AMD Zen 3 Ryzen Deep Dive Review: 5950X, 5900X, 5800X and 5600X Tested
by Dr. Ian Cutress on November 5, 2020 9:01 AM ESTCPU Tests: Simulation
Simulation and Science have a lot of overlap in the benchmarking world, however for this distinction we’re separating into two segments mostly based on the utility of the resulting data. The benchmarks that fall under Science have a distinct use for the data they output – in our Simulation section, these act more like synthetics but at some level are still trying to simulate a given environment.
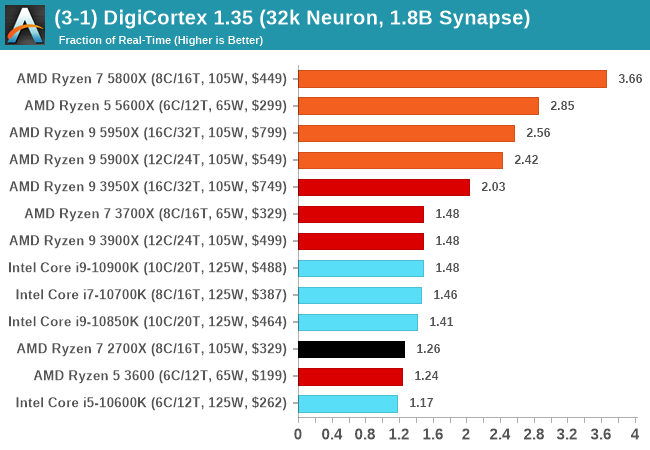
DigiCortex v1.35: link
DigiCortex is a pet project for the visualization of neuron and synapse activity in the brain. The software comes with a variety of benchmark modes, and we take the small benchmark which runs a 32k neuron/1.8B synapse simulation, similar to a small slug.
The results on the output are given as a fraction of whether the system can simulate in real-time, so anything above a value of one is suitable for real-time work. The benchmark offers a 'no firing synapse' mode, which in essence detects DRAM and bus speed, however we take the firing mode which adds CPU work with every firing.
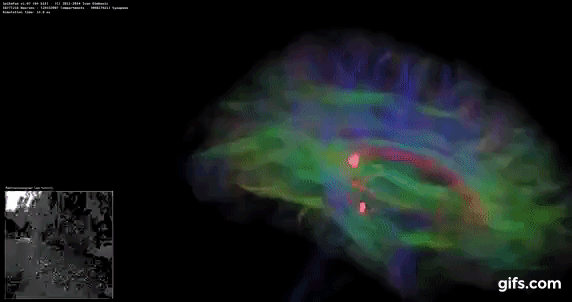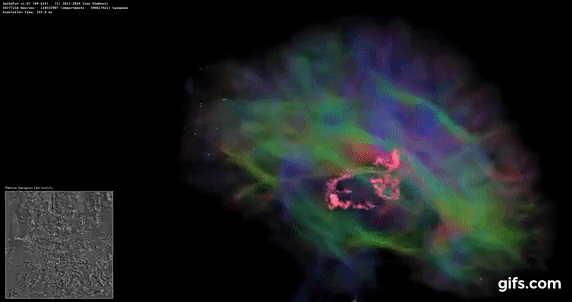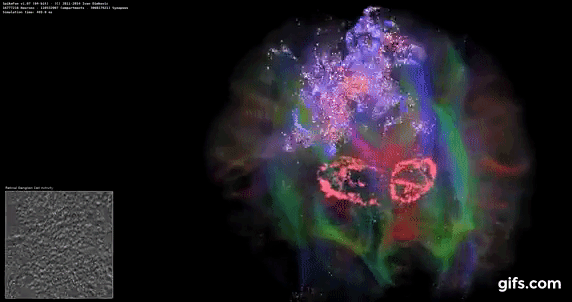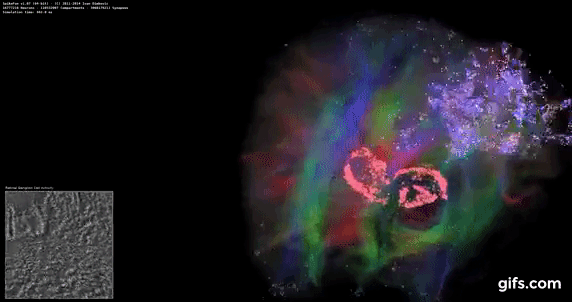
The software originally shipped with a benchmark that recorded the first few cycles and output a result. So while fast multi-threaded processors this made the benchmark last less than a few seconds, slow dual-core processors could be running for almost an hour. There is also the issue of DigiCortex starting with a base neuron/synapse map in ‘off mode’, giving a high result in the first few cycles as none of the nodes are currently active. We found that the performance settles down into a steady state after a while (when the model is actively in use), so we asked the author to allow for a ‘warm-up’ phase and for the benchmark to be the average over a second sample time.
