Original Link: https://www.anandtech.com/show/1463
GPU Cheatsheet - A History of Modern Consumer Graphics Processors
by Jarred Walton on September 6, 2004 12:00 AM EST- Posted in
- GPUs
Introduction
After the overview of modern Intel and AMD processors, there were many requests for a similar article covering the graphics arena. "Arena" is a great term to describe the market, as few other topics are as likely to raise the ire of the dreaded fanboy as discussing graphics. However, similar to the CPU Guide, this article is not meant as a set of benchmarks or to answer the commonly asked question of "which graphics card is best?" Instead, it is a look at the internal designs, feature sets, and theoretical performance of various graphics chips.
The initial scope of this article is limited to graphics chips manufactured by ATI and NVIDIA. This is not to say that they are the only companies making 3D graphics chips, but honestly, if 3D gaming is your area of interest, there really aren't any other good alternatives. The integrated graphics in VIA, Intel, and SiS chipsets are, at best, disappointing. They're fine for business use, but businesses don't generally worry about graphics performance anyway, as anything made within the past five years is more than sufficient for word processing and spreadsheet manipulation. Matrox is still heralded by many as the best 2D image quality, but again, for gaming - the primary concern of anyone talking about consumer 3D graphics cards - they simply fall short. It's too bad, really, as more competition almost always benefits the consumer, but computer hardware is a very cutthroat market - one seriously botched release, and it may be your last!
However, not all ATI and NVIDIA chips will be covered. If the Volari and DeltaChrome have issues with current games, the same can be said of old Rage and TNT graphics cards, only more so. Even the early GeForce and Radeon chips are too slow for serious gaming, but since they are DirectX 7 parts, they have made the cut. So, similar to the CPU Guide, all GeForce and later chips will be included, and so will all the Radeon and later parts. There are a few speculative parts in the charts, and figures for these can and likely will change before they are released - if they ever do manage to see the light of day.
As far as organization goes, code names and features will be listed first. Next, a look at the potential performance - and why it often isn't realized - will follow. There will also be some general micro processor information and die size estimates later on, which you can skip if such discussions do not hold your interest. Unfortunately, estimates are the best we can do in some areas, as getting details from any of the major graphics card companies is like pulling teeth from a crocodile. With that said, on to the charts.
ATI Chipsets
Below you can see our breakdown of the GPU guide for ATI video cards:
| ATI Craphics Chips Overview | ||||||||
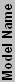 |
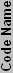 |
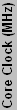 |
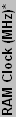 |
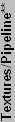 |
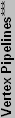 |
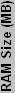 |
 |
|
| DirectX 9 with PS2.0b and VS2.0 Support | ||||||||
| X700 Pro | RV410 | 8 | 1 | 6 | 128/256 | 128 | ||
| X700 XT? | RV410 | 500 | 1000 | 8 | 1 | 6 | 128/256 | 128 |
| X800 SE? | R420 | 425 | 800 | 8 | 1 | 6 | 128/256 | 256 |
| X800 Pro | R420 | 475 | 900 | 12 | 1 | 6 | 256 | 256 |
| X800 GT? | R420 | 425 | 900 | 16 | 1 | 6 | 256 | 256 |
| X800 XT | R420 | 500 | 1000 | 16 | 1 | 6 | 256 | 256 |
| X800 XT? | R423 | 500 | 1000 | 16 | 1 | 6 | 256 | 256 |
| X800 XT PE | R420 | 520 | 1120 | 16 | 1 | 6 | 256 | 256 |
| X800 XT PE? | R423 | 520 | 1120 | 16 | 1 | 6 | 256 | 256 |
| DirectX 9 with PS2.0 and VS2.0 Support | ||||||||
| 9500 | R300 | 275 | 540 | 4 | 1 | 4 | 64/128 | 128 |
| 9500 Pro | R300 | 275 | 540 | 8 | 1 | 4 | 128 | 128 |
| 9550 | RV350 | 250 | 400 | 4 | 1 | 2 | 64/128/256 | 128 |
| 9550 SE | RV350 | 250 | 400 | 4 | 1 | 2 | 64/128/256 | 64 |
| 9600 | RV350 | 325 | 400 | 4 | 1 | 2 | 128/256 | 128 |
| 9600 Pro | RV350 | 400 | 600 | 4 | 1 | 2 | 128/256 | 128 |
| 9600 SE | RV350 | 325 | 400 | 4 | 1 | 2 | 64/128/256 | 64 |
| 9600 XT | RV360 | 500 | 600 | 4 | 1 | 2 | 128/256 | 128 |
| X300 | RV370 | 325 | 400 | 4 | 1 | 2 | 64/128/256 | 128 |
| X300 SE | RV370 | 325 | 400 | 4 | 1 | 2 | 64/128 | 64 |
| X600 Pro | RV380 | 400 | 600 | 4 | 1 | 2 | 128/256 | 128 |
| X600 XT | RV380 | 500 | 740 | 4 | 1 | 2 | 128/256 | 128 |
| 9700 | R300 | 275 | 540 | 8 | 1 | 4 | 128 | 256 |
| 9700 Pro | R300 | 325 | 620 | 8 | 1 | 4 | 128 | 256 |
| 9800 | R350 | 325 | 600 | 8 | 1 | 4 | 128 | 256 |
| 9800 "Pro" | R350/360 | 380 | 680 | 8 | 1 | 4 | 128/256 | 128 |
| 9800 Pro 128 | R350/360 | 380 | 680 | 8 | 1 | 4 | 128 | 256 |
| 9800 Pro 256 | R350/360 | 380 | 700 | 8 | 1 | 4 | 256 | 256 |
| 9800 SE 128 | R350 | 325 | 580 | 8 | 1 | 4 | 128 | 128 |
| 9800 SE 256 | R350 | 380 | 680 | 4 | 1 | 4 | 128 | 256 |
| 9800 XT | R360 | 412 | 730 | 8 | 1 | 4 | 256 | 256 |
| DirectX 8.1 with PS1.4 and VS1.1 Support | ||||||||
| 8500 LE | R200 | 250 | 500 | 4 | 2 | 1 | 64/128 | 128 |
| 8500 | R200 | 275 | 550 | 4 | 2 | 1 | 64/128 | 128 |
| 9000 | RV250 | 250 | 400 | 4 | 1 | 1 | 64/128 | 128 |
| 9000 Pro | RV250 | 275 | 550 | 4 | 1 | 1 | 64/128 | 128 |
| 9100 | R200 | 250 | 500 | 4 | 2 | 1 | 64/128 | 128 |
| 9100 Pro | R200 | 275 | 550 | 4 | 2 | 1 | 64/128 | 128 |
| 9200 SE | RV280 | 200 | 333 | 4 | 1 | 1 | 64/128 | 64 |
| 9200 | RV280 | 250 | 400 | 4 | 1 | 1 | 64/128/256 | 128 |
| 9200 Pro | RV280 | 300 | 600 | 4 | 1 | 1 | 64/128 | 128 |
| 9250 | RV280 | 240 | 400 | 4 | 1 | 1 | 128/256 | 128 |
| DirectX 7 | ||||||||
| Radeon VE^ | RV100 | 183 | 183 | 1 | 3 | 0 | 32 | 64 |
| 7000 PCI^ | RV100 | 166 | 333 | 1 | 3 | 0 | 32? | 64 |
| 7000 AGP^ | RV100 | 183 | 366 | 1 | 3 | 0 | 32/64 | 64 |
| Radeon LE | R100 | 148 | 296 | 2 | 3 | 0.5 | 32 | 128 |
| Radeon SDR | R100 | 166 | 166 | 2 | 3 | 0.5 | 32/64 | 128 |
| Radeon DDR | R100 | 183 | 366 | 2 | 3 | 0.5 | 32/64 | 128 |
| 7200 | R100 | 183 | 183 | 2 | 3 | 0.5 | 32/64 | 64 |
| 7500 LE | RV200 | 250 | 360 | 2 | 3 | 0.5 | 32? | 128 |
| 7500 AIW | RV200 | 250 | 333 | 2 | 3 | 0.5 | 32? | 128 |
| 7500 | RV200 | 290 | 460 | 2 | 3 | 0.5 | 32/64 | 128 |
| * RAM clock is the effective clock speed, so 250 MHz DDR is listed as 500 MHz. | ||||||||
| ** Textures/Pipeline is the number of unique texture lookups. ATI has implementations that can lookup 3 textures, but two of the lookups must be from one texture. | ||||||||
| *** Vertex pipelines is estimated on certain architectures. NVIDIA says their GFFX cards have a "vertex array", but in practice it performs as shown. | ||||||||
| ^ Radeon 7000 and VE Series had their Transform and Lighting Engine removed, and hence cannot perform fixed function vertex processing. | ||||||||
As far as the various models are concerned, ATI has DX7, DX8.1, and DX9 parts, as well as an unofficial DX9 with SM2.0b support - unofficial due to the fact that Microsoft has not actually certified this "in between" version of DX9. ATI has features that are part of SM3.0, but they do not include the full SM3.0 feature set. When they enable their 2.0b features, they fail WHQL compliance. Since not having WHQL compliance creates concerns among users (the dreaded "This device driver is not certified for use by Microsoft" warning), ATI will turn them off by default, and many people will not know enough to reenable them. It may not seem like a big deal, but software companies are less likely to optimize for non-standard features - especially ones that are disabled by default - so SM3.0 is more likely to see support than SM2.0b.
Generalizing somewhat, we can say that each family of ATI cards outperforms the older generation cards. There are, of course, exceptions, such as the 9550/9600 SE cards which are outclassed by the older 8500/9100 models, and the performance of the 9200SE is rather anemic in comparison to the 7500 in the majority of games. However, the added features and performance tweaks usually make up for the difference in raw numbers, and so comparing performance between the various generations of hardware does not always work.
Older ATI cards lacked support for multi-sample antialiasing, resorting to super-sampling as an alternative. Super-sampling, if you don't know, simply renders the screen at a higher resolution and then filters it down to a lower resolution, and in most cases it is limited to a maximum of 1600x1200. The quality is actually quite good with super-sampling, but the performance hit is enormous. Only with the R3xx cores did ATI begin to support multi-sampling, which helps to these cards to beat the previous generation when AA is enabled. Of course, once ATI did begin supporting multi-sampling, they did it very well, and the quality of their rotated grid sampling was regarded as being superior to the NVIDIA FX line.
ATI has also done anisotropic filtering very well for quite some time, although many believe it is due to "cheats" or "unfair optimizations". The real difference between ATI's implementation of AF and NVIDIA's is that ATI used a faster distance calculation. "True" anisotropic filtering does not really exist as such, and in the end it really comes down to getting improved image quality without killing performance. Today, it is very difficult to distinguish between the optimized and unoptimized filtering methods that both companies employ, and ATI has said they will address any situations where their image quality suffers.
