The Qualcomm Snapdragon X Architecture Deep Dive: Getting To Know Oryon and Adreno X1
by Ryan Smith on June 13, 2024 9:00 AM ESTPerformance Promises and First Thoughts
Wrapping things up, let’s touch upon a couple of Qualcomm’s performance slides before closing out this architectural deep dive. While the whole world will get to see what the Snapdragon X can do first-hand next week when retail devices launch, until then it gives us a bit more insight into what to expect. Just be sure to take it with the requisite grain of salt.
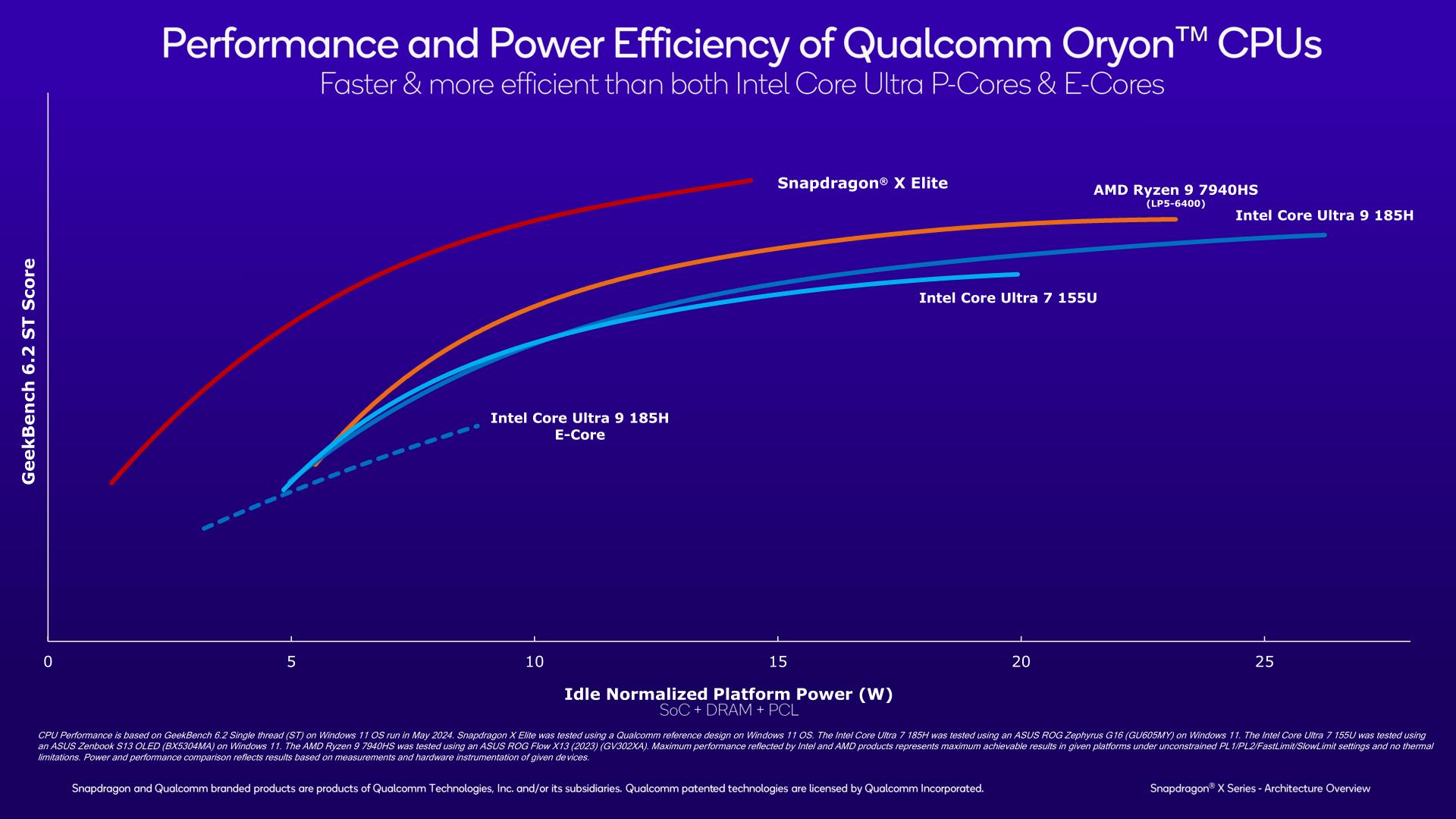
On the CPU side of matters, Qualcomm is claiming that the Snapdragon X Elite can beat the entire field of contemporary PC competitors in GeekBench 6.2 single-threading. And by a significant degree, too, when power efficiency is taken into account.