For our test, we give the benchmark 20000 cycles to warm up and then take the data over the next 10000 cycles seconds for the test – on a modern processor this takes 30 seconds and 150 seconds respectively. This is then repeated a minimum of 10 times, with the first three results rejected. Results are shown as a multiple of real-time calculation.
Dwarf Fortress 0.44.12: Link
Another long standing request for our benchmark suite has been Dwarf Fortress, a popular management/roguelike indie video game, first launched in 2006 and still being regularly updated today, aiming for a Steam launch sometime in the future.
Emulating the ASCII interfaces of old, this title is a rather complex beast, which can generate environments subject to millennia of rule, famous faces, peasants, and key historical figures and events. The further you get into the game, depending on the size of the world, the slower it becomes as it has to simulate more famous people, more world events, and the natural way that humanoid creatures take over an environment. Like some kind of virus.
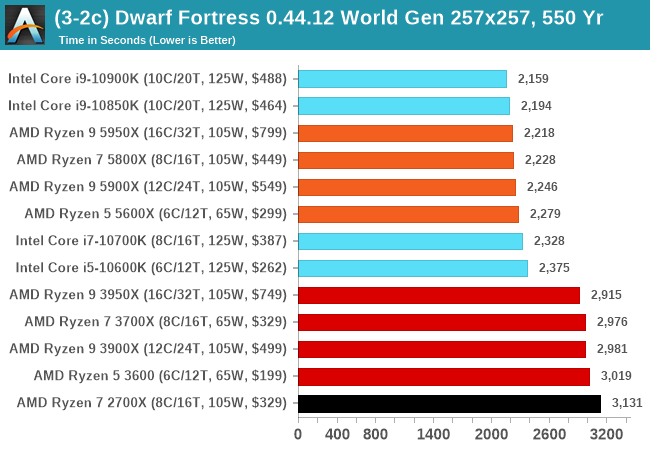
For our test we’re using DFMark. DFMark is a benchmark built by vorsgren on the Bay12Forums that gives two different modes built on DFHack: world generation and embark. These tests can be configured, but range anywhere from 3 minutes to several hours. After analyzing the test, we ended up going for three different world generation sizes:
- Small, a 65x65 world with 250 years, 10 civilizations and 4 megabeasts
- Medium, a 127x127 world with 550 years, 10 civilizations and 4 megabeasts
- Large, a 257x257 world with 550 years, 40 civilizations and 10 megabeasts
DFMark outputs the time to run any given test, so this is what we use for the output. We loop the small test for as many times possible in 10 minutes, the medium test for as many times in 30 minutes, and the large test for as many times in an hour.


Dolphin v5.0 Emulation: Link
Many emulators are often bound by single thread CPU performance, and general reports tended to suggest that Haswell provided a significant boost to emulator performance. This benchmark runs a Wii program that ray traces a complex 3D scene inside the Dolphin Wii emulator. Performance on this benchmark is a good proxy of the speed of Dolphin CPU emulation, which is an intensive single core task using most aspects of a CPU. Results are given in seconds, where the Wii itself scores 1051 seconds.