At present, it is worth mentioning that all of the 9800 series chips and X800 series chips use the same base core. ATI validates the chips and in cases where portions of the chips fail, they can deactivate some of the pipelines and still sell the chip as a "light" version. With the 9800 SE cards, some people were able to "soft mod" their chips into full 9800 Pro cards, but success was not guaranteed. There are rumors that the same can be done with the X800 Pro cards, although success seems to be relatively rare right now, likely due to the large size of the chips. As the manufacturing process improves, success rates should also improve, but it's still a gamble. 9500/Pro cards were also based off the more complex 9700/Pro chip, and quite a few people were able to mod these cards into faster versions, but the introduction of the 9600 series put an end to that. We do not recommend purchasing the lower end cards with the intent to soft mod unless you are willing to live with the consequences, namely that success is by no means guaranteed and it will void the warranty. In our opinion, the relatively small price difference just isn't enough to warrant the risk.
NVIDIA Chipsets
Below you can see our breakdown of the GPU guide for NVIDA video cards:
| NVIDIA Craphics Chips Overview | ||||||||
|
|
|
|
|
|
|
|
|
| DirectX 9.0C with PS3.0 and VS3.0 Support | ||||||||
| GF 6600 | NV43 | 300 | 550 | 8 | 1 | 3 | 128/256 | 128 |
| GF 6600GT | NV43 | 500 | 1000 | 8 | 1 | 3 | 128/256 | 128 |
| GF 6800LE | NV40 | 320 | 700 | 8 | 1 | 5 | 128 | 256 |
| GF 6800LE | NV41 | 320 | 700 | 8 | 1 | 5 | 128 | 256 |
| GF 6800 | NV40 | 325 | 700 | 12 | 1 | 5 | 128 | 256 |
| GF 6800 | NV41 | 325 | 700 | 12 | 1 | 5 | 128 | 256 |
| GF 6800GT | NV40 | 350 | 1000 | 16 | 1 | 6 | 256 | 256 |
| GF 6800U | NV40 | 400 | 1100 | 16 | 1 | 6 | 256 | 256 |
| GF 6800UE | NV40 | 450 | 1200 | 16 | 1 | 6 | 256 | 256 |
| DirectX 9 with PS2.0+ and VS2.0+ Support | ||||||||
| GFFX 5200LE | NV34 | 250 | 400 | 4 | 1 | 1 | 64/128 | 64 |
| GFFX 5200 | NV34 | 250 | 400 | 4 | 1 | 1 | 64/128/256 | 128 |
| GFFX 5200U | NV34 | 325 | 650 | 4 | 1 | 1 | 128 | 128 |
| GFFX 5500 | NV34 | 270 | 400 | 4 | 1 | 1 | 128/256 | 128 |
| GFFX 5600XT | NV31 | 235 | 400 | 4 | 1 | 1 | 128/256 | 128 |
| GFFX 5600 | NV31 | 325 | 500 | 4 | 1 | 1 | 128/256 | 128 |
| GFFX 5600U | NV31 | 350 | 700 | 4 | 1 | 1 | 128/256 | 128 |
| GFFX 5600U FC | NV31 | 400 | 800 | 4 | 1 | 1 | 128 | 128 |
| GFFX 5700LE | NV36 | 250 | 400 | 4 | 1 | 3 | 128/256 | 128 |
| GFFX 5700 | NV36 | 425 | 500 | 4 | 1 | 3 | 128/256 | 128 |
| GFFX 5700U | NV36 | 475 | 900 | 4 | 1 | 3 | 128/256 | 128 |
| GFFX 5700U GDDR3 | NV36 | 475 | 950 | 4 | 1 | 3 | 128 | 128 |
| GFFX 5800 | NV30 | 400 | 800 | 4 | 2 | 2 | 128 | 128 |
| GFFX 5800U | NV30 | 500 | 1000 | 4 | 2 | 2 | 128 | 128 |
| GFFX 5900XT/SE | NV35 | 400 | 700 | 4 | 2 | 3 | 128 | 256 |
| GFFX 5900 | NV35 | 400 | 850 | 4 | 2 | 3 | 128/256 | 256 |
| GFFX 5900U | NV35 | 450 | 850 | 4 | 2 | 3 | 256 | 256 |
| GFFX 5950U | NV38 | 475 | 950 | 4 | 2 | 3 | 256 | 256 |
| DirectX 8 with PS1.3 and VS1.1 Support | ||||||||
| GF3 Ti200 | NV20 | 175 | 400 | 4 | 2 | 1 | 64/128 | 128 |
| GeForce 3 | NV20 | 200 | 460 | 4 | 2 | 1 | 64 | 128 |
| GF3 Ti500 | NV20 | 240 | 500 | 4 | 2 | 1 | 64 | 128 |
| GF4 Ti4200 128 | NV25 | 250 | 444 | 4 | 2 | 2 | 128 | 128 |
| GF4 Ti4200 64 | NV25 | 250 | 500 | 4 | 2 | 2 | 64 | 128 |
| GF4 Ti4200 8X | NV28 | 250 | 514 | 4 | 2 | 2 | 128 | 128 |
| GF4 Ti4400 | NV25 | 275 | 550 | 4 | 2 | 2 | 128 | 128 |
| GF4 Ti4600 | NV25 | 300 | 600 | 4 | 2 | 2 | 128 | 128 |
| GF4 Ti4800 SE | NV28 | 275 | 550 | 4 | 2 | 2 | 128 | 128 |
| GF4 Ti4800 | NV28 | 300 | 650 | 4 | 2 | 2 | 128 | 128 |
| DirectX 7 | ||||||||
| GeForce 256 DDR | NV10 | 120 | 300 | 4 | 1 | 0.5 | 32/64 | 128 |
| GeForce 256 SDR | NV10 | 120 | 166 | 4 | 1 | 0.5 | 32/64 | 128 |
| GF2 MX200 | NV11 | 175 | 166 | 2 | 2 | 0.5 | 32/64 | 64 |
| GF2 MX | NV11 | 175 | 333 | 2 | 2 | 0.5 | 32/64 | 64/128 |
| GF2 MX400 | NV11 | 200 | 333 | 2 | 2 | 0.5 | 32/64 | 128 |
| GF2 GTS | NV15 | 200 | 333 | 4 | 2 | 0.5 | 32/64 | 128 |
| GF2 Pro | NV15 | 200 | 400 | 4 | 2 | 0.5 | 32/64 | 128 |
| GF2 Ti | NV15 | 250 | 400 | 4 | 2 | 0.5 | 32/64 | 128 |
| GF2 Ultra | NV15 | 250 | 460 | 4 | 2 | 0.5 | 64 | 128 |
| GF4 MX4000 | NV19 | 275 | 400 | 2 | 2 | 0.5 | 64/128 | 64 |
| GF4 MX420 | NV17 | 250 | 333 | 2 | 2 | 0.5 | 64 | 64 |
| GF4 MX440 SE | NV17 | 250 | 333 | 2 | 2 | 0.5 | 64/128 | 128 |
| GF4 MX440 | NV17 | 275 | 400 | 2 | 2 | 0.5 | 32/64 | 128 |
| GF4 MX440 8X | NV18 | 275 | 500 | 2 | 2 | 0.5 | 64/128 | 128 |
| GF4 MX460 | NV17 | 300 | 550 | 2 | 2 | 0.5 | 64 | 128 |
| * RAM clock is the effective clock speed, so 250 MHz DDR is listed as 500 MHz. | ||||||||
| ** Textures/Pipeline is the number of unique texture lookups. ATI has implementations that can lookup 3 textures, but two of the lookups must be from one texture. | ||||||||
| *** Vertex pipelines is estimated on certain architectures. NVIDIA says their GFFX cards have a "vertex array", but in practice it performs as shown. | ||||||||
The caveats are very similar on the NVIDIA side of things. In terms of DirectX support, NVIDIA has DX7, DX8.0, DX9, and DX9.0c support. Unlike the X800 cards which support an unofficial DX spec, DX9.0c is a Microsoft standard. On the flip side, the SM2.0a features of the FX line went almost entirely unused, and the 32-bit floating point (as opposed to the 24-bit values ATI uses) appears to be part of the problem with the inferior DX9 performance of the FX series. The benefit of DX8.1 over DX8.0 was that a few more operations were added to the hardware, so tasks that would have required two passes on DX8.0 can be done in one pass on DX8.1.
When DX8 cards were all the rage, DX8.1 support was something of a non-issue, as DX8 games were hard to come by, and most opted for the more widespread 8.0 spec. Now, however, games like Far Cry and the upcoming Half-Life 2 have made DX8.1 support a little more useful. The reason for this is that every subsequent version of DirectX is a superset of the older versions, so every DX9 card must include both DX8 and DX8.1 functionality. GeForce FX cards in the beta of Counter Strike: Source default to DX8.1 rendering paths in order to get the best compromise between quality and speed, while GeForce 3 and 4 Ti cards use the DX8.0 rendering path.
Going back to ATI for a minute, it becomes a little clearer why ATI's SM2.0b isn't an official Microsoft standard. SM3.0 already supersedes it as a standard, and yet certain features of SM2.0b as ATI defines it are not present in SM3.0, for example the new 3Dc normal map compression. Only time will tell if this feature gets used with current hardware, but it will likely be included in a future version of DirectX, so it could come in useful.
In contrast to ATI, where the card generations are pretty distinct entities, the NVIDIA cards show a lot more overlap. The GF3 cards only show a slight performance increase over the GF2 Ultra, and that is only in more recent games. Back in the day, there really wasn't much incentive to leave the GF2 Ultra and "upgrade" to the GF3, especially considering the cost, and many people simply skipped the GF3 generation. Similarly, those that purchased the GF4 Ti line were left with little reason to upgrade to the FX line, as the Ti4200 remains competitive in most games all the way up to the FX5600. The FX line is only really able to keep up with - and sometimes beat - the GF4Ti cards when DX8.1 or DX9 features are used, or when enabling antialiasing and/or anisotropic filtering.
Speaking of antialiasing.... The GF2 line lacked support for multi-sample antialiasing and relied on the more simplistic super-sampling method. We say "simplistic" meaning that it was easier to implement - it is actually much more demanding on memory bandwidth, so it was less useful. The GF3 line brought the first consumer cards with multi-sample antialiasing, and NVIDIA went one step further by creating a sort of rotated-grid method called Quincunx, which offered superior quality to 2xAA while incurring less of a performance hit than 4xAA. However, as the geometrical complexity of games increased - something DX7 promised and yet failed to deliver for several years - none of these cards were able to perform well with antialiasing enabled. The GF4 line refined the antialiasing support slightly - even the GF4MX line got hardware antialiasing support, although here it was more of a checklist feature than something most people would actually enable - but for the most part it remained the same as in the GF3. The GFFX line continued with the same basic antialiasing support, and it was only with the GeForce 6 series that NVIDIA finally improved the quality of their antialiasing by switching to a rotated grid. At present, the differences in implementation and quality of antialiasing on ATI and NVIDIA hardware are almost impossible to spot in practical use. ATI does support 6X multi-sample anti-aliasing, of course, but that generally brings too much of a performance hit to use except on older games.
