Westmere-EP to Sandy Bridge-EP: The Scientist Potential Upgrade
by Ian Cutress on March 4, 2013 9:30 AM EST- Posted in
- CPUs
- Xeon
- Westmere-EP
- Sandy Bridge-EP
Earlier this year I wrote a review of a dual processor Sandy Bridge-EP system from the point of view of the non-CS trained coder in a research group, and whether the limited knowledge of advanced processor commands (beyond basic C++ with OpenMP) was a hindrance to dual processor systems on some simple grid solvers/Brownian motion simulation. As part of the feedback to the review, I was asked by several readers using the older Westmere-EP platform doing similar types of calculations if it was worth pushing their research budget for a move from Westmere-EP to high-end Sandy Bridge-E, and whether the jump in cores/IPC would cost effective in those simulation scenarios. Thankfully Gigabyte was on hand to supply their GA-7TESM DP socket 1366 Xeon board and a pair of X5690s in order to run the comparison.

Comparing Westmere-EP to Sandy Bridge-EP
Johan’s words say it best, from his article on the E5-2600 in March 2012:
Compared to its predecessor, the Xeon X5600, the Xeon E5-2600 offers a number of improvements:
A completely improved core, as described here in Anand's article. For example, the µop cache lowers the pressure on the decoding stages and lowers power consumption, killing two birds with one stone. Other core improvements include an improved branch prediction unit and a more efficient Out-of-Order backend with larger buffers.
A vastly improved Turbo 2.0. The CPU can briefly go beyond the TDP limits, and when returning to the TDP limit, the CPU can sustain higher "steady-state" clockspeed. According to Intel, enabling turbo allows the Xeon E5 to perform 14% better in the SAP S&D 2 tier test. This compares well with the Turbo inside the Xeon 5600 which could only boost performance by 4% in the SAP benchmark.
Support for AVX Instructions combined with doubling the load bandwidth should allow the Xeon to double the peak floating point performance compared to the Xeon "Westmere" 5600.
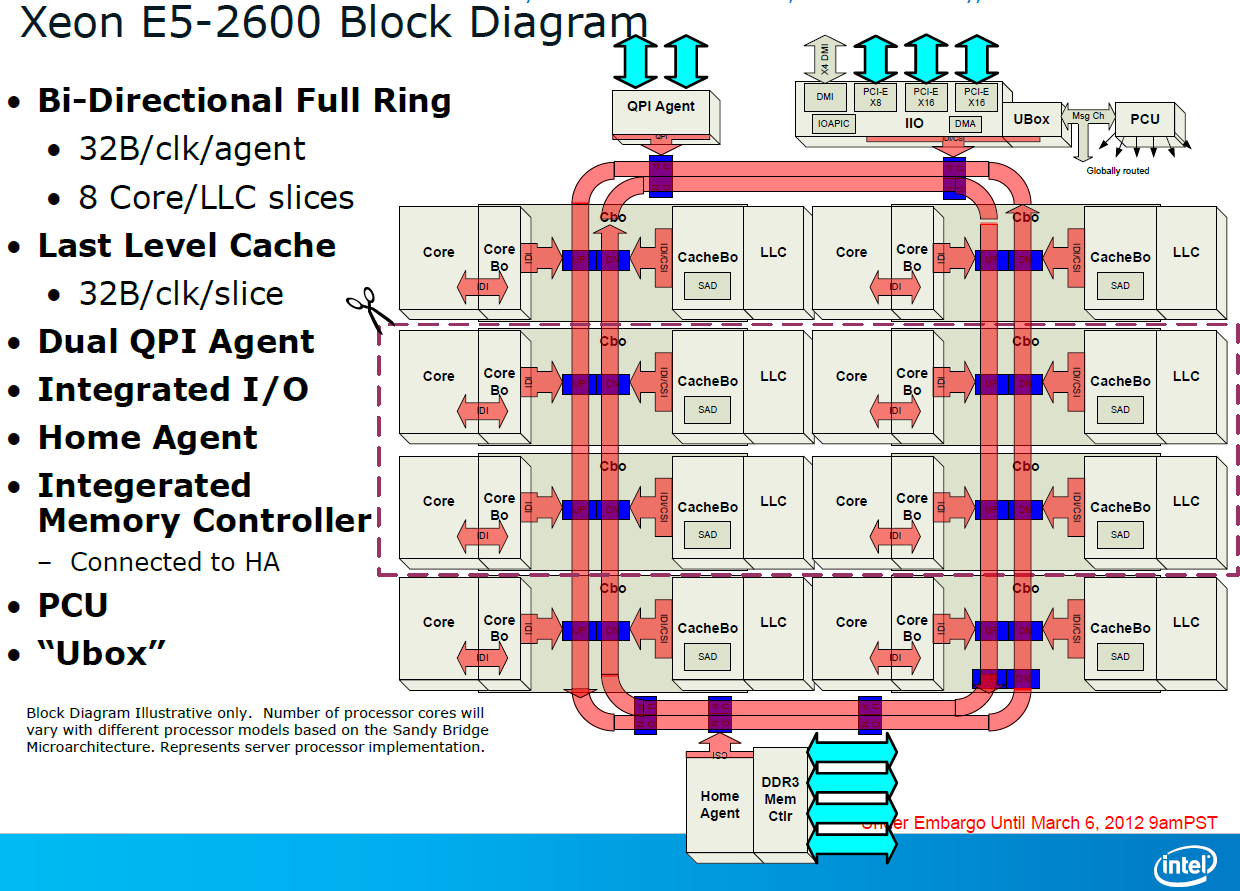
A bi-directional 32 byte ring interconnect that connects the 8 cores, the L3-cache, the QPI agent and the integrated memory controller. The ring replaces the individual wires from each core to the L3-cache. One of the advantages is that the wiring to the L3-cache can be simplified and it is easier to make the bandwidth scale with the number of cores. The disadvantage is that the latency is variable: it depends on how many hops a certain piece of data inside the L3-cache must cross before ends up at the right core.
