The Qualcomm Snapdragon X Architecture Deep Dive: Getting To Know Oryon and Adreno X1
by Ryan Smith on June 13, 2024 9:00 AM ESTPerformance Promises and First Thoughts
Wrapping things up, let’s touch upon a couple of Qualcomm’s performance slides before closing out this architectural deep dive. While the whole world will get to see what the Snapdragon X can do first-hand next week when retail devices launch, until then it gives us a bit more insight into what to expect. Just be sure to take it with the requisite grain of salt.
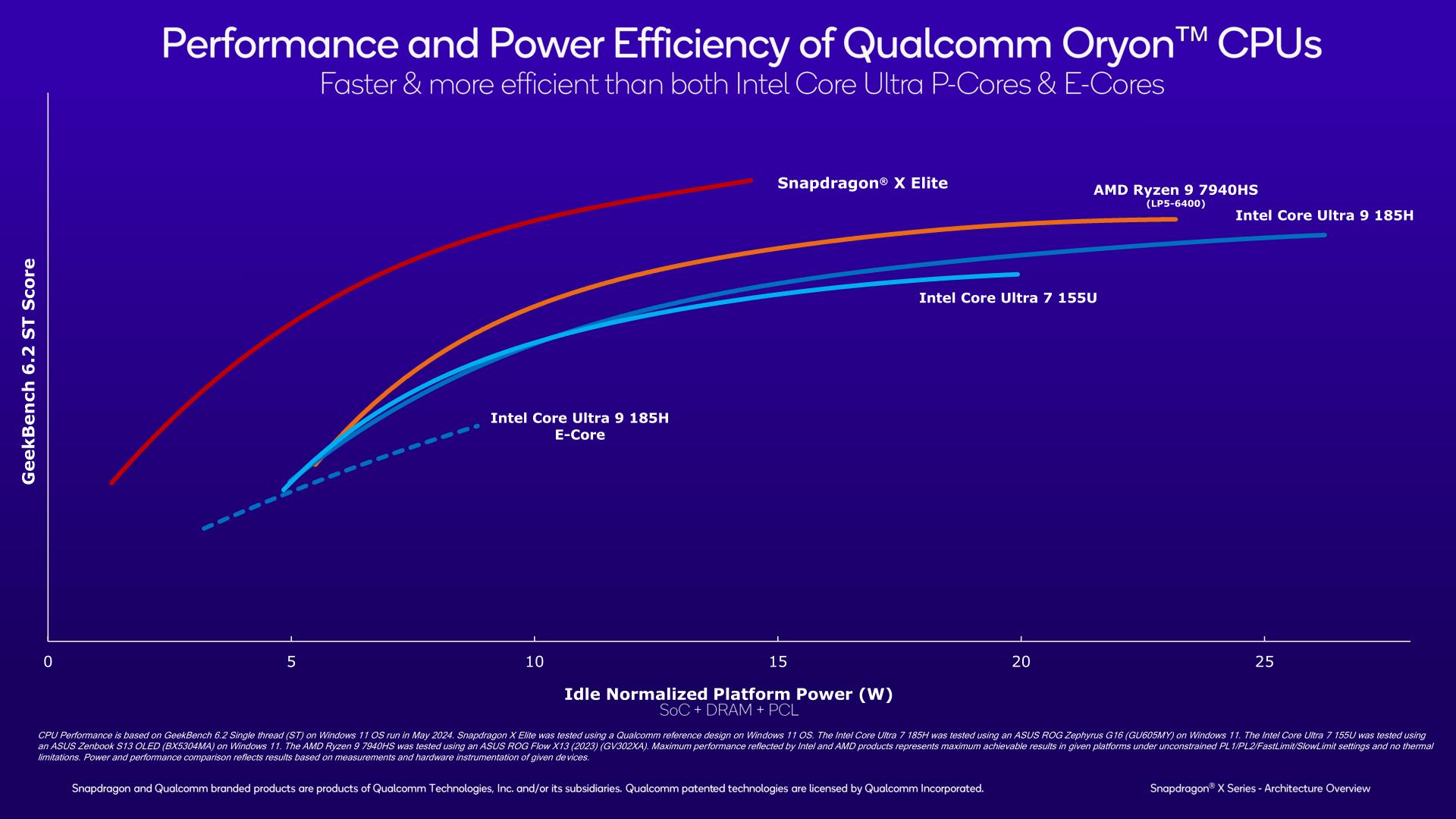
On the CPU side of matters, Qualcomm is claiming that the Snapdragon X Elite can beat the entire field of contemporary PC competitors in GeekBench 6.2 single-threading. And by a significant degree, too, when power efficiency is taken into account.