Anisotropic filtering for NVIDIA was a different story. First introduced with the GF2 line, it was extremely limited and rather slow - the GF2 could only provide 2xAF, called 8-tap filtering by NVIDIA because it uses 8 samples. GeForce3 added support for up to 8xAF (32-tap), along with performance improvements compared to the GF2 when anisotropic filtering was enabled. Also, the GF2 line was really better optimized for 16-bit color performance, while the GF3 and later all manage 32-bit color with a much less noticeable performance hit. This is likely related to the same enhancements that allow for better anisotropic filtering.
As games became more complex, the cost of doing "real" anisotropic filtering became too great, and so there were optimizations and accusations of cheating by many parties. The reality is that NVIDIA used a more correct distance calculation than ATI: d = x^2 + y^2 + z^2, compared to d = ax+by+cz. The latter equation is substantially faster, but the results are less correct. It ends up giving correct results only at certain angles, while other angles use a lower level of AF. Unfortunately for those who desire maximum image quality, NVIDIA solved the discrepancy in AF performance by switching to ATI's distance calculation on the GeForce 6 line. The GeForce 6 line also marks the introductions of 16xAF (64-tap) by NVIDIA, although it is nearly impossible to spot the difference in quality between 8xAF and 16xAF without some form of image manipulation. So, things have now been sorted out as far as "cheating" accusations go. It is probably safe to say that in modern games, the GF4 and earlier chips are not able to handle anisotropic filtering well enough to warrant enabling it.
NVIDIA is also using various versions of the same chip in their high end parts. The 6800 cards at present all use the same NV40 chip. Certain chips have some of the pipelines deactivated and they are then sold in lower end cards. Rumors about the ability to "mod" 6800 vanilla chips into 16 pipeline versions exist, but success rates are not yet known and are likely low, due again to the size of the chips. NVIDIA has plans to release a modified chip, a.k.a. NV41, which will only have 12 pixel pipelines and 5 vertex pipelines, in order to reduce manufacturing costs and improve yields.
Let's Talk Performance
This section is likely to generate a lot of flames if left unchecked. First, though, we want to make it abundantly clear that raw, theoretical performance numbers (which is what is listed here) rarely manage to match real world performance figures. There are numerous reasons for this discrepancy, for example the game or application in use may stress different parts of the architecture. A game that pushes a lot of polygons with low resolution textures is going to stress the geometry engine, while a game that uses high resolution textures with lower polygon counts is more likely to stress the memory bandwidth. Pixel and Vertex Shaders are even more difficult to judge, as both ATI and NVIDIA are relatively tight-lipped about the internal layout of their pipelines. These functions are the most like an actual CPU, but they're also highly proprietary and the companies feel a need to protect their technology (probably with good cause). So while we know that AMD Athlon 64 chips have a 12 stage Integer/ALU pipeline and 17 stage FPU/SSE pipeline, we really have no idea how many stages are in the pixel and vertex pipelines of ATI and NVIDIA cards. In fact, we really don't have much more than a simplistic functional overview.
So why even bother talking about performance without benchmarks? In part, by looking at the theoretical performance and comparing it to the real world performance (you'll have to find such real world figures in another article), we can get a better idea of what went wrong and what worked well. More importantly, though, most people referring to a GPU Guide are going to expect some sort of comparison and ranking of the parts. It is by no means definitive, and for some people choosing a graphics card is akin to joining a religion. So, take these numbers with a grain of salt and know that they are not intentionally meant to make one card look better than another. Where performance seriously fails to match expectations, it will be noted.
There are numerous factors that can affect performance, other than the application itself. Drivers are a major one, and it is not unheard of for the performance of a particular card to increase by as much as 50% over its lifetime due to driver enhancements. In light of such examples (i.e. both Radeon and GeForce cards in Quake 3 performance increased dramatically over time), it is somewhat difficult to say that theoretical performance numbers are really that much worse than changing real world numbers. With proper optimization, real world numbers can usually approach theoretical numbers, but this really only occurs for the most popular applications. Features also play a part, all other things being equal, so if two cards have the same theoretical performance but one card is DX9 based and the other is DX8 based, the DX9 card is should be faster.
Speaking of drivers, we would be remiss if we didn't at least mention OpenGL support. Brought into the consumer segment with GLQuake back in 1997, OpenGL is a different platform and requires different drivers. NVIDIA and ATI both have full OpenGL drivers, but all evidence indicates that NVIDIA's drivers are simply better at this point in time. Doom 3 is the latest example of this. However, OpenGL is also used in the professional world, and again NVIDIA tends to lead in performance, even with inferior hardware. Part of the problem is that very few games other than id Software titles and their licensees use OpenGL, so it often takes a back seat to DirectX. However, ATI has vowed to improve their OpenGL performance since the release of Doom 3, and hopefully they can close the gap between their DirectX and OpenGL drivers.
So, how is overall performance determined - in other words, how will the tables be sorted? The three main factors are fill rate, memory bandwidth, and processing power. Fill rate and bandwidth have been used for a long time, and they are well understood. Processing power, on the other hand, is somewhat more difficult to determine, especially with DX8 and later Pixel and Vertex Shaders. We will use the vertices/second rating as am estimate of processing power. For the charts, each section will be normalized relative to the theoretically fastest member of the group, and equal weight will be given to the fill rate, bandwidth, and vertex rate. That's not the best way of measuring performance, of course, but it's a start, and everything is theoretical at this point anyway. If you really want a suggestion on a specific card, the forums and past articles are a better place to search. Another option is to decide which games (or applications) you are most concerned about, and then go find an article that has benchmarks with that particular title.
To reiterate, this is more of a historical perspective on graphics chips and not a comparison of real world performance. And with that disclaimer, let's get on to the performance charts.
DirectX 9 Performance
Below you can see our plot of the DirectX9 components.
|
|
|
|
|
|
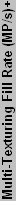 |
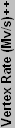 |
 |
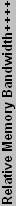 |
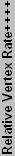 |
 |
||
| 9600 Pro | 400 | 600 | 4 | 1 | 2 | 128 | 1600 | 200 | 9155 | 100.0% | 100.0% | 100.0% | 100.0% |
| DirectX 9 | |||||||||||||
| GF 6800UE | 450 | 1200 | 16 | 1 | 6 | 256 | 7200 | 675 | 36621 | 450.0% | 400.0% | 337.5% | 475.0% |
| X800 XT PE | 520 | 1120 | 16 | 1 | 6 | 256 | 8320 | 780 | 34180 | 520.0% | 373.3% | 390.0% | 470.6% |
| X800 XT PE | 520 | 1120 | 16 | 1 | 6 | 256 | 8320 | 780 | 34180 | 520.0% | 373.3% | 390.0% | 470.6% |
| X800 XT | 500 | 1000 | 16 | 1 | 6 | 256 | 8000 | 750 | 30518 | 500.0% | 333.3% | 375.0% | 443.1% |
| GF 6800U | 400 | 1100 | 16 | 1 | 6 | 256 | 6400 | 600 | 33569 | 400.0% | 366.7% | 300.0% | 426.7% |
| X800 GT? | 425 | 900 | 16 | 1 | 6 | 256 | 6800 | 638 | 27466 | 425.0% | 300.0% | 318.8% | 382.7% |
| GF 6800GT | 350 | 1000 | 16 | 1 | 6 | 256 | 5600 | 525 | 30518 | 350.0% | 333.3% | 262.5% | 378.3% |
| X800 Pro | 475 | 900 | 12 | 1 | 6 | 256 | 5700 | 713 | 27466 | 356.3% | 300.0% | 356.3% | 371.3% |
| X800 Pro | 475 | 900 | 12 | 1 | 6 | 256 | 5700 | 713 | 27466 | 356.3% | 300.0% | 356.3% | 371.3% |
| X800 SE? | 425 | 800 | 8 | 1 | 6 | 256 | 3400 | 638 | 24414 | 212.5% | 266.7% | 318.8% | 292.6% |
| X700 XT? | 500 | 1000 | 8 | 1 | 6 | 128 | 4000 | 750 | 15259 | 250.0% | 166.7% | 375.0% | 290.3% |
| GF 6800 | 325 | 700 | 12 | 1 | 5 | 256 | 3900 | 406 | 21362 | 243.8% | 233.3% | 203.1% | 272.1% |
| GF 6800 | 325 | 700 | 12 | 1 | 5 | 256 | 3900 | 406 | 21362 | 243.8% | 233.3% | 203.1% | 272.1% |
| GF 6600GT | 500 | 1000 | 8 | 1 | 3 | 128 | 4000 | 375 | 15259 | 250.0% | 166.7% | 187.5% | 241.7% |
| GF 6800LE | 320 | 700 | 8 | 1 | 5 | 256 | 2560 | 400 | 21362 | 160.0% | 233.3% | 200.0% | 237.3% |
| GF 6800LE | 320 | 700 | 8 | 1 | 5 | 256 | 2560 | 400 | 21362 | 160.0% | 233.3% | 200.0% | 237.3% |
| 9800 XT | 412 | 730 | 8 | 1 | 4 | 256 | 3296 | 412 | 22278 | 206.0% | 243.3% | 206.0% | 218.4% |