A faster QPI: revision 1.1, which delivers up to 8 GT/s instead of 6.4 GT/s (Westmere).
Lower latency to PCI-e devices. Intel integrated a PCIe 3.0 I/O subsystem inside the die which sits on the same bi-directional 32 bit ring as the cores. PCIe 3.0 runs at 8 GT/s (PCIe 2.0: 5 GT/s), but the encoding has less overhead. As a result, PCIe 3.0 can deliver up to 1 GB full duplex per second per lane, which is twice as much as PCIe 2.0.
Removing the I/O lowered PCIe latency by 25% on average according to Intel. If you only access the local memory, Intel measured 32% lower read latency.
The access latency to PCIe I/O devices is not only significantly lower, but Intel's Data Direct I/O Technology allows the PCIe NICs to read and write directly to the L3-cache instead of to the main memory. In extremely bandwidth constrained situations (using 4 Infiniband controllers or similar), this lowers power consumption and reduces latency by another 18%, which is a boon to HPC users with 10G Ethernet or Infiniband NICs.
The new Xeon also supports faster DDR3-1600, up to 2 DIMMs per channel that can run at 1600 MHz.
Ian’s Analysis
In my line of computational chemistry, several E5-2600 characteristics would be very important to throughput:
- The improved core and µop cache should boost IPC through the roof with calculations that can take advantage, especially advanced trigonometric functions.
- The increase in L3 cache would reduce stress on jumps out to main memory for values, although the improved memory bandwidth would also help in this regard.
- More cores are always welcome – Turbo 2.0 would help with pre-release code testing, which often occurs in debug / single thread mode.
- An increase of memory limits would help various simulation scenarios, as well as aid having VMs of different environments.
- The move up to PCIe 3.0 helps any GPGPU simulation that requires lots of memory transfers back and forth across the bus (matrix solving), as long as the GPU supports PCIe 3.0 (K10, K20X, FirePro, not Xeon Phi which uses PCIe 2.0).
We all know the E5-2600 series is faster (one reader in response to the previous review had seen slowdown in parts of his code on E5-2600), but the question is always around “how much?”.
