Original Link: https://www.anandtech.com/show/1432
Linux Shootout: Opteron 150 vs. Xeon 3.6 Nocona
by Kristopher Kubicki on August 12, 2004 2:35 PM EST- Posted in
- Linux
Our preliminary look at Intel's 64-bit Xeon 3.6GHz Nocona (which happens to be identical to the Intel 3.6F Pentium 4) stirred up a bit of controversy. The largest two concerns were:
- We tested Intel's Xeon server processor against an Athlon desktop CPU.
- We chose poor benchmarks to illustrate the capabilities of those processors.
Fortunately, with the help of the other editors at AnandTech, we managed to reproduce an entire retest of the Nocona platform and an Opteron 150 CPU. We also managed to find an internet connection stable enough for this editor to redraft en entire performance analysis on his vacation.
| Performance Test Configuration | |
| Processor(s): | AMD Opteron
150 (130nm, 2.4GHz, 1MB L2 Cache) Intel Xeon 3.6GHz (90nm, 1MB L2 Cache) |
| RAM: | 2 x 512MB PC-3200 CL2 (400MHz) Registered 2 x 512MB PC2-3200 CL3 (400MHz) Registered |
| Memory Timings: | Default |
| Operating System(s): | SuSE 9.1 Professional (64 bit) Linux 2.6.4-52-default Linux 2.6.4-52-smp |
| Compiler: | linux:~ # gcc -v Reading specs from /usr/lib64/gcc-lib/x86_64-suse-linux/3.3.3/specs Configured with: ../configure --enable-threads=posix --prefix=/usr --with-local-prefix=/usr/local --infodir=/usr/share/info --mandir=/usr/share/man --enable-languages=c,c++,f77,objc,java,ada --disable-checking --libdir=/usr/lib64 --enable-libgcj --with-gxx-include-dir=/usr/include/g++ --with-slibdir=/lib64 --with-system-zlib --enable-shared --enable-__cxa_atexit x86_64-suse-linux Thread model: posix gcc version 3.3.3 (SuSE Linux) |
| Libraries: | linux:~ # /lib/libc.so.6
GNU C Library stable release version 2.3.3
(20040405), by Roland McGrath et al.
Copyright (C) 2004 Free Software Foundation,
Inc.
This is free software; see the source for
copying conditions.
There is NO warranty; not even for MERCHANTABILITY
or FITNESS FOR A
PARTICULAR PURPOSE.
Configured for i686-suse-linux.
Compiled by GNU CC version 3.3.3 (SuSE
Linux).
Compiled on a Linux 2.6.4 system on 2004-04-05.
Available extensions:
GNU libio by Per Bothner
crypt add-on version 2.1 by Michael
Glad and others
linuxthreads-0.10 by Xavier Leroy
GNU Libidn by Simon Josefsson
NoVersion patch for broken glibc
2.0 binaries
BIND-8.2.3-T5B
libthread_db work sponsored by
Alpha Processor Inc
NIS(YP)/NIS+ NSS modules 0.19 by
Thorsten Kukuk
Thread-local storage support included.
Report bugs using the `glibcbug' script
to |
The Intel Xeon 3.6GHz has HyperThreading enabled by default, so we use that
with the SMP kernel during the review. The entire review uses 64-bit binaries
either compiled from scratch or as installed from RPM. We only used a 32-bit
benchmark during the synthetic analysis, but still on SuSE 9.1 Pro (x86-64).
As one reader has pointed out, the GCC 3.3.3 used in this review has a few back ported optimizations from GCC 3.4.1 care of the SuSE development team. Thus, architecture specific optimizations for nocona are included.
Special thanks to Super Micro for getting us additional Intel components
for testing on such short notice!