| GFFX 5950U | 475 | 950 | 4 | 2 | 3 | 256 | 3800 | 356 | 28992 | 237.5% | 316.7% | 178.1% | 207.5% |
| 9800 Pro 256 | 380 | 700 | 8 | 1 | 4 | 256 | 3040 | 380 | 21362 | 190.0% | 233.3% | 190.0% | 204.4% |
| 9800 Pro 128 | 380 | 680 | 8 | 1 | 4 | 256 | 3040 | 380 | 20752 | 190.0% | 226.7% | 190.0% | 202.2% |
| GFFX 5900U | 450 | 850 | 4 | 2 | 3 | 256 | 3600 | 338 | 25940 | 225.0% | 283.3% | 168.8% | 191.8% |
| GFFX 5900 | 400 | 850 | 4 | 2 | 3 | 256 | 3200 | 300 | 25940 | 200.0% | 283.3% | 150.0% | 179.4% |
| 9700 Pro | 325 | 620 | 8 | 1 | 4 | 256 | 2600 | 325 | 18921 | 162.5% | 206.7% | 162.5% | 177.2% |
| 9800 | 325 | 600 | 8 | 1 | 4 | 256 | 2600 | 325 | 18311 | 162.5% | 200.0% | 162.5% | 175.0% |
| 9800 SE 256 | 380 | 680 | 4 | 1 | 4 | 256 | 1520 | 380 | 20752 | 95.0% | 226.7% | 190.0% | 170.6% |
| GFFX 5900XT/SE | 400 | 700 | 4 | 2 | 3 | 256 | 3200 | 300 | 21362 | 200.0% | 233.3% | 150.0% | 165.3% |
| 9800 "Pro" | 380 | 680 | 8 | 1 | 4 | 128 | 3040 | 380 | 10376 | 190.0% | 113.3% | 190.0% | 164.4% |
| GFFX 5800U | 500 | 1000 | 4 | 2 | 2 | 128 | 4000 | 250 | 15259 | 250.0% | 166.7% | 125.0% | 153.5% |
| 9700 | 275 | 540 | 8 | 1 | 4 | 256 | 2200 | 275 | 16479 | 137.5% | 180.0% | 137.5% | 151.7% |
| GF 6600 | 300 | 550 | 8 | 1 | 3 | 128 | 2400 | 225 | 8392 | 150.0% | 91.7% | 112.5% | 141.7% |
| 9800 SE 128 | 325 | 580 | 8 | 1 | 4 | 128 | 2600 | 325 | 8850 | 162.5% | 96.7% | 162.5% | 140.6% |
| GFFX 5700U GDDR3 | 475 | 950 | 4 | 1 | 3 | 128 | 1900 | 356 | 14496 | 118.8% | 158.3% | 178.1% | 129.0% |
| GFFX 5700U | 475 | 900 | 4 | 1 | 3 | 128 | 1900 | 356 | 13733 | 118.8% | 150.0% | 178.1% | 126.6% |
| X600 XT | 500 | 740 | 4 | 1 | 2 | 128 | 2000 | 250 | 11292 | 125.0% | 123.3% | 125.0% | 124.4% |
| GFFX 5800 | 400 | 800 | 4 | 2 | 2 | 128 | 3200 | 200 | 12207 | 200.0% | 133.3% | 100.0% | 122.8% |
| 9500 Pro | 275 | 540 | 8 | 1 | 4 | 128 | 2200 | 275 | 8240 | 137.5% | 90.0% | 137.5% | 121.7% |
| 9600 XT | 500 | 600 | 4 | 1 | 2 | 128 | 2000 | 250 | 9155 | 125.0% | 100.0% | 125.0% | 116.7% |
| 9600 Pro | 400 | 600 | 4 | 1 | 2 | 128 | 1600 | 200 | 9155 | 100.0% | 100.0% | 100.0% | 100.0% |
| X600 Pro | 400 | 600 | 4 | 1 | 2 | 128 | 1600 | 200 | 9155 | 100.0% | 100.0% | 100.0% | 100.0% |
| GFFX 5700 | 425 | 500 | 4 | 1 | 3 | 128 | 1700 | 319 | 7629 | 106.3% | 83.3% | 159.4% | 98.9% |
| 9500 | 275 | 540 | 4 | 1 | 4 | 128 | 1100 | 275 | 8240 | 68.8% | 90.0% | 137.5% | 98.8% |
| GFFX 5600U FC | 400 | 800 | 4 | 1 | 1 | 128 | 1600 | 100 | 12207 | 100.0% | 133.3% | 50.0% | 80.3% |
| 9600 | 325 | 400 | 4 | 1 | 2 | 128 | 1300 | 163 | 6104 | 81.3% | 66.7% | 81.3% | 76.4% |
| X300 | 325 | 400 | 4 | 1 | 2 | 128 | 1300 | 163 | 6104 | 81.3% | 66.7% | 81.3% | 76.4% |
| GFFX 5600U | 350 | 700 | 4 | 1 | 1 | 128 | 1400 | 88 | 10681 | 87.5% | 116.7% | 43.8% | 70.2% |
| 9600 SE | 325 | 400 | 4 | 1 | 2 | 64 | 1300 | 163 | 3052 | 81.3% | 33.3% | 81.3% | 65.3% |
| X300 SE | 325 | 400 | 4 | 1 | 2 | 64 | 1300 | 163 | 3052 | 81.3% | 33.3% | 81.3% | 65.3% |
| GFFX 5200U | 325 | 650 | 4 | 1 | 1 | 128 | 1300 | 81 | 9918 | 81.3% | 108.3% | 40.6% | 65.2% |
| 9550 | 250 | 400 | 4 | 1 | 2 | 128 | 1000 | 125 | 6104 | 62.5% | 66.7% | 62.5% | 63.9% |
| GFFX 5700LE | 250 | 400 | 4 | 1 | 3 | 128 | 1000 | 188 | 6104 | 62.5% | 66.7% | 93.8% | 63.2% |
| GFFX 5600 | 325 | 500 | 4 | 1 | 1 | 128 | 1300 | 81 | 7629 | 81.3% | 83.3% | 40.6% | 58.1% |
| 9550 SE | 250 | 400 | 4 | 1 | 2 | 64 | 1000 | 125 | 3052 | 62.5% | 33.3% | 62.5% | 52.8% |
| GFFX 5500 | 270 | 400 | 4 | 1 | 1 | 128 | 1080 | 68 | 6104 | 67.5% | 66.7% | 33.8% | 47.6% |
| GFFX 5200 | 250 | 400 | 4 | 1 | 1 | 128 | 1000 | 63 | 6104 | 62.5% | 66.7% | 31.3% | 45.5% |
| GFFX 5600XT | 235 | 400 | 4 | 1 | 1 | 128 | 940 | 59 | 6104 | 58.8% | 66.7% | 29.4% | 43.9% |
| GFFX 5200LE | 250 | 400 | 4 | 1 | 1 | 64 | 1000 | 63 | 3052 | 62.5% | 33.3% | 31.3% | 36.0% |
| * RAM clock is the effective clock speed, so 250 MHz DDR is listed as 500 MHz. | |||||||||||||
| ** Textures/Pipeline is the maximum number of texture lookups per pipeline. | |||||||||||||
| *** NVIDIA says their GFFX cards have a "vertex array", but in practice it generally functions as indicated. | |||||||||||||
| **** Single-texturing fill rate = core speed * pixel pipelines | |||||||||||||
| + Multi-texturing fill rate = core speed * maximum textures per pipe * pixel pipelines | |||||||||||||
| ++ Vertex rates can vary by implementation. The listed values reflect the manufacturers' advertised rates. | |||||||||||||
| +++ Bandwidth is expressed in actual MB/s, where 1 MB = 1024 KB = 1048576 Bytes. | |||||||||||||
| ++++ Relative performance is normalized to the Radeon 9600 pro, but these values are at best a rough estimate. | |||||||||||||
There are numerous footnotes that are worth pointing out, just in case some people missed them. For starters, the memory bandwidth is something that many people may not like. Normally, all companies list MB/s and GB/s calculating MB as one million bytes and GB as one billion bytes. That's incorrect, but since everyone does it, it begins to not matter. However, in this chart, real MB/s values are listed, so they will all be lower than what the graphics card makers advertise.
Fill rate can also be calculated in various ways, and for ATI's older Radeon cards (the DX7 models), they could apply three textures per pipeline per pass, or so they claimed. Two of the texture lookups, however, had to use the same texture, which made it a little less useful. Anyway, these are all purely theoretical numbers, and it is almost impossible to say how accurate they are in the real world without some specialized tools. To date, no one has created "real world" tools that measure these values, and they probably never will, so we are stuck with synthetic benchmarks at best. Basically, don't take the fill rate scores too seriously.
You can read the remaining footnotes above, and they should be self-explanatory. We just wanted to clarify those two points up front, and they apply to all of the performance charts. Now, on to the comments specifically related to DirectX 9.
The most important thing to point out first is that this chart has an additional weighting. This is due to the discrepancies in features and performance that exist among the various models of DirectX 9 hardware. The biggest concern is the theoretical performance of the GeForce FX cards. Most people should know this by now, but simply put the FX cards do not manage to live up to expectations at all when running DirectX 9 code. In DirectX 8.1 and earlier, the theoretical performance is a relatively accurate reflection of the real world, but overall the cards are far from perfect. We felt that the initial sorting was so unrealistic that a further weighting of the scores was in order, however you can view the unweighted chart if you wish. Newer features help improve performance at the same clock speed for cards as well, for example the optimizations to the memory controller in the GF6 line make the 6800 vanilla a faster card in almost all cases compared to the FX5950U and 9800 Pro cards. In fact, the GF6 cards are really only beaten by the X800 cards, and that's still not always the case.
The weighting used was relatively simple (and arbitrary). After averaging the fill rate, bandwidth and vertex rate scores, we multiply the result by a weighting factor.
NV3x Series: 0.85
R3xx Series: 1.00
R4xx Series: 1.10
NV4x Series: 1.20
This gives a rough approximation of how the features and architectural differences play out. Also note that certain chips lack some of the more specialized hardware optimizations, so while theoretical performance of the 5200U appears better than the 5600 and 5700LE, in most situations it ends up slower. Similarly, the X600 Pro and X300 chips should beat the 9600 Pro and 9600 chips in real performance, as the RV370 and RV380 probably contain a few optimizations and enhancements. They are also PCI Express parts, but that is not something to really worry about. PCI Express, at least for the time being, seems to be of little impact in actual performance - sometimes it's a little faster, sometimes it's a little slower. If you're looking at buying a PCIe based system for the other parts, that's fine, but we recommend that you don't waste your money on such an expensive system solely for PCIe - by the time PCIe really has a performance lead, today's systems will need upgrading anyway.
If you refer back to the earlier charts, you will notice that the X600 and X300 do not include any of the SM2.0b features. This is not a mistake - only the forthcoming X700 cards will bring the new features to ATI's mid-range cards. This is in contrast to the 6600 cards, which are functionally identical to the 6800 cards, only with fewer pipelines. The X700 is likely to have a performance advantage over the 6600 in many situations, as it will have a full six vertex pipelines compared to three vertex pipelines on the 6600. Should the 6800LE become widely available, however, it could end up the champion of the $200 and under segment, as the 256-bit memory bus may be more important than clock speeds. Having more than 25 GB/s of memory bandwidth does not always help performance without extremely fast graphics cores, but having less than 16 GB/s can slow things down. We'll find out how things play out in a few months.