339 Comments
View All Comments
Orkiton - Thursday, November 5, 2020 - link
Please Anandtech, up ryzen and up epic your servers, it's ages here to load a page...PrionDX - Thursday, November 5, 2020 - link
Mmm nice warm code bath, very relaxing> Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath.
prophet001 - Thursday, November 5, 2020 - link
How you gonna test FFXIV and not WoW.-______________-
Mr Perfect - Thursday, November 5, 2020 - link
Guys, could you please define acronyms the first time they are used in an article? Take page three for example, it touches on a BTB, TAGE and ITA, but only ITA is defined. I have no idea what a BTB or TAGE is. If they where defined on page two and I missed them, feel free to ignore me.name99 - Saturday, November 7, 2020 - link
BTB= Branch Target Buffer. Holds the addresses where a branch will go if it taken.TAGE= (tagged geometric something-or-other) name is not important; what matters is that it's currently the most accurate known branch predictor. Comes in a few variants, was 1st published around 2007 by Andre Seznec who has since gone on to show how it can be used for damn well everything! (Value prediction, indirect branch, prefetching, washing windows, you name it.)
Apple seems to have been first to implement, maybe as early as the A7, certainly very soon in the A series.
Now everybody uses it, but only in the last year or so has everyone really got on board. (Actually to be precise Seznec suggested that Intel is using TAGE based on their performance characteristics, but I don't think Intel have confirmed this. And ARM probably are but again unconfirmed. IBM is confirmed, and now AMD.)
Even if you know the basic algorithm for direction prediction is TAGE, that still doesn't make everyone equal. There are MANY extra aspects where everyone is different. The most obvious is how much storage is given to the branch predictor, but other less obvious aspects include
- how do you predict indirect branches? State of the art is ITTAGE, but that doesn't mean everyone is using it.
- how do you update your branch prediction storage (ie how fast do corrections get from the backend into the predicting mechanism at the front end)
- how do you implement your L2 storage and second-stage prediction?
- what extra "specialist" predictors do you have? (These are things like special-case predictors for loops.)
quantcon - Thursday, November 5, 2020 - link
Yeah, it's actually kinda nuts, considering Intel convinced us years ago that we've hit the point of diminishing returns and there are hardly any IPC improvements to be had.Spunjji - Sunday, November 8, 2020 - link
Seems like they needed to believe that...DanD85 - Thursday, November 5, 2020 - link
This just goes on to prove yet again how crucial a healthy competition benefits everyone. Intel has been stagnating for more than a decade. Imagine where we would have been performance-wise if we had got this ~40% increase every 3 years. Intel only have themselves to blame. They are the chipzillla, the gatekeeper and the choker of the whole industry!lmcd - Monday, November 9, 2020 - link
40% is a bit disingenuous. Most of the gap in desktop is chiplet design. Notice how mobile, while AMD-favored, is still competitive? It's just a bad bet from Intel going with stacked packaging before same-package flat chiplet, and the packaging techniques for both are very new. There aren't 40% improvements on the table going forward, Bulldozer and Piledriver were both just awful and AMD didn't ever release full desktop Steamroller or Excavator (which were fine, not great). Zen 1 left a lot on the table for such a big increase as well.GeoffreyA - Tuesday, November 10, 2020 - link
If you place Zen at Haswell's level, it took AMD three years to reach Zen 3 (from the consumer's point of view). On Intel's side, it's taken six years to go from Haswell to Sunny Cove.Even in the early tick-tock days, when more massive changes could be put in, it was usually two years apart for microarchitecture: Core (2006), Nehalem (2008), Sandy Bridge (2010/11), etc.
Whether there's a lot more juice in the tank for Zen remains to be seen. In my opinion I think there is: Z3's out-of-order structures are still quite conservative, compared to Sunny Cove, which it beats, so there's possibility of more widening there. I also think their split scheduler design, inherited from the Athlon, will allow them to scale more easily. Of course, I know the engineers in Haifa must be cooking up something potent too. Either way, exciting stuff.