In short, Qualcomm claims that the Oryon CPU core in the Snapdragon X Elite can beat both Redwood Cove (Meteor Lake) and Zen 4 (Phoenix) in absolute performance, even if the x86 cores are allowed unrestricted TDPs. With mobile x86 chips turboing as high as 5GHz it’s a bold claim, but not out of the realm of possibility.
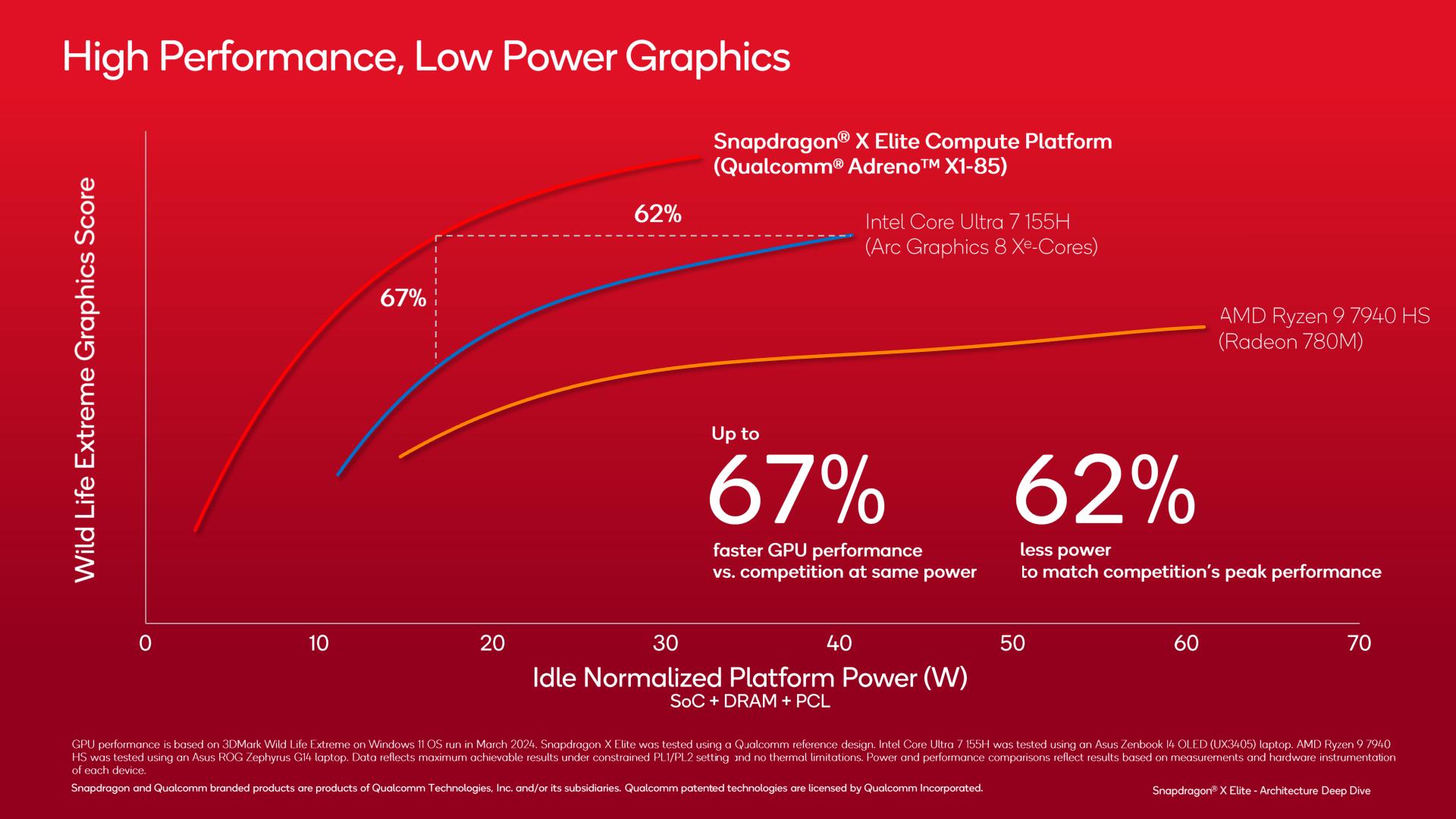
Meanwhile on the GPU front, Qualcomm is making similar energy efficiency gains. Though the workload in question – 3DMark WildLife Extreme – is not likely to translate into most games, as this is a mobile-focused benchmark that has long been optimized to heck and back within every mobile SoC vendor’s drivers.
