Intel Unveils Lunar Lake Architecture: New P and E cores, Xe2-LPG Graphics, New NPU 4 Brings More AI Performance
by Gavin Bonshor on June 3, 2024 11:00 PM ESTIntel Lunar Lake: New E-Core, Skymont Takes Flight For Peak Efficiency
Intel also opts for their Skymont E-cores, which are designed more for efficiency while maintaining a solid level of performance at a lower power envelope.

The Skymont cores feature a significantly broader decode architecture, with a 9-wide decode stage that includes 50% more decode clusters than previous generations. This is supported by a larger micro-op queue, which now holds 96 entries compared to 64 in the previous Crestmont E-Cores.

Intel has improved the out-of-order execution engine by boosting the allocation width from 4 to 8 and the retire width from 8 to 16. The next-gen Skymont core is supposed to surpass Crestmont E-Cores with double the allocation and retire width in terms of its ability to commit and run out-of-order instructions, decreasing overall latency and minimizing stalling for data dependencies.

Queuing and buffering capabilities have also been improved within the Skymont E-Core. It features a deeper reorder buffer of 416 entries, up from the previous 256, while Intel claims the size of the physical register files (PRF) and INT, MEM, and Vectors have been made deeper, too.
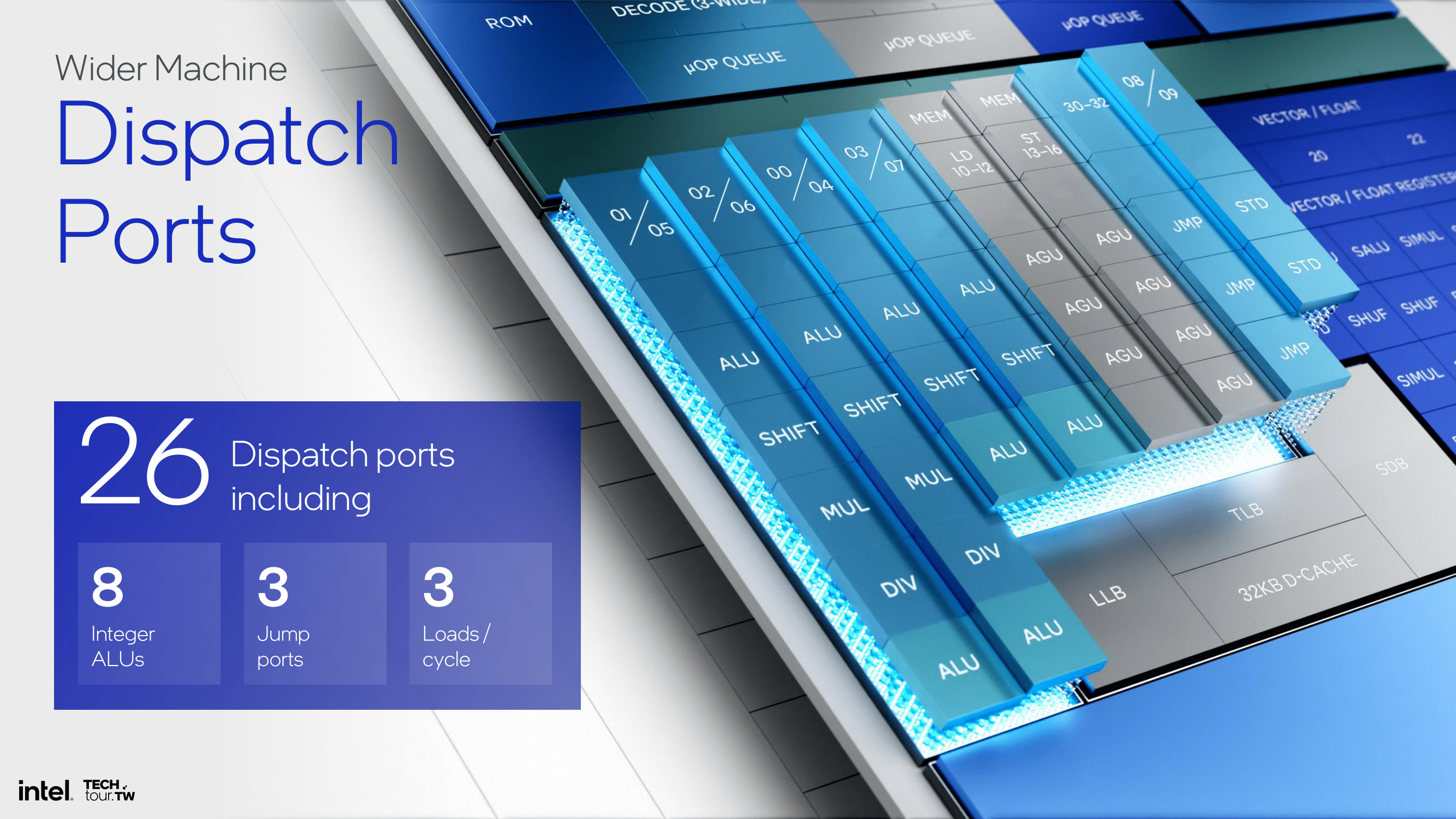