In short, Qualcomm claims that the Oryon CPU core in the Snapdragon X Elite can beat both Redwood Cove (Meteor Lake) and Zen 4 (Phoenix) in absolute performance, even if the x86 cores are allowed unrestricted TDPs. With mobile x86 chips turboing as high as 5GHz it’s a bold claim, but not out of the realm of possibility.
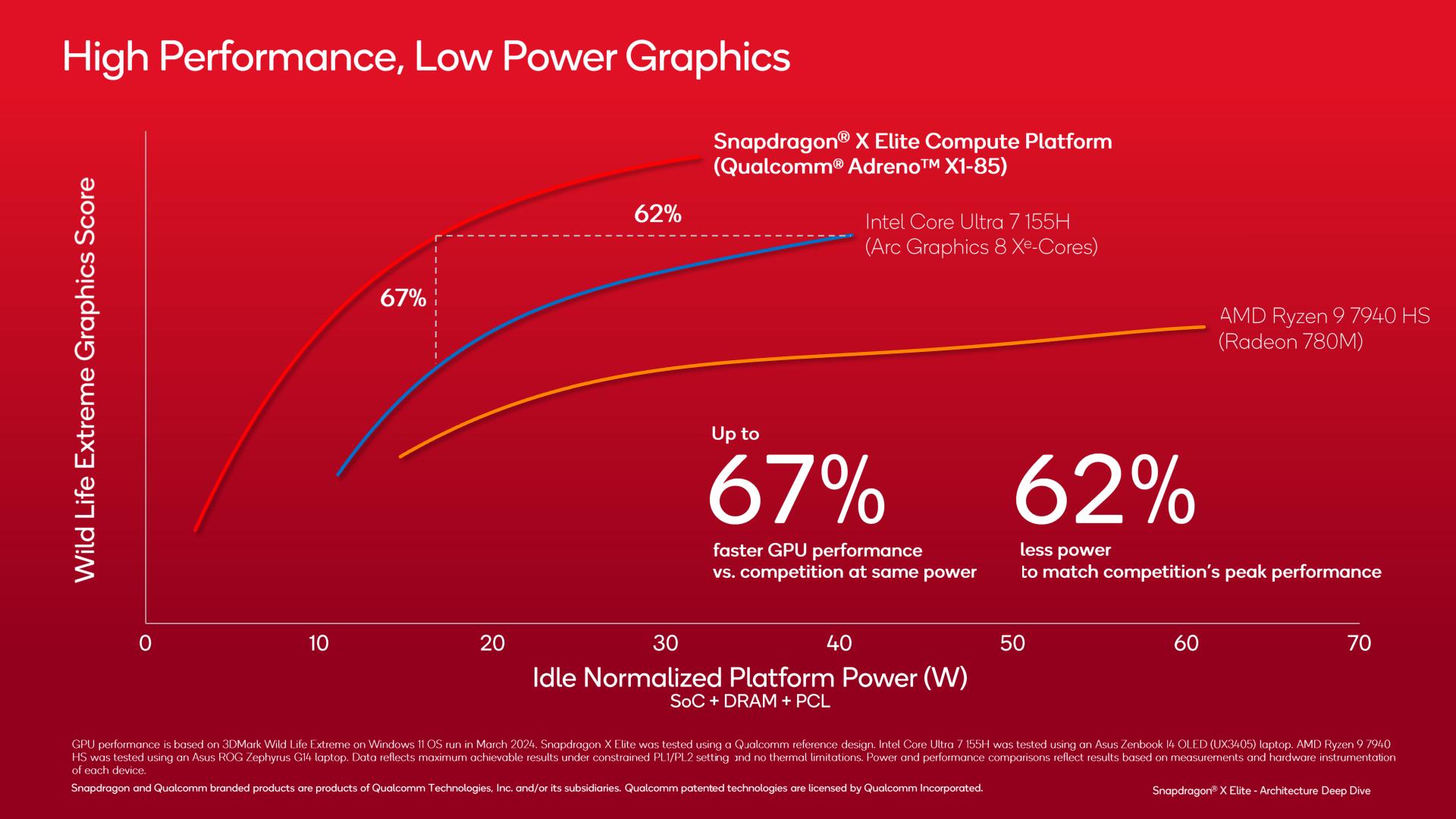
Meanwhile on the GPU front, Qualcomm is making similar energy efficiency gains. Though the workload in question – 3DMark WildLife Extreme – is not likely to translate into most games, as this is a mobile-focused benchmark that has long been optimized to heck and back within every mobile SoC vendor’s drivers.
