Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
Gigabyte GA-7PESH1 Software
Typically when a system integrator buys a server motherboard from Gigabyte, a full retail package comes with it including manuals, utility CDs and SATA cables. Gigabyte have told me that this will be improved in the future, with SAS cables, header accessories and GPU bridges for CF/SLI. But due to the nature of my review sample, there was no retail package as such. When I received a sample from Gigabyte, there was no retail box with extras, nor were there driver CDs or a user guide and manual. Good job then that all these can be found on the Gigabyte website under the download section for the GA-7PESH1. In my case, this involves downloading the Intel .inf files, the ASPEED 2300 drivers, and the Intel LAN drivers. Also available on the website are the LSI SAS RAID drivers, and the SATA RAID driver.
When it comes to software available to download, the river has run dry. There is literally not one piece of software available to the user – nothing relating to monitoring, or fan controls or the like. The only thing that approaches a software tool is the Advocent Server Management Interface, which is accessed via the browser of another computer connected to the same network when the system has the third server management NIC connection activated.
When the system is connected to the power supply, and the power supply is switched on, the motherboard takes around 30 seconds to prepare itself before the power button on the board itself can be pushed. There is a green light physically on the board that turns from a solid light to a flashing light when this button can be pushed - the board then takes another 60 seconds or so to POST. During this intermediate state when the light is flashing, the server management software can be accessed through the web interface.
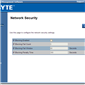
The default username and password are admin and password for this interface, and when logged in we get a series of options relating to the management of the motherboard:
The interface implements a level of security in accessing the management software, as well as keeping track of valid user accounts, web server settings, and active interface sessions.


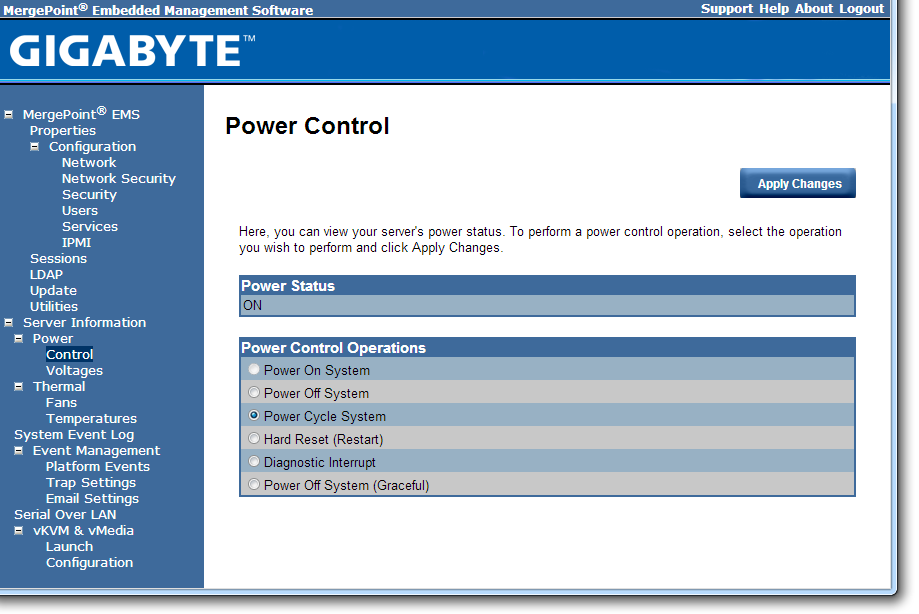
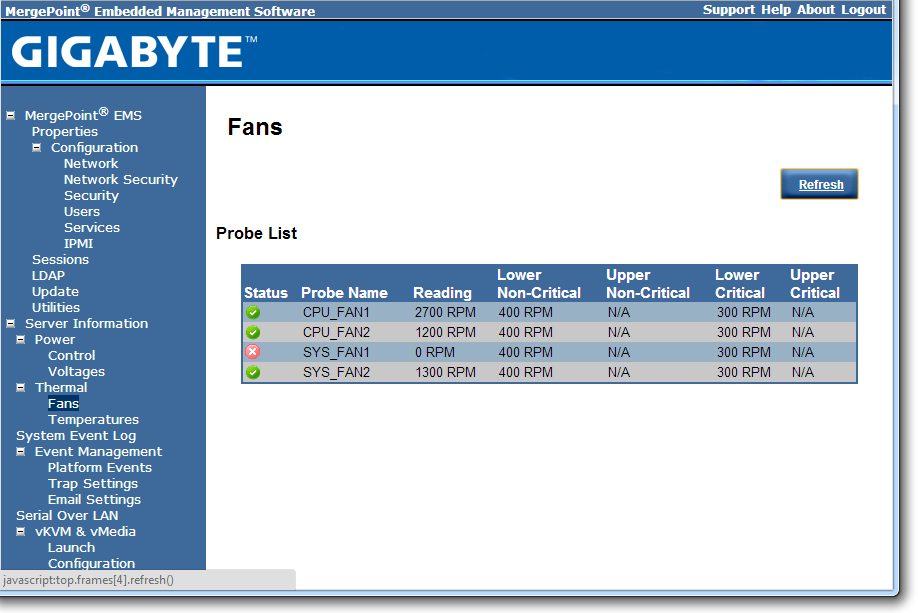
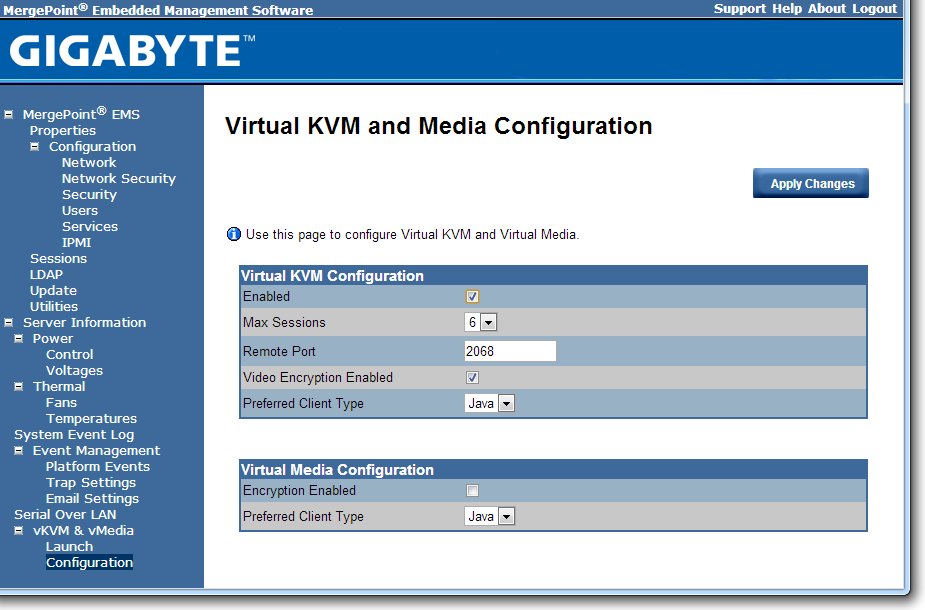
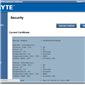
The software also provides options to update the firmware, and to offer full control as to the on/off state of the motherboard with access to all voltages, fan speeds and temperatures the software has access to.