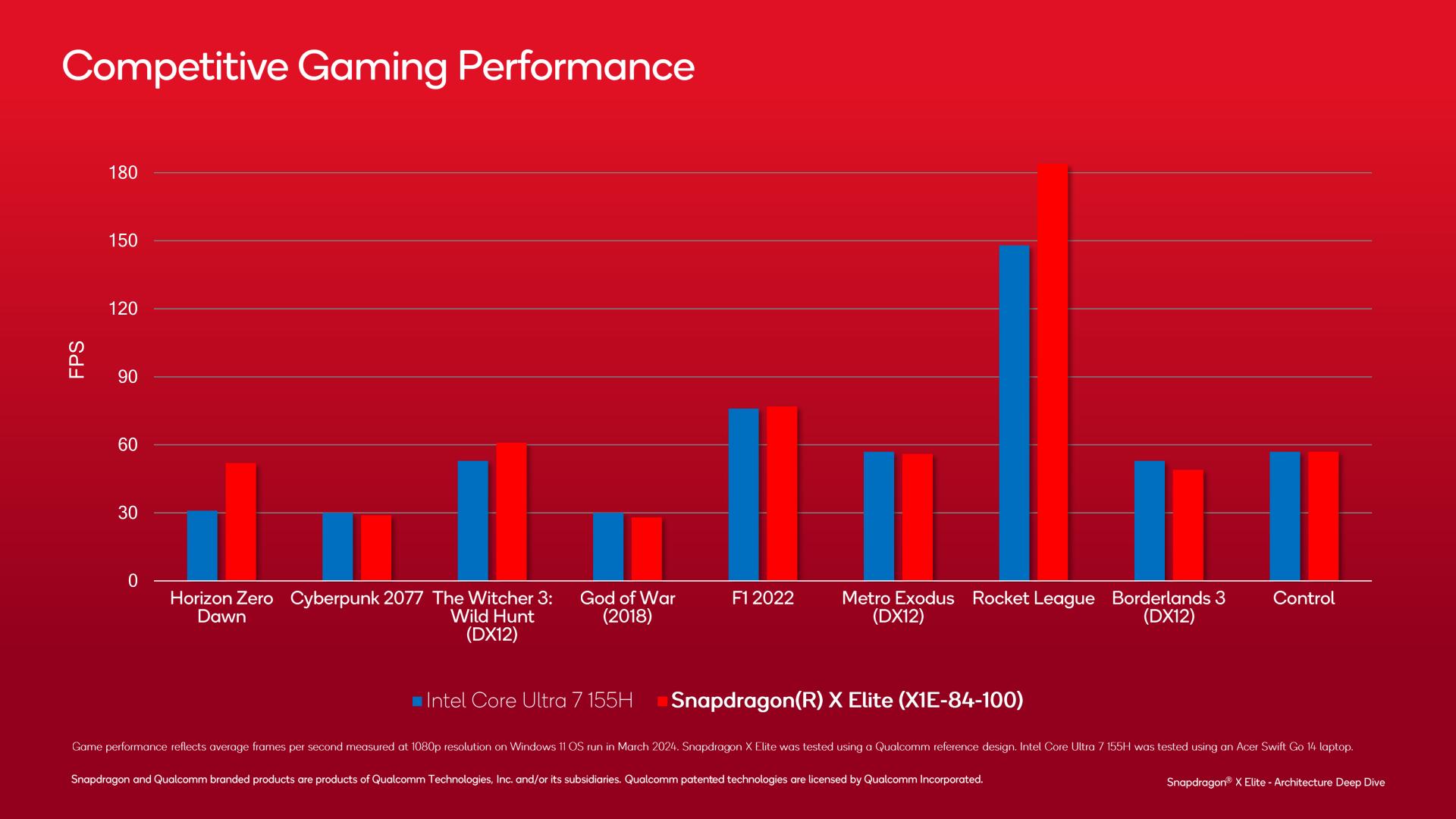
Performance benchmarks using actual games are arguably more useful here. And even though Qualcomm is probably doing some cherry-picking, the top Snapdragon X SKU is often trading blows with Intel’s Core Ultra 7 155H. It admittedly makes for a less impressive showing overall, but it’s good to see where Qualcomm is currently landing on real games. And in this case, even just a mix of ties/beats of one of Intel’s better mobile chips is not a bad showing.