On paper, Johan’s article showed us the specifications side by side (along with Opteron counterparts):
|
Xeon E5-2600 Sandy Bridge-EP |
Opteron 6200 Interlagos |
Opteron 6100 Magny-Cours |
Xeon 5600 Westmere |
|
|
Cores/Threads Modules/Threads |
8/16 | 12/12 | 6/12 | |
| 8/16 | ||||
| L1 Instruction |
8x 32KB 4-way |
8x 64KB 2-way |
12x 64KB 2-way |
6x 32KB 4-way |
| L1 Data |
8x 32KB 8-way |
16x 16KB 4-way |
12x 64KB 2-way |
6x 32KB 8-way |
| L2 Cache | 8x 256 KB | 4x 2MB | 12x 512KB | 6x 256KB |
| L3 Cache | 20 MB | 2x 8MB | 2x 6MB | 12 MB |
|
Mem Bandwidth (Per Socket) |
51.2 GB/s | 51.2 GB/s | 42.6 GB/s | 32 GB/s |
| IMC Clock Speed | On Die | 2 GHz | 1.8 GHz | 2 GHz |
| Interconnect |
2x QPI 2.0 8 GT/s |
4x HT 3.1 6.4 GT/s |
4x HT 3.1 6.4 GT/s |
2x QPI 4.8-6.4 GT/s |
| Transistors | 2.26 B | 2x 1.2 B | 2x 0.9 B | 1.17 B |
| Die Size mm2 | 416 | 2x 315 | 2x 346 | 248 |
As well as the subsequent pricing difference:
| Intel vs. Intel 2-socket SKU Comparison | |||||||||
|
Xeon 5600 |
Cores/ Threads |
TDP |
Clock (GHz) |
Price |
Xeon E-5 |
Cores/ Threads |
TDP |
Clock (GHz) |
Price |
| High Performance | High Performance | ||||||||
| 2690 | 8/16 | 135W | 2.9/3.3/3.8 | $2057 | |||||
| X5690 | 6/12 | 130W | 3.46/3.6/3.73 | $1663 | 2680 | 8/16 | 130W | 2.7/3.1/3.5 | $1723 |
| 2670 | 8/16 | 115W | 2.6/3/3.3 | $1552 | |||||
| 2665 | 8/16 | 115W | 2.4/2.8/3.1 | $1440 | |||||
| X5675 | 6/12 | 95W | 3.06/3.33/3.46 | $1440 | |||||
| X5660 | 6/12 | 95W | 2.8/3.06/3.2 | $1219 | 2660 | 8/16 | 95W | 2.2/2.6/3.0 | $1329 |
| X5650 | 6/12 | 95W | 2.66/2.93/3.06 | $996 | 2650 | 8/16 | 95W | 2/2.4/2.8 | $1107 |
| Midrange | Midrange | ||||||||
| E5649 | 6/12 | 80W | 2.53/2.66/2.8 | $774 | 2640 | 6/12 | 95W | 2.5/2.5/3 | $885 |
| 2630 | 6/12 | 95W | 2.3/2.3/2.8 | $612 | |||||
| E5645 | 6/12 | 80W | 2.4/2.53/2.66 | $551 | |||||
| 2620 | 6/12 | 95W | 2/2/2.5 | $406 | |||||
| E5620 | 4/8 | 80W | 2.4/2.53/2.66 | $387 | |||||
| High clock / budget | High clock / budget | ||||||||
| X5647 | 4/8 | 130W | 2.93/3.06/3.2 | $774 | 2643 | 4/8 | 130W | 3.3/3.3/3.5 | $885 |
| E5630 | 4/8 | 80W | 2.53/2.66/2.8 | $551 | |||||
| E5607 | 4/4 | 80W | 2.26 | $276 | 2609 | 4/4 | 80W | 2.4 | $294 |
| Power Optimized | Power Optimized | ||||||||
| L5640 | 6/12 | 60W | 2.26/2.4/2.66 | $996 | 2650L | 8/16 | 70W | 1.8/2/2.3 | $1107 |
| 5630 | 4/8 | 40W | 2.13/2.26/2.4 | $551 | 2630L | 8/16 | 60W | 2/2/2.5 | $662 |
In my experience, workstations for research are often prebuilt, so if the system builder makes a 10% markup, this would extrapolate the prices even more. For the processors we are focusing on today, the boxed version of the X5690 sits at $1666 each and the E5-2690 is $2061 – about a 25% price difference moving up to the E5-2690. However as a system the price difference may be slightly more, when we include memory and power supplies into the mix – even more if you want to expand the functionality for new interfaces. When dealing with a personal machine, a user can often recoup the cost by selling on the old hardware, making the cost more palatable – the research group cannot do the same, and more often than not the old hardware gets passed down to experimentalists, or sits in the corner when extra CPU power is needed. That makes the price an absolute cost, rather than an upgrade difference.