DirectX 8 Performance
Below you can see our plot of the DirectX 8 components.
|
|
|
|
|
|
|
|
|
|
|
|
||
| GF4 Ti4200 64 | 250 | 500 | 4 | 2 | 2 | 128 | 2000 | 113 | 7629 | 100.0% | 100.0% | 100.0% | 100.0% |
| DirectX 8 and 8.1 | |||||||||||||
| GF4 Ti4800 | 300 | 650 | 4 | 2 | 2 | 128 | 2400 | 135 | 9918 | 120.0% | 130.0% | 120.0% | 123.3% |
| GF4 Ti4600 | 300 | 600 | 4 | 2 | 2 | 128 | 2400 | 135 | 9155 | 120.0% | 120.0% | 120.0% | 120.0% |
| GF4 Ti4400 | 275 | 550 | 4 | 2 | 2 | 128 | 2200 | 124 | 8392 | 110.0% | 110.0% | 110.0% | 110.0% |
| GF4 Ti4800 SE | 275 | 550 | 4 | 2 | 2 | 128 | 2200 | 124 | 8392 | 110.0% | 110.0% | 110.0% | 110.0% |
| GF4 Ti4200 8X | 250 | 514 | 4 | 2 | 2 | 128 | 2000 | 113 | 7843 | 100.0% | 102.8% | 100.0% | 100.9% |
| GF4 Ti4200 64 | 250 | 500 | 4 | 2 | 2 | 128 | 2000 | 113 | 7629 | 100.0% | 100.0% | 100.0% | 100.0% |
| GF4 Ti4200 128 | 250 | 444 | 4 | 2 | 2 | 128 | 2000 | 113 | 6775 | 100.0% | 88.8% | 100.0% | 96.3% |
| 8500 | 275 | 550 | 4 | 2 | 1 | 128 | 2200 | 69 | 8392 | 110.0% | 110.0% | 61.1% | 93.7% |
| 9100 Pro | 275 | 550 | 4 | 2 | 1 | 128 | 2200 | 69 | 8392 | 110.0% | 110.0% | 61.1% | 93.7% |
| 9100 | 250 | 500 | 4 | 2 | 1 | 128 | 2000 | 63 | 7629 | 100.0% | 100.0% | 55.6% | 85.2% |
| 8500 LE | 250 | 500 | 4 | 2 | 1 | 128 | 2000 | 63 | 7629 | 100.0% | 100.0% | 55.6% | 85.2% |
| 9200 Pro | 300 | 600 | 4 | 1 | 1 | 128 | 1200 | 75 | 9155 | 60.0% | 120.0% | 66.7% | 82.2% |
| GF3 Ti500 | 240 | 500 | 4 | 2 | 1 | 128 | 1920 | 54 | 7629 | 96.0% | 100.0% | 48.0% | 81.3% |
| 9000 Pro | 275 | 550 | 4 | 1 | 1 | 128 | 1100 | 69 | 8392 | 55.0% | 110.0% | 61.1% | 75.4% |
| GeForce 3 | 200 | 460 | 4 | 2 | 1 | 128 | 1600 | 45 | 7019 | 80.0% | 92.0% | 40.0% | 70.7% |
| 9000 | 250 | 400 | 4 | 1 | 1 | 128 | 1000 | 63 | 6104 | 50.0% | 80.0% | 55.6% | 61.9% |
| 9200 | 250 | 400 | 4 | 1 | 1 | 128 | 1000 | 63 | 6104 | 50.0% | 80.0% | 55.6% | 61.9% |
| GF3 Ti200 | 175 | 400 | 4 | 2 | 1 | 128 | 1400 | 39 | 6104 | 70.0% | 80.0% | 35.0% | 61.7% |
| 9250 | 240 | 400 | 4 | 1 | 1 | 128 | 960 | 60 | 6104 | 48.0% | 80.0% | 53.3% | 60.4% |
| 9200 SE | 200 | 333 | 4 | 1 | 1 | 64 | 800 | 50 | 2541 | 40.0% | 33.3% | 44.4% | 39.2% |
| * RAM clock is the effective clock speed, so 250 MHz DDR is listed as 500 MHz. | |||||||||||||
| ** Textures/Pipeline is the maximum number of texture lookups per pipeline. | |||||||||||||
| *** NVIDIA says their GFFX cards have a "vertex array", but in practice it generally functions as indicated. | |||||||||||||
| **** Single-texturing fill rate = core speed * pixel pipelines | |||||||||||||
| + Multi-texturing fill rate = core speed * maximum textures per pipe * pixel pipelines | |||||||||||||
| ++ Vertex rates can vary by implementation. The listed values reflect the manufacturers' advertised rates. | |||||||||||||
| +++ Bandwidth is expressed in actual MB/s, where 1 MB = 1024 KB = 1048576 Bytes. | |||||||||||||
| ++++ Relative performance is normalized to the GF4 Ti4200 64, but these values are at best a rough estimate. | |||||||||||||
No weighting has been applied to the DirectX 8 charts, and performance in games generally falls in line with what is represented in the above chart. Back in the DirectX 8 era, NVIDIA really had a huge lead in performance over ATI. The Radeon 8500 was able to offer better performance than the GeForce 3, but that lasted all of two months before the launch of the GeForce 4 Ti line. Of course, many people today continue running GeForce4 Ti cards with few complaints about performance - only high quality rendering modes and DX9-only applications are really forcing people to upgrade. For casual gamers, finding a used GF4Ti card for $50 or less may be preferable to buying a low-end DX9 card. It really isn't until the FX5700 Ultra and FX5600 Ultra that the GF4Ti cards are outclassed, and those cards still cost well over $100 new.
ATI did have one advantage over NVIDIA in the DirectX 8 era, however. They worked with Microsoft to create an updated version of DirectX; version 8.1. This added support for some "advanced pixel shader" effects, which brought the Pixel Shader version up to 1.4. There wasn't anything that could be done in DX8.1 that couldn't be done with DX8.0, but several operations could be done in one pass instead of two passes. Support for DirectX 8 games was very late in coming, however, and support for ATI's extensions was, if possible, even more so. There are a few titles which now support the DX8.1 extensions, but even then the older DX8.1 ATI cards are generally incapable of running these games well.
It is worth noting that the vertex rates on the NVIDIA cards are calculated as 90% of the clock speed times the number of vertex pipelines, divided by four. Why is that important? It's not, really, but on the FX and GF6 series of cards, NVIDIA uses clock speed times vertex pipelines divided by four for the claimed vertex rate. It could be that architectural improvements made the vertex rate faster. Such detail was lacking on the ATI side of things, although 68 million vertices/second for the 8500 was claimed in a few places, which matches the calculation used on NVIDIA's DX9 cards. You don't have to look any further than such benchmarks as 3DMark01 to find that these theoretical maximum are never reached, of course - even with one light source and no textures, the high polygon count scene doesn't come near the claimed rate.
DirectX 7 Performance
Below you can see our DirectX 7 based video processor chart:
|
|
|
|
|
|
|
|
|
|
|
|
||
| GF2 GTS | 200 | 333 | 4 | 2 | 0.5 | 128 | 1600 | 25 | 5081 | 100.0% | 100.0% | 100.0% | 100.0% |
| DirectX 7 | |||||||||||||
| 7500 | 290 | 460 | 2 | 3 | 0.5 | 128 | 1740 | 36 | 7019 | 108.8% | 138.1% | 145.0% | 130.6% |
| GF4 MX460 | 300 | 550 | 2 | 2 | 0.5 | 128 | 1200 | 38 | 8392 | 75.0% | 165.2% | 150.0% | 130.1% |
| GF2 Ultra | 250 | 460 | 4 | 2 | 0.5 | 128 | 2000 | 31 | 7019 | 125.0% | 138.1% | 125.0% | 129.4% |
| GF2 Ti | 250 | 400 | 4 | 2 | 0.5 | 128 | 2000 | 31 | 6104 | 125.0% | 120.1% | 125.0% | 123.4% |
| GF4 MX440 8X | 275 | 500 | 2 | 2 | 0.5 | 128 | 1100 | 34 | 7629 | 68.8% | 150.2% | 137.5% | 118.8% |
| 7500 LE | 250 | 360 | 2 | 3 | 0.5 | 128 | 1500 | 31 | 5493 | 93.8% | 108.1% | 125.0% | 109.0% |
| GF4 MX440 | 275 | 400 | 2 | 2 | 0.5 | 128 | 1100 | 34 | 6104 | 68.8% | 120.1% | 137.5% | 108.8% |
| GF2 Pro | 200 | 400 | 4 | 2 | 0.5 | 128 | 1600 | 25 | 6104 | 100.0% | 120.1% | 100.0% | 106.7% |
| 7500 AIW | 250 | 333 | 2 | 3 | 0.5 | 128 | 1500 | 31 | 5081 | 93.8% | 100.0% | 125.0% | 106.3% |
| GF2 GTS | 200 | 333 | 4 | 2 | 0.5 | 128 | 1600 | 25 | 5081 | 100.0% | 100.0% | 100.0% | 100.0% |
| GF4 MX440 SE | 250 | 333 | 2 | 2 | 0.5 | 128 | 1000 | 31 | 5081 | 62.5% | 100.0% | 125.0% | 95.8% |
| Radeon DDR | 183 | 366 | 2 | 3 | 0.5 | 128 | 1098 | 23 | 5585 | 68.6% | 109.9% | 91.5% | 90.0% |
| GF4 MX4000 | 275 | 400 | 2 | 2 | 0.5 | 64 | 1100 | 34 | 3052 | 68.8% | 60.1% | 137.5% | 88.8% |
| GF4 MX420 | 250 | 333 | 2 | 2 | 0.5 | 64 | 1000 | 31 | 2541 | 62.5% | 50.0% | 125.0% | 79.2% |
| Radeon LE | 148 | 296 | 2 | 3 | 0.5 | 128 | 888 | 19 | 4517 | 55.5% | 88.9% | 74.0% | 72.8% |
| GF2 MX400 | 200 | 166 | 2 | 2 | 0.5 | 128 | 800 | 25 | 2541 | 50.0% | 49.8% | 100.0% | 66.6% |
| Radeon SDR | 166 | 166 | 2 | 3 | 0.5 | 128 | 996 | 21 | 2533 | 62.3% | 49.8% | 83.0% | 65.0% |
| 7200 | 183 | 183 | 2 | 3 | 0.5 | 64 | 1098 | 23 | 1396 | 68.6% | 27.5% | 91.5% | 62.5% |
| GF2 MX | 175 | 166 | 2 | 2 | 0.5 | 128 | 700 | 22 | 2541 | 43.8% | 49.8% | 87.5% | 60.4% |
| GeForce 256 DDR | 120 | 300 | 4 | 1 | 0.5 | 128 | 480 | 15 | 4578 | 30.0% | 90.1% | 60.0% | 60.0% |
| GF2 MX200 | 175 | 166 | 2 | 2 | 0.5 | 64 | 700 | 22 | 1266 | 43.8% | 24.9% | 87.5% | 52.1% |
| GeForce 256 SDR | 120 | 166 | 4 | 1 | 0.5 | 128 | 480 | 15 | 2533 | 30.0% | 49.8% | 60.0% | 46.6% |
| 7000 AGP^ | 183 | 366 | 1 | 3 | 0 | 64 | 549 | 0 | 2792 | 34.3% | 55.0% | 0.0% | 29.8% |
| 7000 PCI^ | 166 | 333 | 1 | 3 | 0 | 64 | 498 | 0 | 2541 | 31.1% | 50.0% | 0.0% | 27.0% |
| Radeon VE^ | 183 | 183 | 1 | 3 | 0 | 64 | 549 | 0 | 1396 | 34.3% | 27.5% | 0.0% | 20.6% |
| * RAM clock is the effective clock speed, so 250 MHz DDR is listed as 500 MHz. | |||||||||||||
| ** Textures/Pipeline is the maximum number of texture lookups per pipeline. | |||||||||||||
| *** Nvidia says their GFFX cards have a "vertex array", but in practice it generally functions as indicated. | |||||||||||||
| **** Single-texturing fill rate = core speed * pixel pipelines | |||||||||||||
| + Multi-texturing fill rate = core speed * maximum textures per pipe * pixel pipelines | |||||||||||||
| ++ Vertex rates can vary by implementation. The listed values reflect the manufacturers' advertised rates. | |||||||||||||
| +++ Bandwidth is expressed in actual MB/s, where 1 MB = 1024 KB = 1048576 Bytes. | |||||||||||||
| ++++ Relative performance is normalized to the GF2 GTS, but these values are at best a rough estimate. | |||||||||||||
| ^ Radeon 7000 and VE had their T&L Engine removed, and cannot perform fixed function vertex processing. | |||||||||||||
Now we're talkin' old school. There are those people in the world that simply can't stand the thought of having less than the latest and greatest hardware on the planet in their PC, and then there are people that have social lives. Okay, it's not that bad, but not everyone needs a super powerful graphics card. In fact, there are plenty of businesses running computers with integrated graphics that would be thoroughly outclassed be even the five year old GeForce 256. If you're only playing older 3D games or just want to get the cheapest non-integrated card you can find, DX7 cards fit the bill. A Home Theater PC that plays movies has no need for anything more, for instance. Or maybe you have a friend that's willing to just give you his old graphics card, and you want to know if it will be better than the piece of junk you already have? Whatever the case, here are the relative performance figures for the DX7 era cards.
