ARM’s Mali Midgard Architecture Explored
by Ryan Smith on July 3, 2014 11:00 AM EST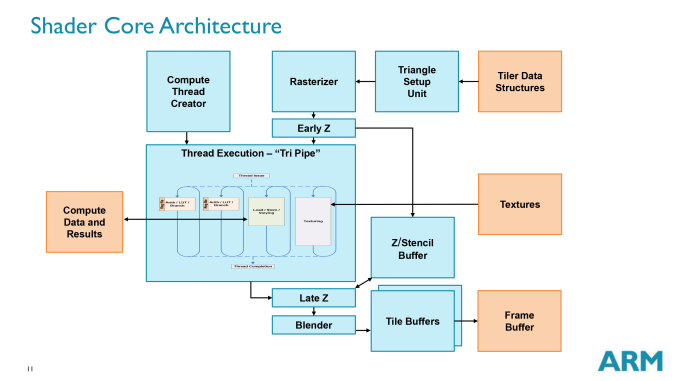
So far this is shaping up to be a banner year for SoCs. From a market perspective the mobile hardware space is still in a period of significant growth, but more importantly from a hardware point of view these products and especially the GPUs in these products have made significant strides in performance and in features. SoC GPUs will approach feature parity with desktop GPUs this year, and from a performance perspective they’re nearing the performance of the last-generation game consoles, a long-aspired goal given the “good enough” status attached to those devices.
Meanwhile at the same time that these products are maturing at a technical level, we’ve seen the various SoC firms mature at a professional level. The “wild west” days of SoCs have given way to mature markets of longer product cycles, longer product lives, and a more stable market overall. This both good and bad news for the various players in the SoC market as firms get squeezed out – SoC integrators such as TI and STMicroelectronics have been the first of such victims – but it also means that as companies become better established and more deeply entrenched, they can be more open about their projects and their products, and discuss them in greater detail than before without needing to be concerned about getting scooped by a competitor.
Here at AnandTech we’re particularly fond of doing architectural deep dives; our chance to talk to the people behind various processors and learn from them about how their products work and how they came together. Thanks to the maturation of the SoC market we’re finally getting a level of access in the SoC market that we haven’t had before, and in turn for the first time we get to tell the stories of the people behind these mind-bogglingly complex devices while better learning how they operate and as such how they compare. It’s admittedly a level of access we take for granted in the PC space, where companies such as Intel, AMD, and NVIDIA are regularly open, but it’s hard to contain our excitement about gaining this kind of access to the myriad of players in the SoC space.
This year then has been especially productive in that regard, and as of today it’s going to get even better. After we took a look at Imagination’s PowerVR Rogue architecture earlier this year, ARM contacted us and indicated that they would like to do the same; that they would like to take a seat at the “open architecture” table. To give us the access we need to discover how their GPUs work, and in turn tell you what we’ve learned.

To that end we’ve gladly let ARM pull up a seat, and today we’ll be taking our first in-depth look at ARM’s newest Mali SoC GPU architecture: Midgard. Now as with Imagination what we’re seeing today is most, but not all of the picture, as ARM has their secrets and they wish to keep some of them. But today we get to learn all about Midgard’s shader cores while also learning a thing or two about its pixel rendering pipeline, power optimizations, and other aspects of what makes Midgard tick. In other words, more than enough to keep us busy for one day.
But before we dive in we’d also like to quickly call attention to an Ask The Experts session we held with ARM’s Jem Davies, an ARM Fellow and VP of Technology in the Media Processing Division. While our deep dive is focusing on Midgard’s architecture, Jem has been answering all sorts of additional Mali-related questions, including business strategy and ARM’s views on GPU computing.
Finally, as this is the second article in our continuing series on SoC GPUs, we will be picking up from where we left off after our last article. While all of our articles are meant to be accessible to some degree, if you haven’t caught any of our previous articles I’d highly recommend our primer on how GPUs work for a quick overview of the technology before we dive into the nuts and bolts of ARM’s Midgard architecture.








66 Comments
View All Comments
kkb - Monday, July 7, 2014 - link
I hope you do understand how to read benchmark results. 3dmark and GFXbench(offscreen) results are resolution independent. Now go and check the results in the article.As per T760, I will not comment on theoretical GFLOP numbers unless there is real product. Even the theoretical MAD GFLOPs are not so great (roughly half) compared to others. I don't think anyone going to fall for marketing gimmick of taking dot product also as extra 40 GFLOPs
darkich - Monday, July 7, 2014 - link
You said it definitely performs better yet it loses on the T Rex HD onscreen and in Basemark X overall. That's not definite you know.Regardless, even if a case can be made that it performs slightly better overall than the Mali T628, it is without doubt outperformed by the :
ULP Gforce 3
Adreno 330
Sgx G6320
.. and is *definitely* far outclassed by the Adreno 420, Kepler K1, SGX G6550, Mali T760MP6-10.
Until Intel shows their next generation of ULP graphics, I don't see a point in comparing the current one
darkich - Monday, July 7, 2014 - link
Correction, I believe the GPU in Tegra 4 is internally referred to as the ULP GeForce 4, not 3fithisux - Friday, July 4, 2014 - link
Could you provide an expository of C66x architecture since it is suitable in my opininion for GPGPU tasks and realtime software rendering/raytracingjann5s - Friday, July 4, 2014 - link
lol, I thought this expression was wrong: "the proof is in the pudding", but in fact I was wrong: http://en.wiktionary.org/wiki/the_proof_is_in_the_...toyotabedzrock - Friday, July 4, 2014 - link
I wish you would have talked more about the GPU in the Nexus 10 since that is a shipping product. It would be nice to know how it differs from the newer midgard designs.seanlumly - Friday, July 4, 2014 - link
Another interesting point to make about the Mali architecture (that goes unnoticed, but is significant) is that the anti-aliasing is fully pipelined, tiled (read zero bandwidth penalty for the op), and very fast. MSAA 4x costs 1 cycle, MSAA 8x costs 2 cycles, and MSAA 16x costs 4 cycles. This means that if you have a scene full of fragment shaders running for more than 4 cycles (which is not too complex these days) you get the benefit of ultra-high quality MSAA 16x for FREE.There aren't too many examples of MSAA 16x online, but even at MSAA 8x performs very well, with sharp, non-blurry results and is often compared against. MSAA would produce very crisp edges devoid of aliasing and crawling during animation.
Of course, MSAA isn't perfect -- it isn't terribly helpful for deferred renderers -- but it certainly doesn't hurt them when its costs are nothing, even if you are planning to do a screen-space pass in post.
toyotabedzrock - Friday, July 4, 2014 - link
Oddly the best open source driver is for adreno GPU, perhaps you should ask that person what he knows about it?ol1bit - Saturday, July 5, 2014 - link
This is another fantastic job guys! Thanks to you and Thanks to Midgard for sharing!cwabbott - Saturday, July 5, 2014 - link
Well, if they won't cough up the information, then there's always freedreno... Rob Clark has reverse engineered basically everything you would want to know about the Adreno architecture, up to even more detail than this article. All that remains is to fill in the pieces based on the documentation he's written...