy both the corporate and consumer needs. Right now the demand for GK110 is outstripping supply. Based on what NV has said, their yields are very good. The main issue is wafer supply. I think we could reasonably see a GK110 consumer card next year. Maybe they will make a lean gaming card though as a lot of features in GK110 won't be used by gamers.Dribble - Tuesday, November 13, 2012 - link
Hope not - much better to give us another GK104 style architecture but increase the core count.wiyosaya - Monday, November 12, 2012 - link
IMHO, at these prices, I won't be buying one, nor do I think that the average enthusiast is going to be interesting in paying perhaps one and a half to three times the price of a good performance PC for a single Tesla card. Though nVidia will probably make hoards of money from supercomputing centers, I think they are doing this while forsaking the enthusiast market.The 600 series seriously cripples double-precision floating point capabilities making a Tesla an imperative for anyone needing real DP performance, however, I won't be buying one. Now if one of the 600 series had DP performance on par or better than the 500 series, I would have bought one rather than buying a 580.
I don't game much, however, I do run several BOINC projects, and at least one of those projects requires DP support. For that reason, I chose a 580 rather than a 680.