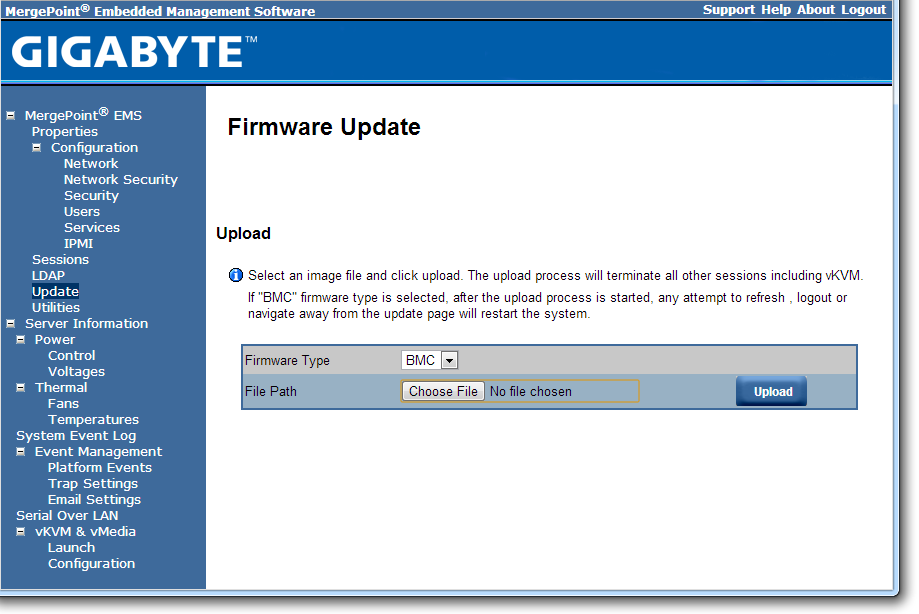

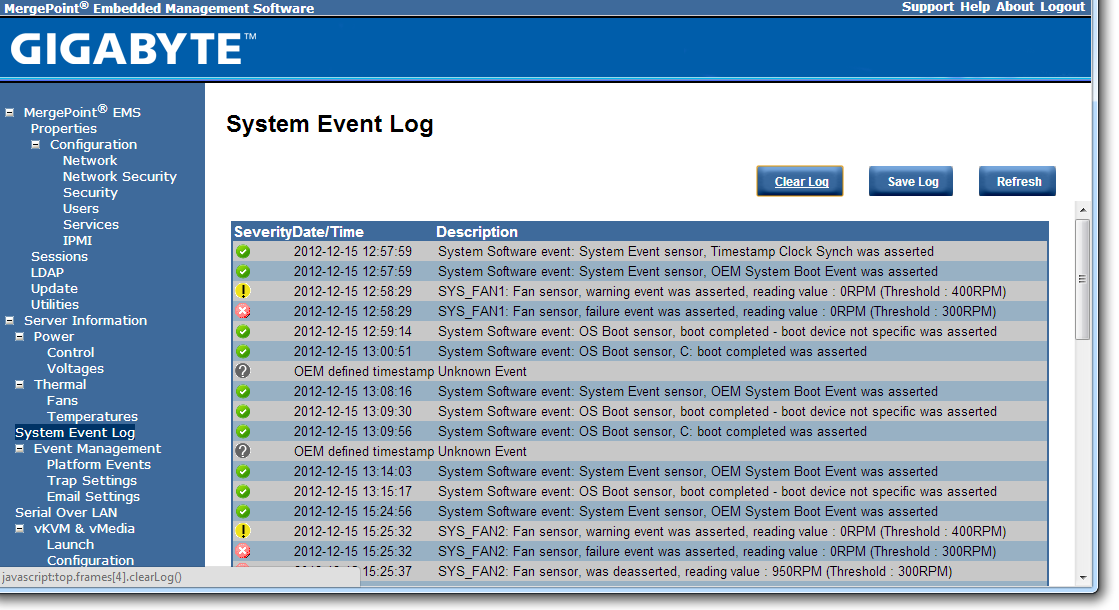
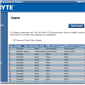
The system log helps identify when sensors are tripped (such as temperature and fans) as well as failed boots and software events.
Both Java KVM and Have VM environments are supported, with options relating to these in the corresponding menus.