MySQL
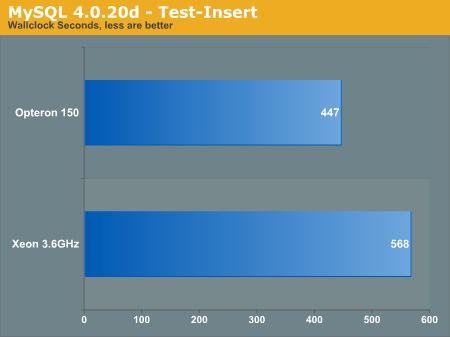
We ran two free, open sourced database benchmarks for this portion of the analysis. The first uses MySQLd 4.0.20d installed from x86_64 RPM; precompiled by the SuSE team. We ran the test-select and test-insert sql-bench exams.

Postgres
Adding Postgres to the SQL benchmarks was fairly easy. Although this may not be the most optimized way to benchmark Postgres, our time was limited. We installed the DBD-pg Perl library, and then reran our sql-bench results as above in the MySQL tests Postgres was started with the "-o - F" flags.

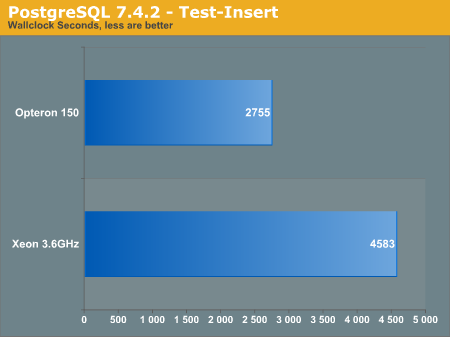
Remember, even though times are significantly longer in this benchmark, they do not show whether or not one database is faster than the other. However, there are some extreme conclusions we can draw from this test. The Opteron 150 really advances over the Xeon processor in this benchmark. We have shown in previous reviews that HyperThreading seems to hurt MySQL performance as some unnecessary threading probably occurs.
TSCP
We apologize for the broken TSCP Makefile in the previous review which rendered our initial results inaccurate. Fortunately we posted the file so that others were able to detect the error and not find fault with the processors instead. The large issue many of our readers have brought to our attention are the severe difference in performance between various optimizations. Below you can see how various compile flags affected our benchmark scores.
The first benchmark is run with the optimization flags:
-O2 -funroll-loops -frerun-cse-after-loop
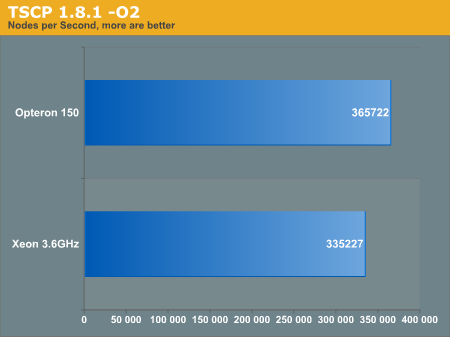
The next benchmark is run with the optimization flags:
-O3 funroll-loops -frerun-cse-after-loop
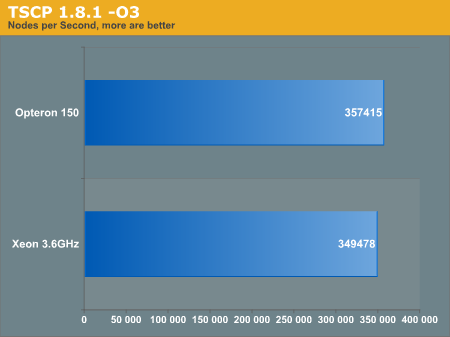
Finally, we have the architecture optimized flags as well:
(Intel) -O3 - march=nocona -funroll-loops -frerun-cse-after-loop
(AMD) -O3 - march=k8 -funroll-loops -frerun-cse-after-loop
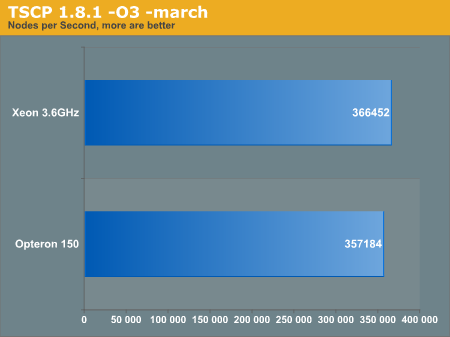
You are reading these charts correctly, the O3 flag actually penalizes the AMD CPU. We also compiled the program with -O2 -march=k8 but we got virtually the same score with or without the march flag.