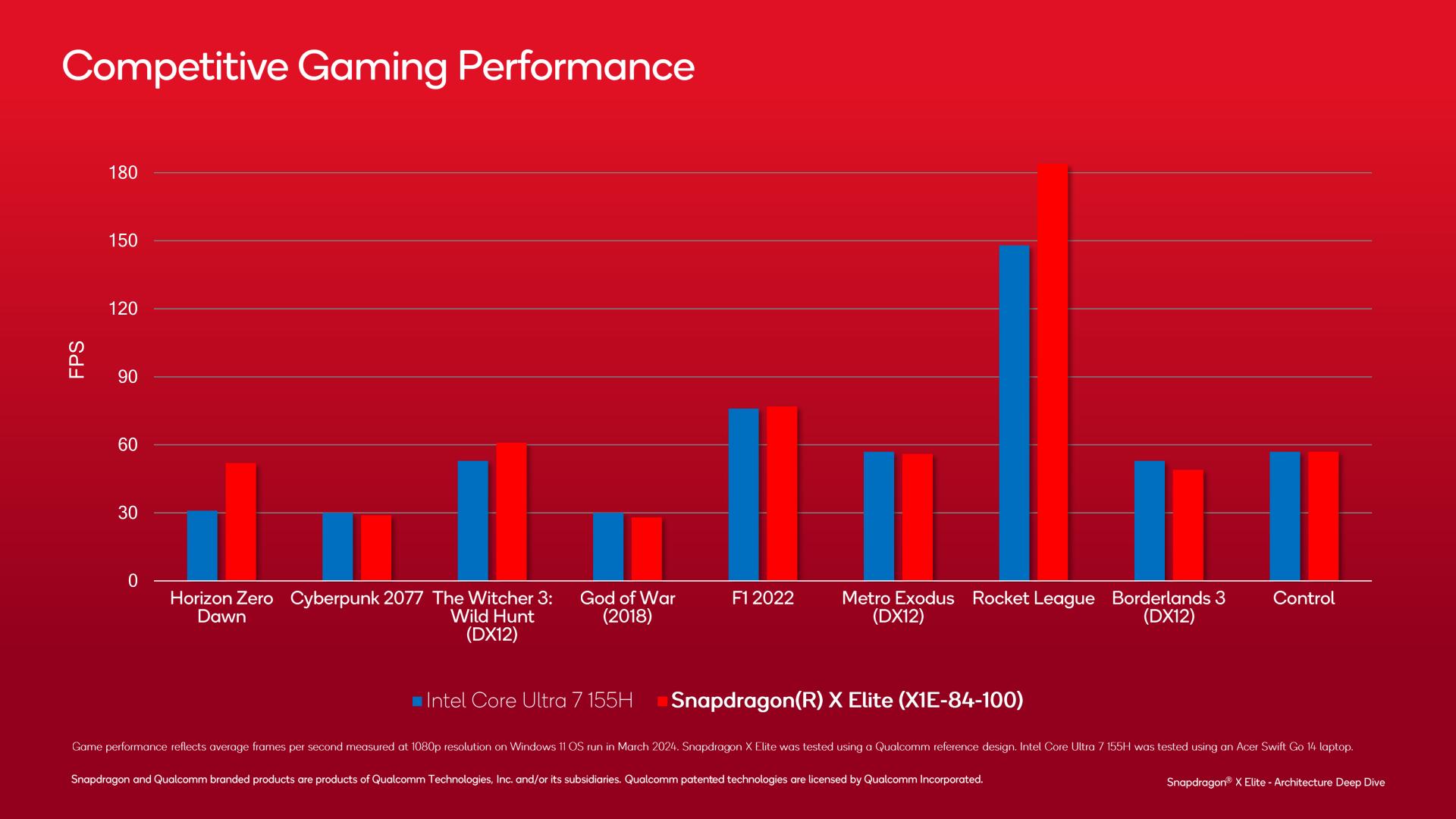
Performance benchmarks using actual games are arguably more useful here. And even though Qualcomm is probably doing some cherry-picking, the top Snapdragon X SKU is often trading blows with Intel’s Core Ultra 7 155H. It admittedly makes for a less impressive showing overall, but it’s good to see where Qualcomm is currently landing on real games. And in this case, even just a mix of ties/beats of one of Intel’s better mobile chips is not a bad showing.
First Thoughts
And there you have it, our first deep dive into a Qualcomm Snapdragon X SoC architecture. With Qualcomm investing into the Windows-on-Arm ecosystem for the long haul, this will hopefully be the first of many, as the company seeks to become the third major Windows CPU/SoC vendor.
But the ultimate significance of the Snapdragon X SoC and its Oryon CPU cores goes beyond just mere SoCs for PC laptops. Even if Qualcomm is wildly successful here, the number of PC chips they’ll ship will be a drop in the bucket compared to their true power base: the Android SoC space. And this is where Oryon is going to be lighting the way to some significant changes for Qualcomm’s mobile SoCs.

As noted by Qualcomm since the start of their Oryon journey, this is ultimately the CPU core that will be at the heart of all of Qualcomm’s products. What starts this month with PC SoCs will eventually grow to include mobile SoCs like the Snapdragon 8 series, and farther along still will be Qualcomm’s automotive products, and high-end offshoots like their XR headset SoCs. And while I doubt we’ll really see Oryon and its successors in Qualcomm’s product in a true top-to-bottom fashion (the company needs small and cheap CPU cores for their budget lines like Snapdragon 6 and Snapdragon 4), there is no doubt that it’s going to become a cornerstone of most of their products over the long run. That’s the value of differentiation of making your own CPU core – and getting the most value out of that CPU core by using it in as many places as possible.
Ultimately, Qualcomm has spent the last 8 months hyping up their next-generation PC SoC and its bespoke CPU core, and now it’s time for all of the pieces to fall into place. The prospect of having a third competitor in the PC CPU space – and an Arm-baesd one at that – is exciting, but slideware and advertising aren’t hardware and benchmarks. So we’re eagerly awaiting what next week will bring, and seeing if Qualcomm’s engineering prowess can live up to the company’s grand ambitions.