No special weighting was used, although with this generation of hardware you might want to pay closer attention to memory bandwidth than the other areas. Fill rate is still important as well, but vertex fill rate is almost a non-issue. In fact, these cards don't even advertise vertex rates - they were measured in triangle rates. Since they had a fixed-function Transform and Lighting (T&L) pipeline, triangles/sec was the standard unit of measurement. The vertex pipelines are listed as "0.5" for the DX7 cards, emphasizing that they are not programmable geometry processors. As luck would have it, 0.5 times clock speed divided by 4 also matches the advertised triangle rates, at least on the NVIDIA cards. Vertex rates are anywhere from two to four times this value, depending on whether or not edges are shared, but again these rates are not achievable with any known benchmark. One item worth pointing out is that the Radeon 7000 and VE parts have had their vertex pipeline deactivated or removed, so they are not true DX7 parts, but they are included as they bear the Radeon name.
Early adopters of the DX7 cards were generally disappointed, as geometry levels in games tended to remain relatively low. First, there was a demo called "Dagoth Moor Zoological Gardens" created for the launch of the original GeForce 256. It was created by a company called "The Whole Experience" and used upwards of 100,000 polygons. Unfortunately, they never released any commercial games using the engine (at least, none that we're aware of). Later, a different company at the launch of the GeForce 2 created a demo that had millions of polygons to show off the "future of gaming" - that company would eventually release a game based off of their engine that you might have hear of, Far Cry. Actually, Crytek Studios demoed for both the original GeForce 2 launch and the GeForce 3 launch. They used the same engine and the demo name "X-isle" was the same as well, but the GF3 version added support for some pixel shader and vertex shader effects. Four years after demonstrating the future, it finally arrived! Really, though, it wasn't that bad. Many games are in development for several years now, so you can't blame them too much for delaying. Besides, launching a game that only runs with the newest hardware is tantamount to financial suicide.
As far as performance is concerned, the GeForce2 was the king of this class of hardware for a long time. After the GeForce 3, NVIDIA revisited DX7 cards with the GF4MX line, which added additional hardware support for antialiasing and hardware bump mapping. While it only had two pixel pipelines in comparison to the 4 of the GF2, the higher core and RAM speeds generally allowed the GF4MX cards to match the GF2 cards, and in certain cases they beat it. The Radeon 7500 was also a decent performer in this class, although it generally trailed the GF2 slightly due to the 2x3 pixel pipeline, which could really only perform three texture operations if two of them came from the same texture. Worthy of mention is the Nforce2 IGP chipset, which included the GF4MX 440 core in place of the normally anemic integrated graphics most motherboards offer. Performance was actually more like the GF4MX420, due to the sharing of memory bandwidth with the CPU and other devices, but it remains one of the fastest performing integrated solutions to this day. Many cards were also crippled by the use of SDR memory or 64-bit buses - we still see such things with modern cards as well, of course. Caveat emptor, as they say. If you have any interest in gaming, stay away from 64-bit buses, and these days even 128-bit buses are becoming insufficient.
Estimating Die Size
Disclaimer: Although we have close and ready contact with ATI and NVIDIA, the fact remains that some of the more technical issues concerning actual architecture and design are either closely guarded or extremely obscured to the public. Thus we attempt to estimate some die sizes and transistor counts based on information we already know - and some of these estimations are slightly incorrect.
One of the pieces of information a lot of people might like to know is the die size of the various graphics chips. Unfortunately, ATI and NVIDIA are pretty tight-lipped about such information. Sure, you could rip the heatsink off of your graphics card and get a relatively good estimate of the die size, but unless you've got some serious cash flow, this probably isn't the best idea. Of course, some people have done that for at least a few chips, which will be somewhat useful later. Without resorting to empirical methods of measuring, though, how do we estimate the size of a processor?
Before getting into the estimating portions, let's talk about how microprocessors are made, as it is rather important. When a chip is built up, it starts as a simple ingot of silicon cut into wafers on which silicon dioxide is grown. This silicon dioxide is cut away using photolithography in order to expose the silicon in certain parts. Next, polysilicon is laid down and etched, and the exposed silicon is doped (ionized). Finally, another mask is added with smaller connections to the doped areas and the polysilicon, resulting in a layer of transistors, with three contacts for each newly created transistor. After the transistors are built up, metal layers are added to connect them in the fashion required for the chip. These metal layers are not actually transistors but are connections between transistors that form the "logic" of the chip. They are a miniaturized version of the metal wires you can see in a motherboard.
Microprocessors will of course require multiple layers, but the transistors are on the one polysilicon layer. Modern chips typically have between 15 and 20 layers, although we really only talk about the metal layers. In between each set of metal layers is a layer of insulation, so we usually end up with 6 to 9 metal layers. On modern AMD processors, there are 8 metal layers and the polysilicon layer. On Intel processors, there are 6 to 8 metal layers plus the polysilicon layer, depending on the processor: i.e. 6 for Northwood, 7 on Prescott and 8 on most of their server/workstation chips like the Gallatin.
Having more layers isn't necessarily good or bad; it's simply a necessary element. More complex designs require more complex routing, and since two crossing wires cannot touch each, they need to run on separate layers. Potentially, having more metal layers can help to simplify the layout of the transistors and pack them closer together, but it also adds to the cost as there are now more steps in the production, and more layers results in more internal heat. There are trade offs that can be made in many areas of chip production. In AMD's case, where they only have 200 mm wafers compared to the 300 mm wafers that Intel currently uses, adding extra layers in order to shrink the die size and/or increase speeds would probably be a good idea.
Other factors also come into play, however. Certain structures can be packed more densely than others. For example, the standard SRAM cell used in caches consists of six transistors and is one of the smaller structures in use on processors. This means that adding a lot of cache to a chip won't increase the size as quickly as adding other types chip logic. The materials used in the various layers of a chip can also affect the speed at which the chip can run as well as the density of the transistors and routing in the other metal layers. Copper interconnects conduct electricity better than aluminum, for instance, and the Silicon On Insulator (SOI) technology pioneered by IBM can also have an impact on speed and chip size. Many companies are also using low-k dielectric materials, which can help gates to switch faster. All of these technologies add to the cost of the chip, however, so it is not necessarily true that a chip which uses, i.e. low-k dielectric, will be faster and cheaper to produce than a chip without it.
What all this means is that there is no specific way to arrive at an accurate estimate of die size without having in-depth knowledge of the manufacturing technologies, design goals, costs, etc. Such information is usually a closely guarded secret for obvious reasons. You don't want to let your competitors know about your plans and capabilities any sooner than necessary. Anyway, we now have enough background information to move on to estimating die sizes.
If we're talking about 130 nm process technology, how many transistors of that thickness would fit in 1 mm? Easy enough to figure out: 1 mm / .00013 mm = 7692 T/mm (note that .00013 mm = 130 nm). If we're working in two dimensions, we square that value: 59166864 T/mm2 ("transistors" is abbreviated to "T"). This is assuming square or circular transistors, which isn't necessarily the case, but it is close enough. So, does anyone actually think that they can pack transistors that tightly? No? Good, because right now that's a solid sheet of metal. If 59 million T/ mm2 is the maximum, what is a realistic value? To find that out, we need to look at some actual processors.
The current Northwood core has 55 million transistors and is 131 mm2. That equals 419847 T/mm2, assuming uniform distribution. That sounds reasonable, but how does it compare with the theoretical packing of transistors? It's off by a factor of 141! Again, assuming uniform distribution of materials, it means that 11.9 times (the square root of 141) as much empty space is present in each direction as the actual metal of the transistors. Basically, electromagnetic interference (EMI) and other factors force chip designers to keep transistors and traces a certain distance apart. In the case of the P4, that distance is roughly 11.9 times the process technology in both width and depth. (We ignore height, as the insulation layers are several times thicker than this). So, we'll call this value of 11.9 on the Northwood the "Insulation Factor" or "IF" of the design.
We now have a number we can use to derive die size, given transistor counts and process technology:
Die Size = Transistor Count / (1 / ((Process in mm) * IF)^2)
Again, notice that the process size is in millimeters, so that it matches with the standard unit of measurement for die size. Using the Northwood, we can check our results:
Die Size = 55000000 / (1 / ((0.00013) * 11.9)^2)Die Size = 131.6 mm2
So that works, but how do we know what the IF is on different processors? If it were a constant, things would be easy, but it's not. If we have a similar chip, though, the values will hopefully be pretty similar as well. Looking at the Barton core, it has 54.3 million transistors in 101 mm2. That gives it 537624 T/ mm2, which is obviously different than the Northwood, with the end IF being 10.5. Other 130 nm chips have different values as well. Part of the reason may be due to differences in counting the number of transistors. Transistor counts are really a guess, as not all of the transistors within the chip area are used. Materials used and other factors also come into play. To save time, here's a chart of IF values for various processors (based on their estimated transistor counts), with averages for the same process technology included.