We were informed others have been capable of much faster nodes per second using GCC 3.4.1 and the flagset:
-O3 -march=athlon-xp -funroll-loops -fomit-frame-pointer -ffast-math -fbranch-probabilities
We did not have time to fully test GCC 3.4.1, although there is a strong likelihood that 3.4 encourages better optimizations (particularly on the x86_64 platforms).
Crafty
For good measure, we have included Crafty into our chess benchmarks section. Crafty was only built using the "make linux-amd64" target. From the Makefile, it seems as though the "AMD64" moniker is slightly inappropriate. The target claims:
# -INLINE_AMD Compiles with the Intel assembly code for FirstOne(), # LastOne() and PopCnt() for the AMD opteron, only tested # with the 64-bit opteron GCC compiler.
The benchmark was generated by running the "bench" command inside the program.
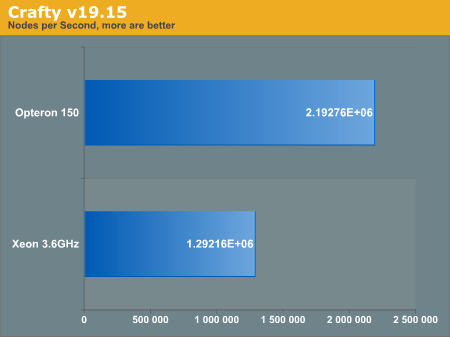
It is clear the difference between both processors is quite severe in this instance. Although it is difficult to pin an exact culprit, there are likely multiple arch optimizations were left untapped, and thus our reasoning for discouraging overusage of optimizations in general.
Mental Ray
Between Mental Ray and POV-Ray, we should see our largest taxing of the floating point in a real world scenario.
We ran Mental Ray 3.3.3 from the command line on the same benchmark file we have been using in the past. Unfortunately we do not have access to 64-bit Maya/Mental Ray binaries at this time, but we are working with AW.
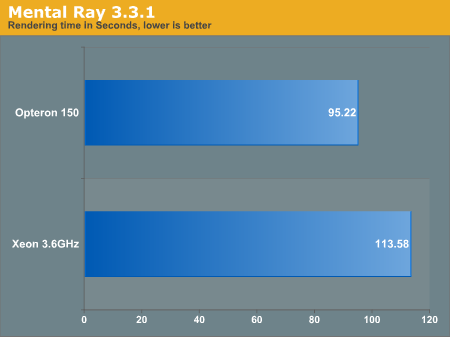
The Opteron outperforms the Nocona in this benchmark but we would like to see x86_64 tests in the future.
POV-Ray
POV-Ray was installed from RPM, and then run against the official benchmark.ini.
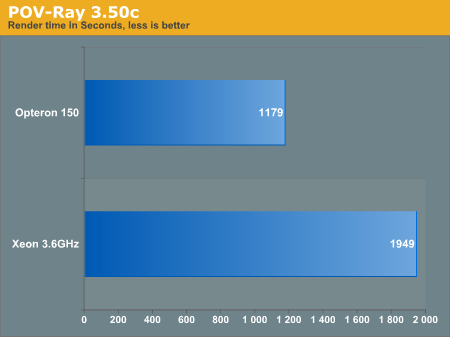
As we can see above, the difference between the two CPUs seems exaggerated and difficult to trust. We are working with the POV-Ray team to determine why the differences are so dramatic.
Opstone
Since our use of Ubench in the previous article clearly infuriated many people, we are going to kick that benchmark to the side for the time being until we can decide a better way to implement it.