Whenever I get told that a component is too expensive (a lot of users are currently berating the price of NVIDIA’s GTX Titan, for example), my response is often this:
- Look at what you are currently using, and the performance increase that the better part would give
- If time is money, calculate how much time you would save using the newer component. Convert that into a cost benefit analysis (i.e. completing a contract in 6 months rather than 7 months) as more computation can be processed.
- If the cost can be recouped over 12 months, the purchase is probably justified (depending on who finances what) and will allow you to consider another upgrade in 12 months.
It is quite rare to be in a situation where the computational time is the limiting factor in a project, although I do acknowledge that when dealing with long simulations or calculations it can be. But if you can finish analyzing results in 4 hours rather than 6, if there is an error, it can be fixed and re-run in a shorter time. Essentially the more you require computational throughput for a project, the better the cost analysis usually is.
With all this said, the proof is always going to be in the numbers – I would suggest that for each situation our readers face, to weigh up the computational aspects of their work. In research, I spent more time organizing mathematics and coding than simulating, though when simulating some of them would take a week on a GTX 480 GPU, and I would run several batches at once. If Titan was around then and could save 40% of that time, I would have plugged my research supervisor for one in an instant. Similar arguments would have been made on the non-GPU side of the research, as often we would use each other’s 16 thread machines to get stuff done (and then repeat it if there was a coding error).








44 Comments
View All Comments
jamyryals - Monday, March 4, 2013 - link
Element is an acceptable term in this case. Anyone confusing a finite element with a chemical element would do well to read up on these types of mathematical models anyways.Your other points are well made, and highlight the difficulty in creating meaningful benchmarks.
Kevin G - Monday, March 4, 2013 - link
I agree that the usage of the word element is technically correct. The thing that threw me off more was its usage in conjunction with particle. When I read that paragraph I had to do a double take to get the proper context. My issue here is just a small editorial quibble than a technical issue. :)IanCutress - Tuesday, March 5, 2013 - link
A majority of the results in the graphs (essentially all the overclocked ones) were on systems out of my control - several users from the Overclock.net HWBot team helped on that one and offered me insight into their setups. Unfortunately I do not have access to a vast array of sockets and systems for comparison.The implicit calculations have a fair few division elements per loop, as noted in the previous article where I posted the code (http://www.anandtech.com/show/6533/8) - for each timestep there are >2 divisions per node calculation. Technically the non-CS scientist might not know what is inside the silicon regarding Ivy's better divisor .
Don't forget the whole point of a review of something like this was to look at the scenario I was in. We went and ordered dual Nehalem systems (E5520s) just because of all the threads. Looking back on it now, I wish we had stuck to single processor systems based on the code we were writing.
Regarding the built-in Ivy PRNG, as noted in the previous review, the code wasn't hand written for each processor. It was written once and applied over. We didn't get extra time or money to find the best way to simulate something, we just had to simulate.
Regarding element and particle, I almost use them synonymously in the text. I like to use 'element' to describe the motion of one point in the simulation, but my Chemistry supervisor thought I was being an idiot when we were dealing with chemicals, despite my pleas that element was a CS term. He preferred the term particle as a mid-way point between the two (and also not to confuse the chemistry people reading our papers) and mentally I have equated the two, which is not always the best thing.
For XVC, I'm not sure why there is such a difference. With HT On, we have 24 threads to do 33 videos, which is one batch of 24 then another of 9 (put your turbos in where appropriate). Without HT, we're slightly faster per core (if we're lucky, or 0 if not), but we have batches of 12, 12 and then 9. Again, apply turbos where appropriate. That's just the program runs - it decides if it wants to commit one thread per video, or multiple threads per video. If it is coding more videos than half the available threads, it does one thread per video - if there is enough threads that each video can get two, it applies two. So the set of 9 videos when HT is on probably gets two threads per video, rather than one thread per video for the 9 videos when HT is off.
