The iPhone 5s Review
by Anand Lal Shimpi on September 17, 2013 9:01 PM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone
- iPhone 5S
CPU Performance
For our cross-platform CPU performance tests we turn to the usual collection of Javascript and HTML5 based browser tests. Most of our comparison targets here are smartphones with two exceptions: Intel's Bay Trail FFRD and Qualcomm's MSM8974 Snapdragon 800 MDP/T. Both of those platforms are test tablets, leveraging higher TDP silicon in a tablet form factor. The gap between the TDP of Apple's A7 and those two SoCs isn't huge, but there is a gap. I only include those platforms as a reference point. As you're about to see, the work that Apple has put into the A7 makes the iPhone 5s performance competitive with both. In many cases the A7 delivers better performance than one or both of them. A truly competitive A7 here also gives an early indication of the baseline to expect from the next-generation iPad.
We start with SunSpider's latest iteration, measuring the performance of the browser's js engine as well as the underlying hardware. It's possible to get good performance gains by exploiting advantages in both hardware and software here. As of late SunSpider has turned into a bit of a serious optimization target for all browser and hardware vendors, but it can be a good measure of an improving memory subsystem assuming the software doesn't get in the way of the hardware.

Bay Trail's performance crown lasted all of a week, and even less than that if you count when we actually ran this benchmark. The dual-core A7 is now the fastest SoC we've tested under SunSpider, even outpacing Qualcomm's Snapdragon 800 and ARM's Cortex A15. Apple doesn't quite hit the 2x increase in CPU performance here, but it's very close at a 75% perf increase compared to the iPhone 5. Update: Intel responded with a Bay Trail run under IE11, which comes in at 329.6 ms.
Next up is Kraken, a heavier js benchmark designed to stress more forward looking algorithms. Once again we run the risk of the benchmark becoming an optimization target, but in the case of Kraken I haven't seen too much attention paid to it. I hope it continues to fly under the radar as I've liked it as a benchmark thus far.
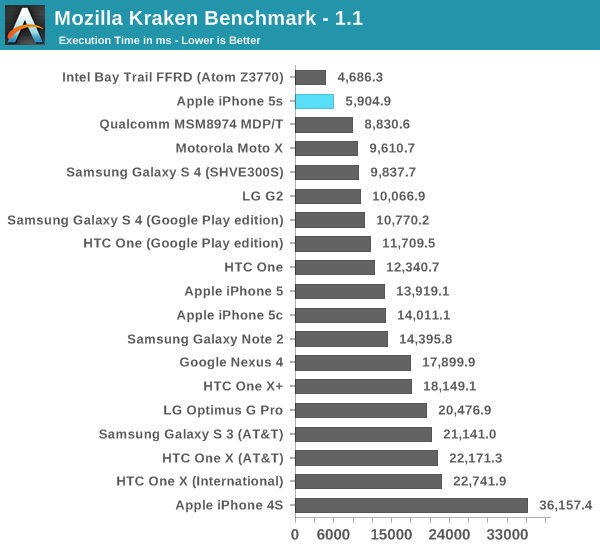
The A7 falls second only to Intel's Atom Z3770. Although I haven't yet published these results, the 5s performs very similarly to an Atom Z3740 - a more modestly clocked Bay Trail SKU from Intel. Given the relatively low CPU frequency I'm not at all surprised that the A7 can't compete with the fastest Bay Trail but instead is better matched for a middle of the road SKU. Either way, A7's performance here is downright amazing. Once again there's a performance advantage over Snapdragon 800 and Cortex A15, both running at much higher peak frequencies (and likely higher power levels too, although that's speculation until we can tear down an S800 platform and a 5s to compare).
Compared to the iPhone 5, the 5s shows up at over 2.3x the speed of last year's flagship.
Next up is Google's Octane benchmark, yet another js test but this time really used as a design target for Google's own V8 js engine. Devices that can run Chrome tend to do the best here, potentially putting the 5s at a disadvantage.