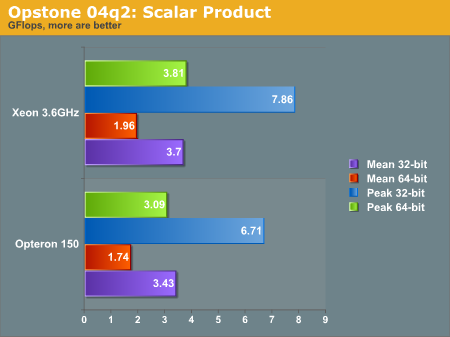
In the meantime, a reader suggested we give Blue Sail Software's Opstone benchmarks a try. In this portion of the review, we will use their precompiled optimized binaries of the Scalar Product (SP) and Sparce Scalar Product (SSP) benchmark. The SP benchmark is explained by the author:
"The 'SP' benchmark calculates the scalar product (dot product) of 2 vectors ranging in size from 16 elements to 1048576 elements for both single and double-precision floats. Although the Gflops/sec. for every vector length is recorded (in the resulting output log file), the average of all these values is reported. This benchmark is indicative of the performance of many raw floating-point data processing apps (movie format conversion, MP3 extraction, etc.)"
Note that we ran the P4 optimized binaries on the Nocona, which did not provide x86-64 enhancements. Running the AMD64 binaries on the Xeon yielded poor results. The P4 Opstone binaries are the only 32-bit binaries used in this analysis.
Below is the SSP benchmark, as explained by the author:
"The 'ssp' benchmark also calculates the scalar product of 2 vectors, except that these vectors are sparsely populated (only the non-zero value elements are stored) ranging from a 'loading factor' (non-zero/zero elements) of 0.000001 to 0.01 for both single and double-precision floats. Since the data is not contiguous in memory, the performance is much lower than regular 'sp' and is measured in Mflops/sec. There is not much difference in performance between different loading factors as this benchmark really challenges the ability of the processor to perform short bursts of calculations coupled with lots of conditional testing. It is this reason that the P4 with its longer pipeline does not generally perform as well as the Athlon64. This benchmark is indicative of the performance of many 3D games as the processing is similar (short bursts of calculations with numerous conditional testing)"
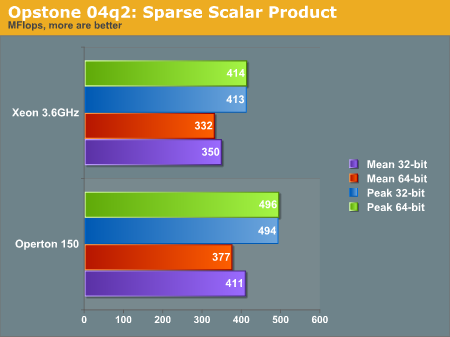
There is a general distrust of synthetic benchmarks, so take this portion of the analysis only with a grain of salt. We see a tale of two processors in these graphs; generally the Xeon performs better in the raw operation SP benchmark, while the Opteron performs better in the condition testing SSP benchmark. We would be lead to believe the Intel processor does content integer content creation better than the Opteron, and visa versa with floating point applications. However as we see in the rest of the review, this is not always the case.
lame
If our other benchmarks were any indication, compiler flags seem to make or break our analysis of a processor. However, lame 3.96.1 seemed one of those programs that did not readily enjoy optimizations; at least with the test file we used. When we attempted to force any optimization, even - march or - O2, lame appeared to produce the same or worse results.
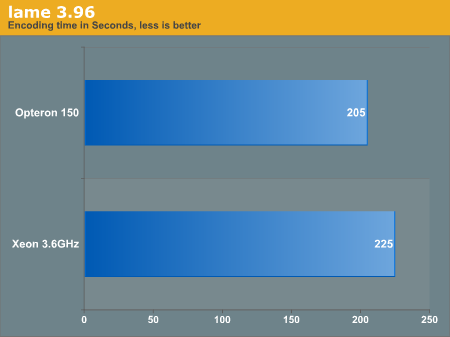
GZip
GZip was installed straight from RPMs, so optimization flags are probably minimal. We used the 700MB test file from the lame encoding test as dummy data.