Focusing on dispatch ports, Intel has opted for a similar approach to Crestmont. This includes 26 dispatch ports, 8 integer ALUs, 3 Jump Ports, and 3 for load operations per cycle. Regarding Vector performance, Skymont supports 4x128-bit FP and SIMD vectors, which doubles gigaflops/TOPs and reduces latency for floating-point operations.
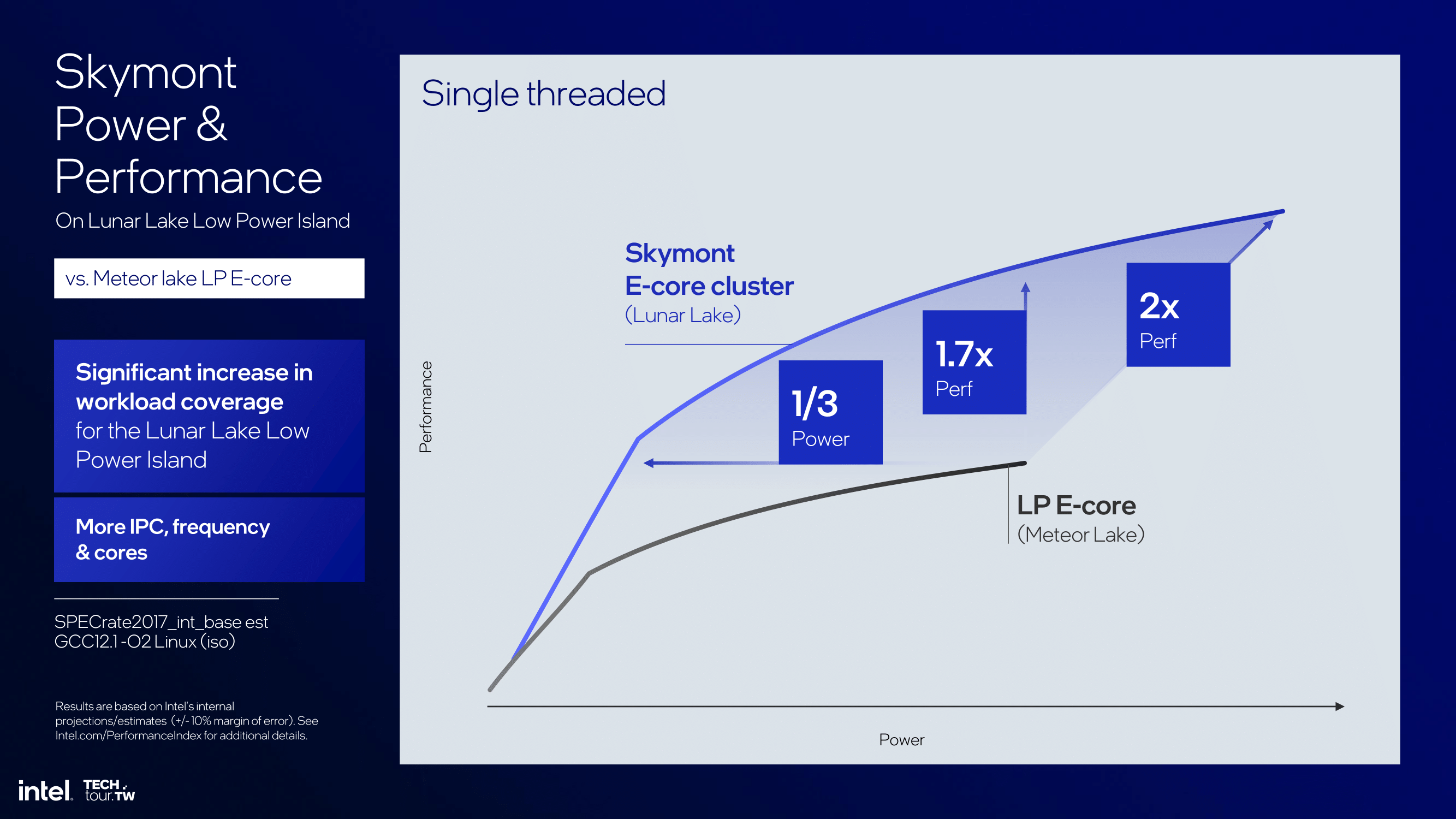
Intel does provide some figures highlighting Skymont's power efficiency and performance when compared directly to the Low Power Island E-Cores included on the SoC tile on Meteor Lake. In this particular line chart, Intel increases single-threaded performance by 1.7X while consuming just one-third of the power relative to Meteor Lake's LP E-cores.
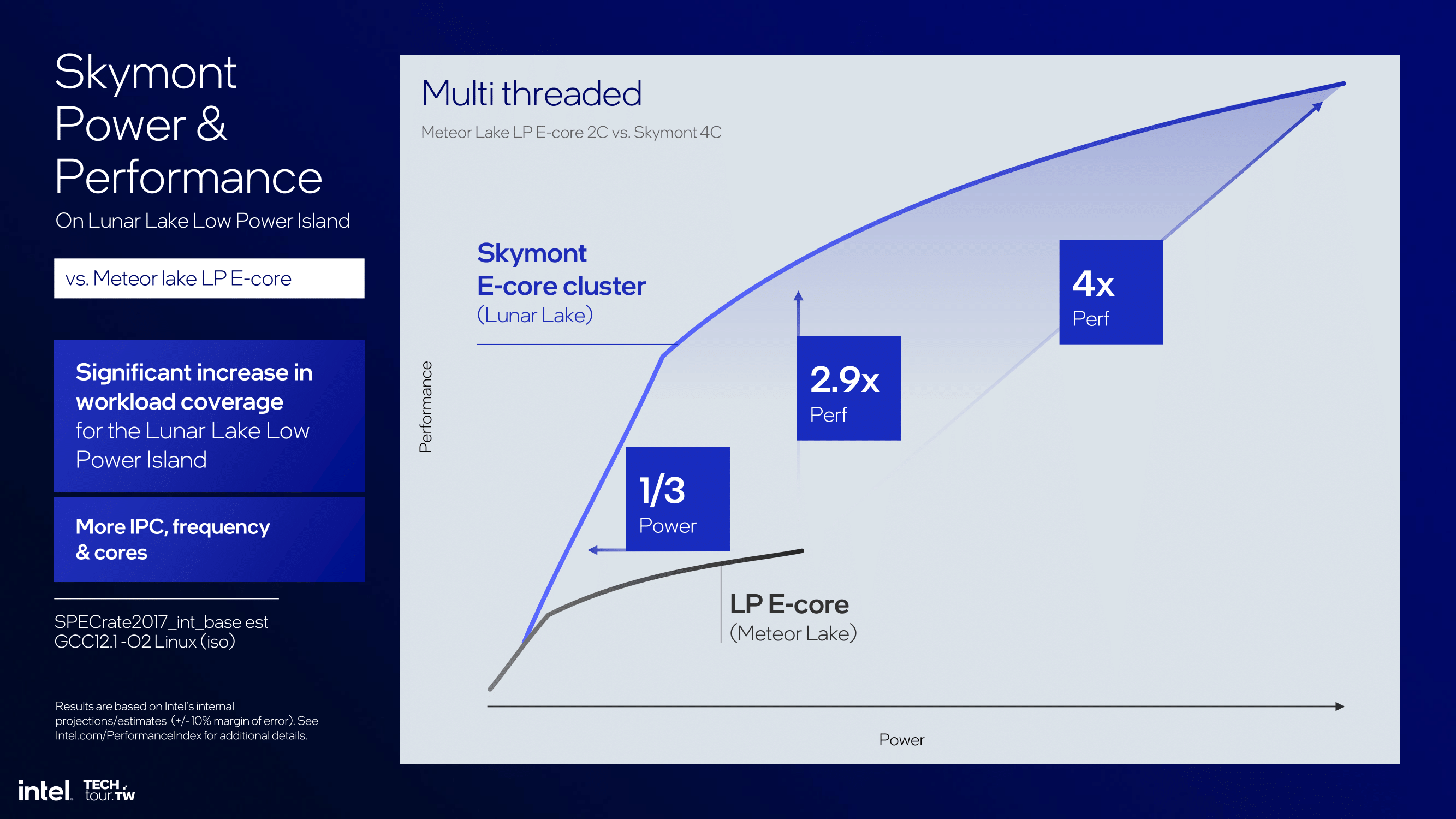
Looking at multi-threaded performance, Intel puts Skymont 2.9X faster at 1/3rd of the power requirements when compared to Meteor Lake and the LP E-cores. It's worth noting that the Skymont E-Core cluster on the compute tile has double the cores of the Meteor Lake LP E-Core cluster (4 vs. 2), so performance is expected to be higher overall.
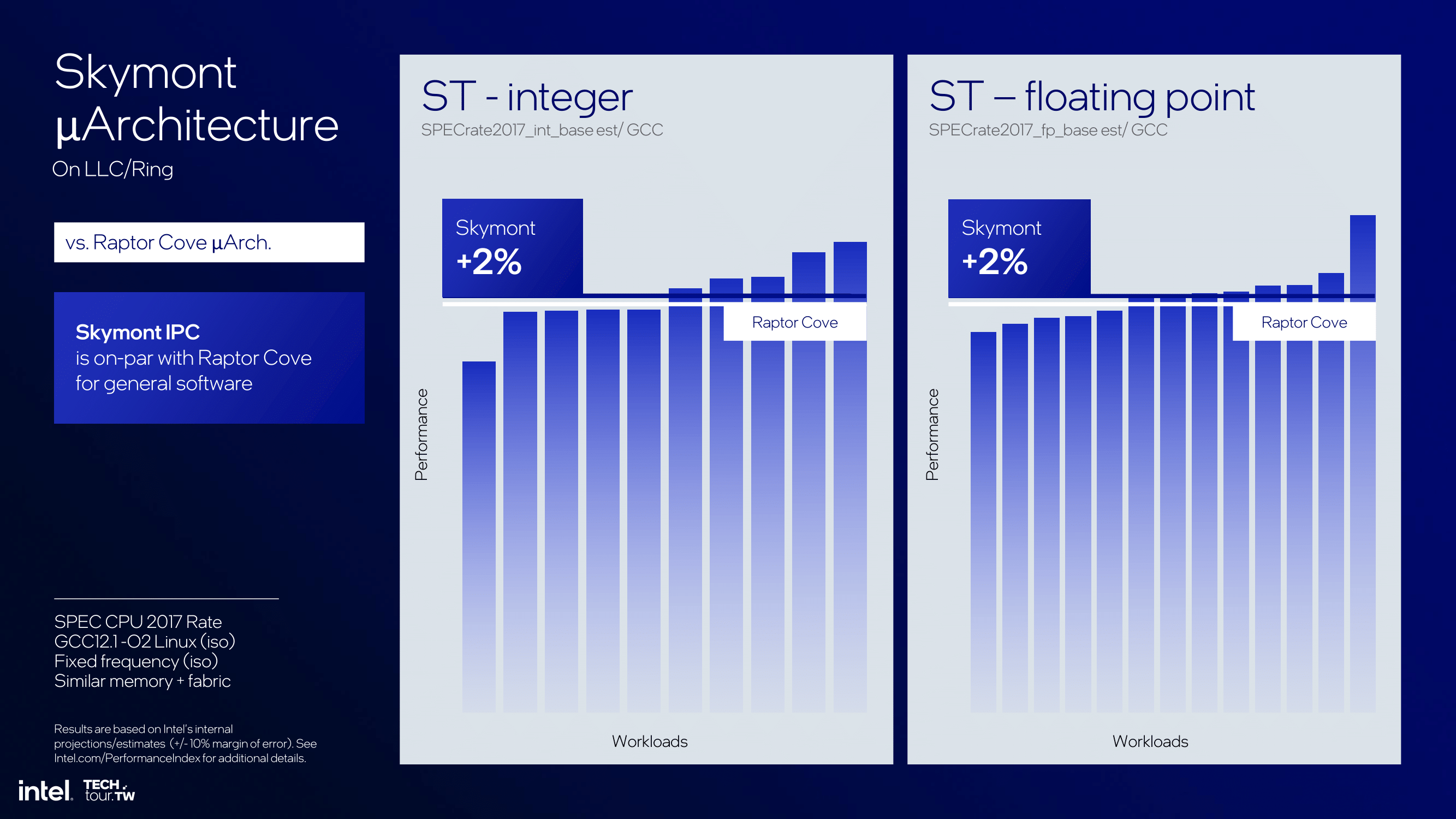
Due to their low-powered nature for mobile devices such as notebooks, the Skymont E-cores are designed to be very flexible, with some leverage over previous E-Core architectures. Compared to Raptor Cove, Skymont offers 2% better integer and floating-point performance in single-threaded