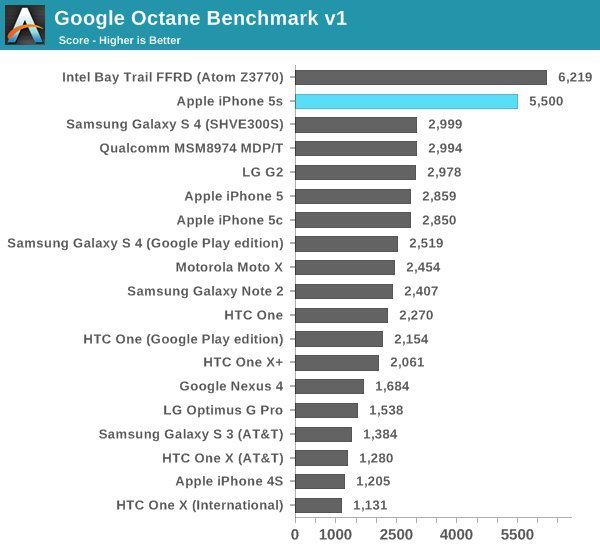
Bay Trail takes the lead here once again, but again I expect the Z3740 to be a closer match for the A7 in the 5s at least (it remains to be seen how high the iPad 5 version of Cyclone will be clocked). The performance advantage over the iPhone 5 is a staggering 92%, and obviously there are big gains over all of the competing ARM based CPU architectures. Apple is benefitting slightly from Mobile Safari being a 64-bit binary, however I don't know if it's actually getting any benefit other than access to increased register space.
Our final browser test is arguably the most interesting. Rather than focusing on js code snippets, Browsermark 2.0 attempts to be a more holistic browser benchmark. The result is much less peaky performance and a better view at the sort of moderate gains you'd see in actual usage.

There's a fair amount of clustering around 2500 with very little differentiation between a lot of the devices. The unique standouts are the Snapdragon 800 based G2 from LG, and of course the iPhone 5s. Here we see the most modest example of the A7's performance superiority at roughly 25% better than the iPhone 5. Not to understate the performance of the iPhone 5s, but depending on workload you'll see a wide range of performance improvements.








464 Comments
View All Comments
ddriver - Wednesday, September 18, 2013 - link
My basis for this conclusion is how the article is structured, the carefully picking of benchmarks and selective comparisons. This is clearly visible and has nothing to do with the actual chip specifications. It has nothing to do with execution mode specific details. So no, I don't have problem with facts, unlike you.Furthermore, that 30% number you were focused on is hardly impressive and proportional to the claims this article is making. In a workload that would take an hour, 30% is a noticeable improvement, but for typical phone applications this is not the case.
Dooderoo - Wednesday, September 18, 2013 - link
The structure of the article and the benchmarks are mostly the same as they use in most reviews, excluding some Android specific benchmarks. Where exactly do you see "carefully picking of benchmarks and selective comparisons". Put differently: what benchmarks should they include to convince you there is no "cunning deceit" at work?What claims in the article are not proportional with the 30% (actually more) performance gain?
I won't even comment on the "not a noticeable improvement" bit.
andrewaggb - Wednesday, September 18, 2013 - link
My issue with all the benchmarks is that they are mostly synthetic. The most meaningful benchmarks are the applications you plan to use and the usage patterns you are targeting. Synthetics are fascinating, but I think it's generally a mistake to buy anything based on them.notddriver - Thursday, September 19, 2013 - link
Um, so if a 30% improvement is hardly impressive and irrelevant to phones, then isn't the entire concept of reviewing phones on the basis of hardware performance also irrelevant? Which would make your complaints about the biased-yet-insignificant-review as vital as a debate over whether Harry Potter or Spiderman would be better at defending Metropolis.Incidentally, my iPhone 5 is powerful enough that I never notice any issues—as I'm sure the last generation of Android phones would be. But if your going to go to town over a dozen or more comments about a topic, at least pretend that it matters a tiny bit. Just good form.
oRdchaos - Wednesday, September 18, 2013 - link
I've seen people all over the web get very worked up about people's phrasing with regard to 64-bit. Would you prefer the title of the section were "Performance gains from a 64-bit architecture and the new ARMv8 instruction set"? People keep arguing that 64-bit in a vacuum doesn't give much performance gain. But there is no vacuum.I think the article is very clear to point out where gains are from additional instructions, versus a doubling of the register bit width, versus improved memory subsystem/cache. I'm sure when they get chances to write more of their own tests, they'll be able to pinpoint things further.
sfaerew - Wednesday, September 18, 2013 - link
engadget is multi-thread geekbench performance. tegra4 4cores vs A7 2coresSpoony - Wednesday, September 18, 2013 - link
- You are correct, there are no native cross-platform benches used. Which ones do you suggest Anandtech use? We all know Geekbench is essentially meaningless across platforms.- If you are talking about this engadget review: http://www.engadget.com/2013/09/17/iphone-5s-revie... It appears that Nvidia SHIELD (Tegra 4) led in only one benchmark out of six. This makes your statement incorrect. LG G2 is more competitive. Need we repeat how inaccurate Geekbench is cross-platform. It is as apples-to-oranges as the JS tests.