# time gzip -c sample.wav > /dev/null
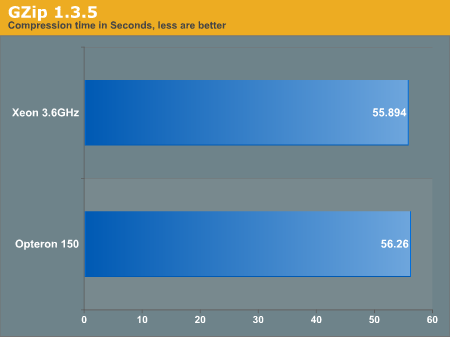
This becomes our first real world test where we see Intel come out ahead. This coincides with what we saw on the previous page with the synthetic benchmark.
John The Ripper
We are using John the Ripper 1.6.37 in this portion of the benchmark. As a few extremely knowledgeable readers pointed out, the "stable" 1.6 branch of code relies heavily on hand coded ASM which by today's standards is fairly ancient anyway. Using the "development" branch, we are able to tweak the options enough to get away from any ASM.
However, if our chess benchmarks were any indicator, optimization flags tend to skew the results dramatically. As a result, we run three trials of the John the Ripper (JTR) benchmark each using different compile flags. Configuration 1 is in the standard "make linux-x86-64" target.
- Configuration 1.) -O2
- Configuration 2.) -O3
- Configuration 3.) -O3 - march=k8 or - march=nocona
![John The Ripper 1.6.37 - DES [64/64 BS]](https://images.anandtech.com/graphs/linux shootout opteron 150 vs _081104100823/3537.png)
![John The Ripper 1.6.37 - Blowfish (x32) [32/64]](https://images.anandtech.com/graphs/linux shootout opteron 150 vs _081104100823/3538.png)
![John The Ripper 1.6.37 - MD5 [32/64 X2]](https://images.anandtech.com/graphs/linux shootout opteron 150 vs _081104100823/3539.png)
From looking at the graphs, it becomes easy to see why JTR makes a difficult program to use as a benchmark. Pay careful attention to each benchmark, particularly in between the -O2 and -O3 compile options.
OpenSSL
We couldn't think of a good way to post the OpenSSL benchmarks, so we just put both comparisons into text files which you may download here (AMD) and here (Intel). The reader is left to draw their own conclusions.
Although this latest attempt to produce an accurate, unbiased, real world comparison of these two processors is likely more thorough than the review earlier this week, there are still critical issues we will address to get out of the way.
First of all, AMD's Opteron 150 is the highest performing AMD workstation CPU money can buy. Thus, it is priced around $600 at time of publication. (The nearly identical FX-53 is priced slightly higher). Intel's Xeon 3.6GHz / Pentium 4 3.6F processor is the highest performing Intel workstation CPU money can't buy; although it has shown up in various OEM channels, it really has not hit the market in full force yet. When it does, we are expected to see it retail for $850. This automatically raises the question as to whether or not these two are directly competing processors. Since prices in the market fluctuate daily depending on vendor stock with such high end CPUs, we leave that decision up to the reader.
Secondly, GCC 3.3.3 optimizations became a larger than expected variable in these tests. As shown in the TSCP benchmark, changing the optimization flags wildly changed performance of the Opteron CPU, while the Nocona only received mild benefits. We also hear that GCC 3.4 tends to increase performance on the Opteron CPUs even further, although we ran out of time to complete that test.
After all is said and done it became difficult (nearly impossible?) to justify the Xeon processor in a UP configuration over the Opteron 150, but perhaps we will see significant changes in dual and four way configurations. We have Linux benchmark shootout between the two processors coming up, as well as a Windows analysis too.
Once again special thanks to Super Micro for providing us with the hardware on such short notice for this review.