workloads, with a power and thermal envelope almost identical to Raptor Cove. This is in a more desktop-friendly environment, as Intel does depict the data with the Skymont cores on an LLC or a Ring Bus. This is E-Cores versus the previous gen of P-Cores, in which Intel is claiming a 2% lead.

Intel's Skymont E-cores represent the next leap in Intel's architectural development. According to Intel's disclosure, Skymont looks to be a marked improvement in multiple areas over the previous Crestmont E-Core, including decoding, execution, memory subsystems, and power efficiency. While Intel discloses them as E-Cores, the messaging surrounding Skymont is a little confusing.
The easiest way to decipher this is that they are similar to the two LP E-Cores within the Meteor Lake SoC tile, but with Lunar Lake, they are in a cluster of four built onto the compute tile. On Lunar Lake, they will be as efficient as the LP E-cores of old, but for desktop, they will be in a cluster on the chips Ring Bus, meaning they will likely be similar to the traditional E-cores we've seen before with Intel's 14th/13th/12th Gen Core families.








91 Comments
View All Comments
kwohlt - Tuesday, June 4, 2024 - link
20A is best thought of as an internal only, early sampling of 18A for use on the Compute Tile.But LNL differs from ARL in that its compute tile also contains the iGPU and NPU, making 20A not an appropriate choice. 18A would've been the node Intel would've needed, but that's not until next year (coincidently, LNL's direct successor, PNL, will use 18A for it's unified compute tile instead of TSMC) Reply