- I believe what Anandtech was attempting to show with the encryption was the difference ARMv8 ISA makes. In fact the title of that somewhat sensational chart is "AArch64 vs. AArch32 Performance Comparison". So while you are right, the encryption tests are handled in a fundamentally different way, that way is part of the ISA and is an advantage of AArch64, and thus is valid in the chart.
- It will be curious to see whether Qualcomm can deliver A7 like performance using ARMv7 with extended features. My position is no, which is the whole point of that entire page of the review. ARMv8 is actually enabling some additional performance due to ISA efficiency and more features.
- I think noticeable memory footprint bloat of a 64-bit executable is completely ridiculous. But to see if I was right, I did some testing. It's getting a bit hard to find fat binaries to take apart these days, most things are x86_64 only. But I found a few. I computed for three separate applications, took the average, and it looks like about a 9% increase in executable size. Considering that executables themselves are a tiny part of any application's assets, I think it is completely insubstantial. If you calculate the increase in executable size versus the size of the whole application package, it averages to a less than 1% increase.
I too am a bit sad that Apple didn't increase the RAM, and also equally sad that connectivity was left out this rev. I continue to be sad that there is not a more serious storage controller inside the phone. You make some valid points, but I think you also make some erroneous ones. The question with phone SoCs is: Is this a well balanced platform along the axes of performance (GPU and CPU), power consumption (thus heat), and features. I believe that the A7 is well calibrated. Obviously Qualcomm is also doing great work, and perhaps their SoCs are equally as well calibrated.
ddriver - Wednesday, September 18, 2013 - link
- This is entirely his decision, considering writing those reviews is his job, not mine. He can either use actual native benchmarks which reflect the performance of the actual hardware, or call it JS VM performance instead of CPU performance, because different JS implementations across platforms are entirely meaningless.- there is only one geekbench test at engadged. That is what I said "geekbench" - I did not imply it was faster in all tests in the engadged review, I don't know why you insinuate I did so. IIRC snapdragon 800 is actually a little slower in the CPU department than tegra 4, and only faster in the graphics department.
- the boost in encryption is completely disproportional to other improvements and is due to hardware implementations, not 64bit execution mode. So, if anything, it should be a graph or chart on its own, instead of using it to bulk up the chart that is supposed to be indicative of integer performance improvements in 64bit mode.
- maybe v7 chips with 128 bit SIMD units will not deliver quite the performance of A7, because there is more to the subject than the width of the registers (the number of registers doesn't really matter that much), like supported instructions. At any rate, v7 chips are still quad core, which means 4x128bit SIMD units compared to the 2 on A7, albeit with a few extra supported instructions. Until any native benchmark that guarantees saturation of SIMD units pops out, it will be a foolish thing to make a concrete statement on the subject. But boosting v7 SIMD units to 128bit width will at least make it competitive in number crunching scenarios, which use SIMD 99% of the time.
- this is very relative, you can store the same data in three different containers and get a completely different footprint - a vector will only use a single pointer, since it is continuous in memory, a forward list will use a pointer for every data element, a linked list will use two. Depending on the requirements, you may need faster arbitrary inserts and deletions, which will require a linked list, and in the case of a single byte datatype, a 32bit single element will be 12 bytes because of padding and alignment, while in 64bit mode the size will grow to 24 bytes, which is exactly double. Granted, this is the other extremity of the "less than 1%" you came up with, truth is results will vary in between depending on the workload.
As I said in the first post, the wise thing would be to reserve judgement until mass availability, mostly because I know corporate practices involving exclusive reviews prior to availability, which are a pronounced determining factor to the initial rate of sales. In short, apple is in the position to be greatly rewarded for imposing some cheating requirements on early exclusive reviewers. And at least in this aspect I think everyone will disagree, apple is not the kind of company to let such an opportunity go to waste.
ddriver - Wednesday, September 18, 2013 - link
*no one will disagreeDug - Wednesday, September 18, 2013 - link
I will."As I said in the first post, the wise thing would be to reserve judgement until mass availability, mostly because I know corporate practices involving exclusive reviews prior to availability, which are a pronounced determining factor to the initial rate of sales. In short, apple is in the position to be greatly rewarded for imposing some cheating requirements on early exclusive reviewers. And at least in this aspect I think everyone will disagree, apple is not the kind of company to let such an opportunity go to waste."
Prove it and stop making assumptions.