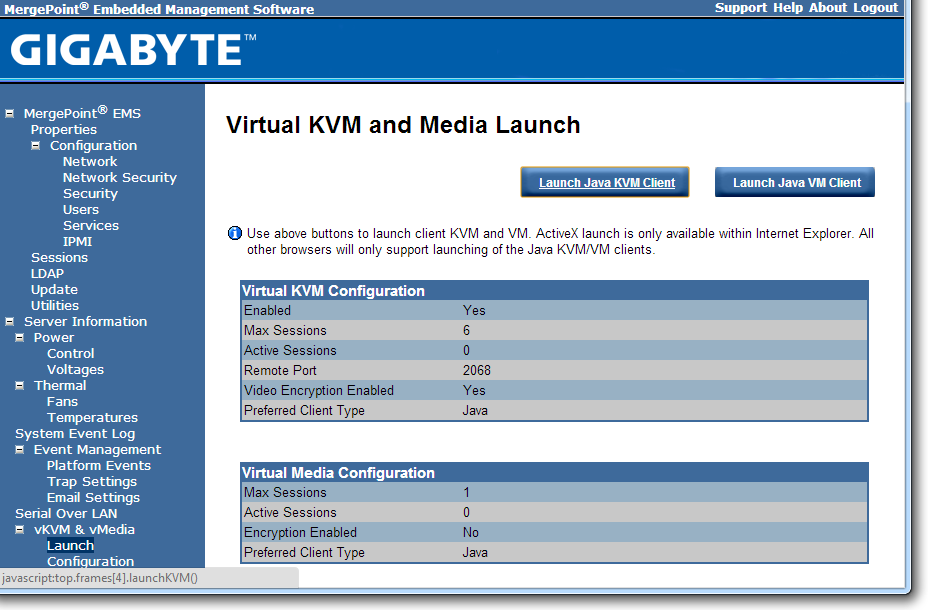
It should also be noted that during testing, we found the system to be unforgiving when changing discrete GPUs. If an OS was installed while attached to a GTX580 and NVIDIA drivers were installed, the system would not boot if the GTX580 was removed and a HD7970 was put in its place. The same thing happens if the OS is installed under the HD7970 and the AMD drivers installed.








64 Comments
View All Comments
Hakon - Saturday, January 5, 2013 - link
Thank you for the detailed answer. I very much appreciate your article and hope to see more stuff like this on Anandtech.What I meant regarding to NUMA is the following. When you have a dual socket Xeon you have two memory controllers. The first time you 'touch' a memory location it is assigned to the memory controller of the CPU that runs the current thread. This assignment is in general permanent and all further memory read/writes to that location will be served by that memory controller.
If you first-touch (e.g. initialize the array to zero) using one thread, then the whole array is assigned to one of the two memory controllers. When you then run the multi-threaded code on that array one memory controller is idle while the other is oversubscribed since it has to serve both CPUs.
In contrast, if you first-touch your array in an OpenMP loop and use the same access pattern as in the algorithm, you will benefit from both memory controllers later on. In this case your large array is correctly 'distributed' over both memory controllers.
This kind of memory layout optimization becomes extremely important when you deal with quad socket Opterons. You then have eight memory controllers. A NUMA aware code is therefore up to eight times as fast since it utilizes all memory controllers.
toyotabedzrock - Saturday, January 5, 2013 - link
You should go ask the people on the assembly boards for help with making your code faster.They are very friendly compared to a Linux kernel devs, I think they just enjoy the acknowledgement that they still exist and are useful.
snajpa - Saturday, January 5, 2013 - link
Blame the scheduler. Neither Windows nor linux can effectively handle larger NUMA systems. It randomly moves the process across the physical hardware.psyq321 - Sunday, January 6, 2013 - link
Hmm, this is definitely not true at least for Windows Server 2008 R2 / Windows 7, and I am sure it holds true for some versions of Linux (I am not a Linux expert).Windows Server 2008 R2 / Windows 7 scheduler will try to match the memory allocations (even if they are not tagged for a specific NUMA node) with the NUMA node the process/thread resides on, and they will not move a thread to a foreign NUMA node unless if that has been explicitly requested by the application (by setting the thread affinity)
Of course, without explicit NUMA node tagging when doing allocations, application code is the main culprit for not respecting the NUMA layout (e.g. creating bunch of threads, allocating memory from one of them - and then pinning the threads to different CPUs - you will have lots of LLC requests from remote DRAM because memory was a-priori allocated on one node).