| Calculated Process Insulation Values | ||||||||
|
 |
 |
 |
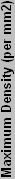 |
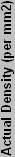 |
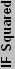 |
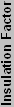 |
|
| AMD | ||||||||
| K6 | 8800000 | 250 | 68 | 5 | 16000000 | 129411.76 | 123.636 | 11.119 |
| K6-2 | 9300000 | 250 | 81 | 6 | 16000000 | 114814.81 | 139.355 | 11.805 |
| K6-3 | 21300000 | 250 | 135 | 7 | 16000000 | 157777.78 | 101.408 | 10.070 |
| Argon | 22000000 | 250 | 184 | 7 | 16000000 | 119565.22 | 133.818 | 11.568 |
| Average for 250 nm | 124.554 | 11.141 | ||||||
| Pluto/Orion | 22000000 | 180 | 102 | 7 | 30864198 | 215686.27 | 143.098 | 11.962 |
| Spitfire | 25000000 | 180 | 100 | 7 | 30864198 | 250000.00 | 123.457 | 11.111 |
| Morgan | 25200000 | 180 | 106 | 7 | 30864198 | 237735.85 | 129.826 | 11.394 |
| Thunderbird | 37000000 | 180 | 117 | 7 | 30864198 | 316239.32 | 97.598 | 9.879 |
| Palomino | 37500000 | 180 | 129 | 8 | 30864198 | 290697.67 | 106.173 | 10.304 |
| Average for 180 nm | 120.030 | 10.930 | ||||||
| Thoroughbred A | 37500000 | 130 | 80 | 8 | 59171598 | 468750.00 | 126.233 | 11.235 |
| Thoroughbred B | 37500000 | 130 | 84 | 9 | 59171598 | 446428.57 | 132.544 | 11.513 |
| Barton | 54300000 | 130 | 101 | 9 | 59171598 | 537623.76 | 110.061 | 10.491 |
| Sledgehammer SOI | 105900000 | 130 | 193 | 9 | 59171598 | 548704.66 | 107.839 | 10.385 |
| Average for 130 nm | 119.169 | 10.906 | ||||||
| San Diego SOI | 105900000 | 90 | 114 | 9 | 123456790 | 928947.37 | 132.900 | 11.528 |
| Intel | ||||||||
| Deschutes | 7500000 | 250 | 118 | 5 | 16000000 | 63559.32 | 251.733 | 15.866 |
| Katmai | 9500000 | 250 | 131 | 5 | 16000000 | 72519.08 | 220.632 | 14.854 |
| Mendocino | 19000000 | 250 | 154 | 6 | 16000000 | 123376.62 | 129.684 | 11.388 |
| Average for 250 nm | 200.683 | 14.036 | ||||||
| Coppermine First | 28100000 | 180 | 106 | 6 | 30864198 | 265094.34 | 116.427 | 10.790 |
| Coppermine Last | 28100000 | 180 | 90 | 6 | 30864198 | 312222.22 | 98.853 | 9.942 |
| Willamette | 42000000 | 180 | 217 | 6 | 30864198 | 193548.39 | 159.465 | 12.628 |
| Average for 180 nm | 124.915 | 11.120 | ||||||
| Tualatin | 28100000 | 130 | 80 | 6 | 59171598 | 351250.00 | 168.460 | 12.979 |
| Northwood First | 55000000 | 130 | 146 | 6 | 59171598 | 376712.33 | 157.074 | 12.533 |
| Northwood Last | 55000000 | 130 | 131 | 6 | 59171598 | 419847.33 | 140.936 | 11.872 |
| Average for 130 nm | 155.490 | 12.461 | ||||||
| Prescott | 125000000 | 90 | 112 | 7 | 123456790 | 1116071.43 | 110.617 | 10.517 |
| ATI | ||||||||
| RV350 | 75000000 | 130 | 91 | 8 | 59171598 | 824175.82 | 71.795 | 8.473 |
| Nvidia | ||||||||
| NV10 | 23000000 | 220 | 110 | 8 | 20661157 | 209090.91 | 98.814 | 9.941 |
| Average Insulation Factors | ||||||||
| 250 nm | 12.588 | |||||||
| 220 nm | 9.941 | |||||||
| 180 nm | 11.025 | |||||||
| 150 nm | 10.819 | |||||||
| 130 nm | 10.613 | |||||||
| 90 nm | 11.023 | |||||||
Lacking anything better than that, then, we will use the averages of the Intel and AMD values for the matching ATI and NVIDIA chips, with a little discretionary rounding to keep things simple. In cases where we have better estimates on die size, we will derive the IF and use those same IF values on the other chips from the same company. Looking at the numbers, the IF for AMD and Intel chips tends to range between 10 on a mature process up to 16 for initial chips on a new process. The two figures from GPUs are much lower than the typical CPU values, so we will assume GPUs tend to have more densely packed transistors (or else AMD and Intel are less aggressive in counting transistors).
These initial IF values could be off by as much as 20%, which means the end results could be off by as much as 44%. (How's that, you ask? 120% squared = 144%.) So, if this isn't abundantly clear yet, you should take these values with a HUGE dose of skepticism. If you have a better reference to an approximate die size (i.e. a web site with an images and/or die size measurements), please send an email or post a comment. Getting accurate figures would be really nice, but it is virtually impossible. Anyway, here are the IF values used in the estimates, with a brief explanation of why they were used.
| Chipset | IF | Notes |
| NV1x | 10.0 | Size is ~110 mm2 |
| NV2x | 10.00 | No real information and this seems a common value for GPUs of the era. |
| NV30, NV31 | 10.00 | Initial use of 130 nm was likely not optimal. |
| NV34 | 9.50 | Use of mature 150 nm process. |
| NV35, NV36, NV38 | 9.5 | Size is ~207 mm2 |
| NV40 | 8.75 | Size is ~288 mm2 |
| NV43 | 9.50 | Initial use of 110 nm process will not be as optimal as 130 nm. |
| R300, R350, R360 | 9.00 | Mature 150 nm process should be better than initial results. |
| RV350, RV360, RV380 | 8.50 | Size is ~91 mm2 |
| RV370 | 9.00 | No real information, but assuming the final chip will be smaller than RV360. Otherwise 110 nm is useless. |
| R420 | 9.75 | Size is ~260 mm2 |
| Other ATI Chips | 10.00 | Standard guess lacking any other information. |
Note also that there are reports that ATI is more conservative in transistor counts, so their 160 million could be equal to 180 or even 200 million of NVIDIA's transistors. Basically, transistor counts are estimates, and ATI is more conservative while NVIDIA likes to count everything they can. Neither is "right", but looking at die sizes, the 6800 is not much larger than the X800, despite a supposed 60 million transistor weight advantage. Either the IBM 130 nm fabs are not as advanced as the TSMC 130 nm fabs, or ATI's transistor counts are somewhat low, or NVIDIA's counts are somewhat high - most likely it's a combination of all these factors.
So, those are the values we'll use initially for our estimates. The most recent TSMC and IBM chips are using 8 metal layers, and since it does not really affect the estimates, we have put 8 metal layers on all of the GPUs. Again, if you have a source that gives an actual die size for any of the chips other than the few that we already have, please send them to us, and we can update the charts.
Graphics Chip Die Sizes
Finally, below you can see our rough estimations and calculations for some die sizes. Lines in bold indicate chips for which we have a relatively accurate die size, so they are not pure estimates.
| Nvidia Die Sizes | ||||||
|
|
|
|
|
 |
|
| DirectX 9.0C with PS3.0 and VS3.0 Support | ||||||
| GF 6600 | NV43 | 146 | 110 | 9.50 | 8 | 159 |
| GF 6600GT | NV43 | 146 | 110 | 9.50 | 8 | 159 |
| GF 6800LE | NV40 | 222 | 130 | 8.75 | 8 | 287 |
| GF 6800 | NV40 | 222 | 130 | 8.75 | 8 | 287 |
| GF 6800GT | NV40 | 222 | 130 | 8.75 | 8 | 287 |
| GF 6800U | NV40 | 222 | 130 | 8.75 | 8 | 287 |
| GF 6800UE | NV40 | 222 | 130 | 8.75 | 8 | 287 |
| DirectX 9 with PS2.0+ and VS2.0+ Support | ||||||
| GFFX 5200LE | NV34 | 45 | 150 | 9.50 | 8 | 91 |
| GFFX 5200 | NV34 | 45 | 150 | 9.50 | 8 | 91 |
| GFFX 5200U | NV34 | 45 | 150 | 9.50 | 8 | 91 |
| GFFX 5500 | NV34 | 45 | 150 | 9.50 | 8 | 91 |
| GFFX 5600XT | NV31 | 80 | 130 | 10.00 | 8 | 135 |
| GFFX 5600 | NV31 | 80 | 130 | 10.00 | 8 | 135 |
| GFFX 5600U | NV31 | 80 | 130 | 10.00 | 8 | 135 |
| GFFX 5700LE | NV36 | 82 | 130 | 9.50 | 8 | 125 |
| GFFX 5700 | NV36 | 82 | 130 | 9.50 | 8 | 125 |
| GFFX 5700U | NV36 | 82 | 130 | 9.50 | 8 | 125 |
| GFFX 5700UDDR3 | NV36 | 82 | 130 | 9.50 | 8 | 125 |
| GFFX 5800 | NV30 | 125 | 130 | 10.00 | 8 | 211 |
| GFFX 5800U | NV30 | 125 | 130 | 10.00 | 8 | 211 |
| GFFX 5900XT/SE | NV35 | 135 | 130 | 9.50 | 8 | 206 |
| GFFX 5900 | NV35 | 135 | 130 | 9.50 | 8 | 206 |
| GFFX 5900U | NV35 | 135 | 130 | 9.50 | 8 | 206 |
| GFFX 5950U | NV38 | 135 | 130 | 9.50 | 8 | 206 |
| DirectX 8 with PS1.3 and VS1.1 Support | ||||||
| GF3 Ti200 | NV20 | 57 | 150 | 10.00 | 8 | 128 |
| GeForce 3 | NV20 | 57 | 150 | 10.00 | 8 | 128 |
| GF3 Ti500 | NV20 | 57 | 150 | 10.00 | 8 | 128 |
| GF4 Ti4200 128 | NV25 | 63 | 150 | 10.00 | 8 | 142 |
| GF4 Ti4200 64 | NV25 | 63 | 150 | 10.00 | 8 | 142 |
| GF4 Ti4200 8X | NV25 | 63 | 150 | 10.00 | 8 | 142 |
| GF4 Ti4400 | NV25 | 63 | 150 | 10.00 | 8 | 142 |
| GF4 Ti4600 | NV25 | 63 | 150 | 10.00 | 8 | 142 |
| GF4 Ti4800 | NV25 | 63 | 150 | 10.00 | 8 | 142 |
| GF4 Ti4800 SE | NV25 | 63 | 150 | 10.00 | 8 | 142 |
| DirectX 7 | ||||||
| GeForce 256 SDR | NV10 | 23 | 220 | 10.00 | 8 | 111 |
| GeForce 256 DDR | NV10 | 23 | 220 | 10.00 | 8 | 111 |
| GF2 MX200 | NV11 | 20 | 180 | 10.00 | 8 | 65 |
| GF2 MX | NV11 | 20 | 180 | 10.00 | 8 | 65 |
| GF2 MX400 | NV11 | 20 | 180 | 10.00 | 8 | 65 |
| GF2 GTS | NV15 | 25 | 180 | 10.00 | 8 | 81 |
| GF2 Pro | NV15 | 25 | 180 | 10.00 | 8 | 81 |
| GF2 Ti | NV15 | 25 | 150 | 10.00 | 8 | 56 |
| GF2 Ultra | NV15 | 25 | 180 | 10.00 | 8 | 81 |
| GF4 MX420 | NV17 | 29 | 150 | 10.00 | 8 | 65 |
| GF4 MX440 SE | NV17 | 29 | 150 | 10.00 | 8 | 65 |
| GF4 MX440 | NV17 | 29 | 150 | 10.00 | 8 | 65 |
| GF4 MX440 8X | NV18 | 29 | 150 | 10.00 | 8 | 65 |
| GF4 MX460 | NV17 | 29 | 150 | 10.00 | 8 | 65 |
| ATI Die Sizes | ||||||
|
|
|
|
|
|
|
| DirectX 9 with PS2.0b and VS2.0 Support | ||||||
| X800 SE? | R420 | 160 | 130 | 9.75 | 8 | 257 |
| X800 Pro | R420 | 160 | 130 | 9.75 | 8 | 257 |
| X800 GT? | R420 | 160 | 130 | 9.75 | 8 | 257 |
| X800 XT | R420 | 160 | 130 | 9.75 | 8 | 257 |
| X800 XT PE | R420 | 160 | 130 | 9.75 | 8 | 257 |
| DirectX 9 with PS2.0 and VS2.0 Support | ||||||
| 9500 | R300 | 107 | 150 | 9.00 | 8 | 195 |
| 9500 Pro | R300 | 107 | 150 | 9.00 | 8 | 195 |