Ian
Kevin G - Tuesday, March 5, 2013 - link
The thing with Ivy Bridge's improved division unit is that it can explain some of the speed up. Glancing at the code, those operations don't seem to be that common that it'd make such a noticeable impact. (The real test would be to compile, disassemble and then count the number of division instructions.) The other thing about Ivy Bridge's divisor is that its performance gains are 'free' in the sense that it doesn't require rewriting or recompiling code to take advantage of. It is an architectural tweak that benefits existing code.Upon release, Nehalem was a very good platform and still respectable today. I think the issue is that consumer systems have been catching up. Looking at the charts the only consumer system that's a roughly the same age as the E5520's was an overclocked Phenom II X4's and the dual socket Xeon showed an advantage there. The problem I'm seeing is that the code isn't scaling across multiple sockets and memory controllers very well. Solving that would put performance closer to expectations. If possible, I would suggest enabling memory mirroring across sockets to see if that solves some of the scaling issues. The code wouldn't have to be written to be NUMA aware but usable memory in the system is halved.
If the NUMA problem is not practical to solve, then going single socket makes sense. Howevever, I would expand the discussion into include RAS. I would not recommend a single highly overclocked system to run scientific simulations as the reliability simply isn't there. One way around that is to get two similarly configured systems and run the simulation twice and compare the results for redunancy. With some of these heavily overclocked systems costing less than half the dual Xeon's price tag and running the code twice as fast, it is worth considering such a mirrored configuration. Other options to consider would be a single 8 core Xeon on socket 2011 or some of the quad core Xeon on socket 1155 and gain ECC memory support to forgo the second system.
The XVC results can see some improvements in queuing but those benefits should be able to carry over to the non-HT results with a software tweak. (Most software like that can accept such tuning parameters but I'm personally unfamiliar with XVC.) The results are falling outside the realm of reason. It is like say cooling a gas until you realize you're at -20 kelvin. At that point you have to realize something is erroneous. At best HT can double performance and the results are roughly five times faster. Turbo is a factor but that would benefit the non-HT results more as utilization is lower (ie. fewer transistors switching, less heat, more turbo boost).
toyotabedzrock - Monday, March 4, 2013 - link
I looks like Intel forgot about HT on sandy bridge.IanCutress - Tuesday, March 5, 2013 - link
i5-2500K is a 4C/4T processor.Ian
TeXWiller - Monday, March 4, 2013 - link
Ian, have you tried playing with the numa options of the boards?IanCutress - Tuesday, March 5, 2013 - link
NUMA was enabled in the BIOS, I made sure before I tested :) I also looked at various ways to keep the top turbo in force through all loading, but the limited BIOS options relating to clock speed on server boards are not up to scratch compared to consumer products (as you would expect).Ian
TeXWiller - Tuesday, March 5, 2013 - link
I was thinking about the improved bandwith between the processors in E5 family. Some aplications might prefer node interleaved memory instead.alpha754293 - Monday, March 4, 2013 - link
re: OpenMP vs. MPIMultithreaded codes using OpenMP is known to be quite a lot slower than a proper, MPI code. In the testing that I've done, the difference can be as much as 40% because the OpenMP code just simply cannot keep the CPU/FPU units occupied long enough. I've never really dug in deep as to WHY that is (I'm sooo NOT a programmer), but as an end user; that a HUGE difference.
Secondly, also depending on how you write your MPI code - some of them can be VERY efficient at using multicore/multiprocessors. It depends on the code, the nature and physics of the problem, and a whole bunch of other things. (LS-DYNA for example scales VERY well to the number of processors and/or cores. And my research is showing about an 11-17% benefit with HTT enabled on a 3930K (I don't have 8-core Xeons to play with). :(
Conversely, I've also seen some MPI codes that don't really quite parallelize nearly quite as well. It SAYS that it's MPI, but it looks more like an OpenMP implementation for the parallelization.
Part of it also depends on how much data dependency there is - does the information of one depend on the results or the information/data of another (either on spatial or temporal terms)?
Third - I've had many arguments about this. A single socket, multi-core processor is still a parallel multicore system. Yes, you don't have to deal with NUMA, but unless you have a LOT of traffic going through between your two sockets (something which NO ONE has been able to tell me how to measure so far) - chances are, both either OpenMP OR MPI can scale to single multi-core processor, or multiple multi-core processors. It shouldn't really care (unless you've hard-coded the domain decomposition and the number of "partitions" or "divisions" it makes for the parallelization.)
I think that the statement/comment that you wrote about how some of the benchmarks or some types of simulations/processes favour a single-CPU setup isn't QUITE exactly accurate only because your single-socket, multi-core CPUs were quite highly overclocked. (I've got my 3930K up to 4.5 GHz, and I just re-enabled C1E/EIST in order to cut my idle power consumption).
[brb...to be continued]