For this - some sane coding helps a lot, here:
http://www.dimkovic.com/node/15
I describe how I extracted more than double performance by careful memory allocation (NUMA-aware) - please note that neither Windows nor Linux scheduler is able to cope with code which is not written to be NUMA aware and it is using large number of threads that are supposed to run on all CPUs.. Simply put, application writer will have to manage memory allocation and usage in the way so that there are as little remote DRAM requests as possible.
snajpa - Sunday, January 6, 2013 - link
About Windows scheduler - I only worked with Windows XP, now I don't have any reason to work with Win anymore, so what you say probably is really true. As for the linux versions - well, long story short, CFS sucks and everyone knows it - this is particularly noticeable if you have fully virtualized VMs which appear as one single process at the host system - the process is randomly swapped between CPU cores and even CPU dies.... sad story. That's why people have to pin their CPUs to their tasks manually.psyq321 - Sunday, January 6, 2013 - link
Ah, XP - that explains it. True, XP did not care about NUMA at all.Windows Server 2008 / Vista introduced NUMA-aware memory allocations, and changed their CPU scheduler so it does not move the thread across NUMA nodes. They will also try to allocate the memory from the thread's own NUMA node when legacy VirtualAlloc etc. APIs are used.
Windows Server 2008 R2 / Windows 7 introduced the concept of CPU groups - allowing more than 64 CPUs. This does require some adaptation of the application, as old threading APIs only work with 64-bit affinity bitmask which only allowed recognizing 64 CPUs. Now, there is a new set of APIs that work with GROUP_AFFINITY structure, allowing control of CPU groups, too. However, this needs explicit change of the legacy process/threading APIs to the new ones.
Furthermore, none of the above can replace some manual intervention*- while Windows scheduler will, indeed, respect NUMA node boundaries and not try to mess around with moving threads across them - it still does not know what the underlying algorithm wants to do.
* There is no need to set the thread affinity to one specific CPU anymore - this prevents running the thread on any other CPU completely. Instead, there is an API called SetThreadIdealProcessor(Ex) which signals Windows scheduler that thread >should< run on that particular CPU - but, under certain circumstances the scheduler can move the thread somewhere else - if the CPU is completely taken away by some other thread/process. Scheduler will try to move the thread as close as possible - to the next core in the socket, for example - or to the next core in the group (group is always contained within a NUMA node).
You can, however, absolutely forbid Windows scheduler from passing the thread to another NUMA node under any circumstances by simply getting the said NUMA node affinity mask (GetNumaNodeProcessorMask(Ex)) and setting this affinity as a thread affinity. This + setting the "ideal" processor still gives Windows scheduler some headroom to move the thread to another core if it is found to be better in a given moment, but it will not even attempt to cross the NUMA boundary in any case whatsoever.
lmcd - Monday, January 7, 2013 - link
While I haven't personally researched them, there are tons of other schedulers that have been written for Linux and I'm certain *at least* one of them is more fitting to this line of work. I've heard of alternatives like BFS and the Linux kernel is so widely used I'm sure there's a gem out there for this application.toyotabedzrock - Saturday, January 5, 2013 - link
Have you ever tried the Intel Math Kernel Library? It might speed up some of the equations. It also hands off work to the Intel MIC card if it thinks it will speed it up.http://software.intel.com/en-us/intel-mkl/
KAlmquist - Saturday, January 5, 2013 - link
The GA-7PESH1 motherboard is $855, and the CPU's are $2020 each, which adds up to $4895. On tasks which don't parallelize well, you can get similar performance from the i7-3770K, which costs an order of magnitude less. (Prices: i7-3770K $320, ASRock Z77 Extreme6 motherboard $152, total from motherboard and CPU $472.) On tasks which parallelize well enough that they can be run on a GPU, the system with the GA-7PESH1 will beat the i7-3770K, but will be crushed by a midrange GPU. So the price/performance of this system is pretty bad unless you throw just the right workload at it.The motherboard price from super-laptop-parts dot com, and the other prices are from a major online retailer that I won't name in order to get around the spam filter.
Death666Angel - Saturday, January 5, 2013 - link
So, your 3770K has ECC memory or VT-D, TXT etc.?