Blastdoor - Wednesday, June 5, 2024 - link
Or we could take it to mean that intel reserved a lot of N3B capacity and so figured they might as well use it. Like Apple, they will probably be looking to get off of N3B ASAP. While Apple moves to N3E, Intel will leap ahead to A18. ReplyThe Hardcard - Wednesday, June 5, 2024 - link
Barring newly announced delays, TSMC will hit volume on N2 in the same timeframe as volume on Intel A18. Apple’s move to N3E has happened. N2 in 2025. Replyrgreen1983 - Tuesday, June 4, 2024 - link
"This uplift is noticed, especially in the betterment of its hyper-threading, whereby improved IPC by 30%, dynamic power efficiency improved by 20%, and previous technologies, in balancing, without increasing the core area, in a commitment of Intel to better performance, within existing physical constraints."So hyper threading is bother present and improved, yet they disabled it? This seems non sensical Reply
meacupla - Tuesday, June 4, 2024 - link
From what I have read and seen from other tech sites, Intel disabled HT because it wasn't working properly with E-cores.Disabling HT improves performance and efficiency, because the E-cores get utilized, instead of sitting idle on low power loads. Reply
rgreen1983 - Tuesday, June 4, 2024 - link
I'm not asking why they disabled HT, we've known they were going to disable HT for some time. Disabling HT out of the box doesn't do anything because we've always been able to disable HT ourselves. I'm asking why they improved it if they are going to disable it, why waste a bunch of transistors and die area on a disabled feature? And if maybe the decision came too late to be removed, why brag about a thing that isn't even enabled? ReplyDrumsticks - Tuesday, June 4, 2024 - link
Unfortunately, this feels like word salad from Anandtech. I won’t speculate how or why it was left in, or why Anandtech is quoting a 30% gain in IPC that is nowhere in Intel’s slides or on other tech website coverage.They didn’t improve hyperthreading and then disable it. They removed the feature completely, and netted the die area and power savings from doing so. They probably also took a MT loss, but the die area and power savings could have been redirected to either better usage of the area for more performance, or just direct cost and efficiency savings. Intel’s hyperthreading was always a really inefficient way to gain a small amount of performance anyways. The actual side, published on Techpowerup’s dive, says removing hyperthreading saved them 5% perf/power, 15% perf/area, and 15% perf/power/area. That slide doesn’t appear to be published on Anandtech.