| 9550 SE | RV350 | 75 | 130 | 8.50 | 8 | 92 |
| 9550 | RV350 | 75 | 130 | 8.50 | 8 | 92 |
| 9600 SE | RV350 | 75 | 130 | 8.50 | 8 | 92 |
| 9600 | RV350 | 75 | 130 | 8.50 | 8 | 92 |
| 9600 Pro | RV350 | 75 | 130 | 8.50 | 8 | 92 |
| 9600 XT | RV360 | 75 | 130 | 8.50 | 8 | 92 |
| 9700 | R300 | 107 | 150 | 9.00 | 8 | 195 |
| 9700 Pro | R300 | 107 | 150 | 9.00 | 8 | 195 |
| 9800 SE | R350 | 115 | 150 | 9.00 | 8 | 210 |
| 9800 | R350 | 115 | 150 | 9.00 | 8 | 210 |
| 9800 Pro | R350 | 115 | 150 | 9.00 | 8 | 210 |
| 9800 XT | R360 | 115 | 150 | 9.00 | 8 | 210 |
| X300 SE | RV370 | 75 | 110 | 9.00 | 8 | 74 |
| X300 | RV370 | 75 | 110 | 9.00 | 8 | 74 |
| X600 Pro | RV380 | 75 | 130 | 8.50 | 8 | 92 |
| X600 XT | RV380 | 75 | 130 | 8.50 | 8 | 92 |
| DirectX 8.1 with PS1.4 and VS1.1 Support | ||||||
| 8500 LE | R200 | 60 | 150 | 10.00 | 8 | 135 |
| 8500 | R200 | 60 | 150 | 10.00 | 8 | 135 |
| 9000 | RV250 | 36 | 150 | 10.00 | 8 | 81 |
| 9000 Pro | RV250 | 36 | 150 | 10.00 | 8 | 81 |
| 9100 | R200 | 60 | 150 | 10.00 | 8 | 135 |
| 9100 Pro | R200 | 60 | 150 | 10.00 | 8 | 135 |
| 9200 SE | RV280 | 36 | 150 | 10.00 | 8 | 81 |
| 9200 | RV280 | 36 | 150 | 10.00 | 8 | 81 |
| 9200 Pro | RV280 | 36 | 150 | 10.00 | 8 | 81 |
| DirectX 7 | ||||||
| Radeon VE | RV100 | 30? | 180 | 10.00 | 8 | 97 |
| 7000 PCI | RV100 | 30? | 180 | 10.00 | 8 | 97 |
| 7000 AGP | RV100 | 30? | 180 | 10.00 | 8 | 97 |
| Radeon LE | R100 | 30 | 180 | 10.00 | 8 | 97 |
| Radeon SDR | R100 | 30 | 180 | 10.00 | 8 | 97 |
| Radeon DDR | R100 | 30 | 180 | 10.00 | 8 | 97 |
| 7200 | R100 | 30 | 180 | 10.00 | 8 | 97 |
| 7500 LE | RV200 | 30 | 150 | 10.00 | 8 | 68 |
| 7500 AIW | RV200 | 30 | 150 | 10.00 | 8 | 68 |
| 7500 | RV200 | 30 | 150 | 10.00 | 8 | 68 |
After all that, we finally get to the chart of die sizes. That was a lot of work for what might be considered a small reward, but there is a reason for all this talk of die sizes. If you look at the charts, you should notice one thing looking at the history of modern GPUs: die sizes are increasing exponentially on the high end parts. This is not a good thing at all.
AMD and Intel processors vary in size over time, depending on transistor counts, process technology, etc. However, they both try to target a "sweet spot" in terms of size that maximizes yields and profits. Smaller is almost always better, all other things being equal, with ideal sizes generally being somewhere in between 80 mm2 and 120 mm2. Larger die sizes mean that there are fewer chips per wafer, and there are more likely to be errors in an individual chip, decreasing yields. There is also a set cost per wafer, so whether you can get 50 or 500 chips out of the wafer, the cost remains the same. ATI and NVIDIA do not necessarily incur these costs, but their fabrication partners do, and it still affects chip output and availability. Let's look at this a little closer, though.
On 300 mm wafers, you have a total surface area of 70,686 mm2 (pi * r2; r = 150 mm). If you have a 130 mm2 chip, you could get approximately 500 chips out of a wafer, of which a certain percentage will have flaws. If you have a 200 mm2 chip, you could get about 320 chips, again with a certain percentage having flaws. With a 280 mm2 like the NV40 and R420, we're down to about 230 chips per wafer. So just in terms of the total number of dies to test, we see how larger die sizes are undesirable. Let's talk about the flaws, though.
The percentage of chips on a wafer that are good is called the yield. Basically, there are an average number of flaws in any wafer, more or less distributed evenly. With that being the case, each flaw will normally affect one chip, although if there are large numbers of flaws you could get several defects per chip. As an example, let's say there are on average 50 flaws per wafer. That means there will typically be 50 failed chips on each wafer. Going back to the chip sizes and maximum dies listed above, we can now get an estimated yield. With 130 mm2 dies, we lose about 50 out of 500, so the yield would be 90%, which is very good. With 200 mm2 dies, we lose about 50 out of 320, so now the yield drops to 84%. On the large 280 mm2 dies, we now lose 50 out of 230, and yield drops to 78%. Those are just examples, as we don't know the exact details of the TSMC and IBM fabrication plants, but it should suffice to illustrate how large die sizes are not at all desirable.
Now, look at the die size estimates, and you'll see that from the NV10 and R100 we have gone from a typical die size of +/- 100 mm2 in late 1999 to around 200 mm2 in mid 2002 on the R300, and we're now at around 280 mm2 in mid 2004. Shrinking to 90 nm process technology would reduce die sizes by about half compared to 130 nm, but AMD is just now getting their 90 nm parts out, and it may be over a year before 90 nm becomes available for fabless companies like ATI and NVIDIA. It's going to be interesting seeing how the R5xx and NV5x parts shape up, as simply increasing the number of vertex and pixel pipelines beyond current levels is going to be difficult without shifting to a 90 nm process.
All is not lost, however. Looking at the mid-range market, you can see how these parts manage to be priced lower, allowing them to sell in larger volumes. Most of these parts remain under 150 mm2 in size, and quite a few of the parts remain under 100 mm2. It's no surprise that ATI and NVIDIA sell many more of their mid-range and low-end parts than high-end parts, since few non-gamers have a desire to spend $500 on a graphics card when they could build an entire computer for that price. Really, though, these parts are mid-range because they can be, while the high-end parts really have to be in that segment. Smaller sizes bring higher yields and higher supply, resulting in lower prices. Conversely, larger sizes bring lower yields and a lower supply, so prices go up. We especially see this early on: if demand is great enough for the new cards, we get instances like the recent 6800 and X800 cards where parts are selling for well over MSRP.
Wrapping it All Up
So, that's an overview of the recent history of graphics processors. For those that are impressed by the rate of progress in the CPU world, it pales in comparison to recent trends in 3D graphics. Just looking at raw theoretical performance, since the introduction of the "World's First Graphics Processing Unit GPU", the GeForce 256, 3D chips have become about 20 times as fast. That doesn't even take into account architectural optimizations that actually allow chips to come closer to their theoretical performance, or the addition of programmability in DX8 and later chips. Taken together with the raw performance increases, it is probably safe to say that GPUs have become roughly 30 times faster since their introduction. We often hear of "Moore's Law" in regards to CPUs, which is usually paraphrased as being a doubling of performance every 18 to 24 months. (The actual paper from Moore has more to do with optimal transistor counts for maximizing profits than performance.) In comparison, "Moore's Law" for 3D graphics has been double the performance every 12 months.
The amazing thing is that we are still pushing the limits of the current technology. Sure, the 6800 Ultra and X800 XT are fast enough to run all current games with 4xAA and 8xAF turned on, but some programmer out there is just waiting for more power. The Unreal Engine 3 images that have been shown are truly impressive, and even the best cards of today struggle to meet the demands. The goal of real-time Hollywood quality rendering is still a ways off, but only a few years ago Pixar scoffed when NVIDIA claimed they were approaching the ability to do Toy Story 2 visuals in real time. Part of their rebuttal was that Toy Story 2 was using something like 96 GB/s of bandwidth for their textures. We're one third of the way there now!
What does the future hold? With the large sizes of the top GPUs, it is probably safe to bet that newer features (i.e. DirectX 10) are going to be at least a year or more in the future. This is probably a good thing, as it will give ATI and NVIDIA (and their fabrication partners) time to shrink the die process and hopefully start making more cards available. We may not even see DirectX 10 hardware for 18 months, as it is planned as part of the next version of Windows, codenamed Longhorn. Longhorn is currently slated for a 2006 release, so there isn't much point in selling hardware that is completely lacking in software support at the OS and library level.
Those looking for lower prices may be in for something of a disappointment. Lower prices would always be nice, but the trend with the bleeding edge hardware is that it is only getting more expensive with each successive generation. Look at the NVIDIA top-end cards: GeForce 256 DDR launched at about $300, GeForce 2 Ultra and GeForce 3 launched at around $350, GeForce 4 Ti4600 was close to $400, GeForce FX 5800 Ultra and 5950 Ultra were close to $500 at launch, and recently the 6800 Ultra has launched at over $500. More power is good, but not everyone has the funds to buy FX-53 or P4EE processors and matching system components. However, today's bleeding edge hardware is tomorrow's mainstream hardware, so while not everyone can afford a 6800 or X800 card right now, the last generation of high-end hardware is now selling for under $200, and even the $100 parts are better than the GeForce 3 era.