52 Comments
View All Comments
id4andrei - Thursday, June 13, 2024 - link
If Qualcomm can support OpenCL and Vulkan there is no excuse for Apple not to. ReplyDolda2000 - Thursday, June 13, 2024 - link
I think we already knew there's no excuse for Apple not to support OpenCL and Vulkan. It's funny how Apple turned from being a supporter and inventor of open standards in the 2000s to "METAL ONLY" as soon as the iPhone became big. ReplyFWhitTrampoline - Thursday, June 13, 2024 - link
Imagine this, Just as Linux/MESA Gets a Proper and up to date to OpenCL(Rusticl: Implemented in the Rust Programming language) implementation to replace that way out of date and ignored for years MESA Clover OpenCL implementation, the Blender Foundation not a year or so before that goes on and Drops OpenCL as the GPU compute API in favor of CUDA/PTX and so there goes Radeon GPU compute API support over to ROCm/HIP that's needed to take that CUDA(PTX Intermediate Language representation) and convert/translate that to a form that can be executed on Radeon GPUs. And ROCm/HIP is never really been for consumer dGPUs or iGPUs and Polaris graphics was dropped from the ROCm/HIP support matrix years ago and Vega graphics is ready to be dropped as well! And so that's really fragmented the GPU compute API landscape there as Blender 3D 3.0/later editions only have native back end support for Nvidia CUDA/PTX and Apple Metal. So AMD has ROCm/HIP and Intel Has OneAPI that has similar functionality to AMD's ROCm/HIP. But Intel's got their OneAPI working good with Blender 3D for ARC dGPUs and ARC/Xe iGPUs on Linux as well while on Linux AMD's ROCm/HIP is not an easy thing for the non Linux neck-beard to get installed and working properly and only on a limited set of Linux Workstation Distros, unlike Intel's OneAPI and Level-0.But I'm on Zen+ and Vega 8/iGPU with a Polaris dGPU on one laptop and on Zen+ and Vega 11/iGPU on my ASRock X300 Desk Mini! And so my only hope at Blender 3D dGPU and iGPU accelerated cycles rendering is using Blender 2.93 and earlier editions that are legacy but still use OpenCL as the GPU compute API! But I'm still waiting for the Ubuntu folks to enable MESA/Rusticl instead of having that hidden behind some environment variable because that still unstable, and I'm downstream of Ubuntu on Linux Mint 21.3.
So I'm waiting for Mint 22 to get released to see if I will ever be able to get any Blender 3D iGPU or dGPU Accelerated Cycles rendering enabled because I do not want to use the fallback default and Blender's CPU accelerated Cycles rendering as that's just to slow and too stressful on the laptop and the Desk Mini(I'm using the ASRock provided cooler for that). Reply
name99 - Saturday, June 15, 2024 - link
"It's funny how Apple turned from being a supporter and inventor of open standards"You mean how Apple saw the small minds at other companies refuse to advance OpenCL and turn OpenGL into a godawful mess and concluded that trying to do things by committee was a complete waste of time?
And your solution for this is what? Every person who actually understands the issues is well aware of what a clusterfsck Vulkan is, eg https://xol.io/blah/death-to-shading-languages/
There's a reason the two GPU APIs/shading languages that don't suck (Metal and CUDA) both come from a single company, not a committee. Reply
Dante Verizon - Sunday, June 16, 2024 - link
The reason is that there are few great programmers. Replydan82 - Thursday, June 13, 2024 - link
Thanks for the write-up. I'm very much looking forward to the extra competition.I assume AVX2 emulation would be too slow with Neon. While it's possible to make it work, it would perform worse than SSE, which isn't what any application would expect. And the number of programs that outright require AVX2 are probably very few. I'm assuming Microsoft is waiting for SVE to appear on these chips before implementing AVX2 emulation. Reply
drajitshnew - Thursday, June 13, 2024 - link
Thanku Ryan and AT for a good CPU architecture update. It is a rare treat these days ReplyHulk - Thursday, June 13, 2024 - link
I think this might have been important if Lunar Lake wasn't around the corner. But after examining Lunar Lake I think this chip is overmatched. Good try though. ReplySIDtech - Friday, June 14, 2024 - link
😂😂😂😂 ReplyFWhitTrampoline - Thursday, June 13, 2024 - link
"Meanwhile the back-end is made from 6 render output units (ROPs), which can process 8 pixels per cycle each, for a total of 48 pixels/clock rendered. The render back-ends are plugged in to a local cache, as well as an important scratchpad memory that Qualcomm calls GMEM (more on this in a bit)."No that's 6 Render Back Ends of 8 ROPs each for a total of 48 ROPs and 16 more ROPs than either the Radeon 680M/780M(32 ROPs) or the Meteor Lake Xe-LPG iGPU that is 32 ROPs max. And so the G-Pixel Fill Rates there are on one slide and that is stated as 72 G-Pixels/S and really I'm impressed there with that raster performance!
Do you have the entire Slide Deck for this release as the slide I'm referencing with the Pixel fill rates as in another article or another website ? Reply