Essentially, they didn’t waste a bunch of transistors on a disabled feature - they did the obvious thing and physically removed the feature from the die. The description here is Anandtech’s fault, not Intel’s. Reply
rgreen1983 - Tuesday, June 4, 2024 - link
Thank you for your reply and the suggestion to check the techpowerup article. I would expect you are correct like the techpowerup article that HT was removed from the design and silicon, but I've also just read the pcworld lunar lake article which seems to suggest otherwise and amazingly has a slide not found in the techpowerup or anandtech articles.What I think might be going on is that lion cove still has HT in the design because Intel wants it for server chips, although I'd argue it's not necessary there either and by the looks of their recent all E core xeons the thread count sensitive clients should be running those anyways. That would explain why they might improve HT. If that is the case is there 2 lion cove designs, one with HT and another without? I just read the wccftech article which suggests this is the case, mentioning "variants" of lion cove.
Since this lion cove core for lunar lake is being made at tsmc, it makes sense they had to make a new design for their fab anyways so maybe they did remove HT, and wccftech says they removed TSX and AMX also. So the lion cove for Intel fab coming to arrow lake/xeon might have HT, will definitely have TSX and AMX, but they might still turn HT off and only enable for xeon.
Regardless yeah the anandtech mention of HT improvements here in relation to lunar lake seems off base. But I still think there is more Intel could clear up on HT status on die and whether there are multiple lion cove designs. Reply
Drumsticks - Tuesday, June 4, 2024 - link
I think they (techpowerup and pcworld) are both right. Per Tomshardware, commenting on Intel removing HT:"As such, Intel architected two versions of the Lion Cove core, one with and one without hyperthreading, so that the threaded Lion Cove core can be used in other applications, like we see in the forthcoming Xeon 6 processors."
I expect the LNL physical design lacks HT, as that's the only way to actually get the performance/area and performance/watt savings. But we'll probably see the version of Lion Cove with hyper threading show up in the Xeon world (although, to be honest, I'm not sure if it's worth it there given the efficiency losses), as well as on Arrow Lake, where higher performance in exchange for an efficiency loss tends to be an acceptable tradeoff for PC Enthusiasts.
The Tomshardware article also points out to me where Anandtech's article summary gets the 30% number: "Intel’s architects concluded that hyperthreading, which boosts IPC by ~30% in heavily threaded workloads, isn’t as relevant in a hybrid design that leverages the more power- and area-efficient E-cores for threaded workloads." - this is coupled with yet another slide that shows Intel quoting hyperthreading as a +30% throughput for +20% Cdyn.
In other words, I think *lunar lake* does not feature hyperthreading - it's physically non-present in the design. Lion Cove the P-Core microarchitecture, on the other hand, has two designs - one with HT physically present (in Arrow Lake and any Xeon SKUs - speculation), and one without (in Lunar Lake only).
On that note, it also implies two different Modules for e-core as well - one with the e-cores not present on the ring bus (in Lunar Lake) and one where it's connected to the ring bus like "normal"
- this being the config in Alder Lake and Raptor Lake (and this is presumably coming in Arrow Lake higher power laptop SKUs and the desktop) Reply
rgreen1983 - Wednesday, June 5, 2024 - link
Thank you for indulging me in this detailed discussion. I think you are right there are 2 lion cove designs. I don't think all the news outlets are aware of it. Reply