First Thoughts
And there you have it, our first deep dive into a Qualcomm Snapdragon X SoC architecture. With Qualcomm investing into the Windows-on-Arm ecosystem for the long haul, this will hopefully be the first of many, as the company seeks to become the third major Windows CPU/SoC vendor.
But the ultimate significance of the Snapdragon X SoC and its Oryon CPU cores goes beyond just mere SoCs for PC laptops. Even if Qualcomm is wildly successful here, the number of PC chips they’ll ship will be a drop in the bucket compared to their true power base: the Android SoC space. And this is where Oryon is going to be lighting the way to some significant changes for Qualcomm’s mobile SoCs.

As noted by Qualcomm since the start of their Oryon journey, this is ultimately the CPU core that will be at the heart of all of Qualcomm’s products. What starts this month with PC SoCs will eventually grow to include mobile SoCs like the Snapdragon 8 series, and farther along still will be Qualcomm’s automotive products, and high-end offshoots like their XR headset SoCs. And while I doubt we’ll really see Oryon and its successors in Qualcomm’s product in a true top-to-bottom fashion (the company needs small and cheap CPU cores for their budget lines like Snapdragon 6 and Snapdragon 4), there is no doubt that it’s going to become a cornerstone of most of their products over the long run. That’s the value of differentiation of making your own CPU core – and getting the most value out of that CPU core by using it in as many places as possible.
Ultimately, Qualcomm has spent the last 8 months hyping up their next-generation PC SoC and its bespoke CPU core, and now it’s time for all of the pieces to fall into place. The prospect of having a third competitor in the PC CPU space – and an Arm-baesd one at that – is exciting, but slideware and advertising aren’t hardware and benchmarks. So we’re eagerly awaiting what next week will bring, and seeing if Qualcomm’s engineering prowess can live up to the company’s grand ambitions.














52 Comments
View All Comments
Ryan Smith - Thursday, June 13, 2024 - link
So the industry as a whole has always played a little fast and loose with how the term ROPs is thrown around. In all modern architectures, what you have is not X number of single units, but rather a smaller number of units that can render multiple pixels per cycle. In this case, 6 units, each of which can spit out 8 pixels.For historical reasons, we often just say ROPs = pixel count, and move on from there. It doesn't really harm anyone, even if's' not quite correct.
But since this is our first deep dive into the Adreno GPU architecture, I wanted to get this a bit more technically correct. Hence the wording I used in the article.
"Do you have the entire Slide Deck for this release as the slide I'm referencing with the Pixel fill rates as in another article or another website ? "
Yes, the complete slide deck is posted here: https://www.anandtech.com/Gallery/Album/9488 Reply
FWhitTrampoline - Thursday, June 13, 2024 - link
For the Sake of TechPowerUp's GPU Database That lists the dGPU/iGPUs render configurations as Shader:TMUs:ROPs and (Tensor Cores/Matrix Math Units and RT Units as well) But Please Technology Press adopt some common nomenclature so the Hardware can be as properly quantified as possible. So yes there's different was of stating that but what about the online GPU and CPU information databases and so some standardized taxonomy for CPU and GPU, other processor hardware is needed!And I did Find that slide in your link but please Tech Press for CPU cores and iGPUs/dGPUs please get together on that or maybe see if the ACM has some glossary of terms for CPU Core parts and GPUs as well. As without any standardized nomenclature processors(CPUs, GPUs, NPUs/other) from different makers can not be compared and contrasted to at least some basic level.
I was very Impressed that you referenced and article that's using Imagination Technologies Ray Tracing Hardware Levels classification system as that's a great scholarly way to standardize the classification of the various Hardware Ray Tracing implementations that have appeared since 2014 when the PowerVR Wizard GPU IP appeared with the first hardware based Ray Tracing implementation! Reply
Jonny_H - Thursday, June 13, 2024 - link
The problem with demanding a single consistent comparison number is that hardware isn't consistently comparable between different architectures.Even the RT "levels" you quoted has issues - like AMD GPUs *do* have some hardware acceleration to the BVH processing - just a single node in the tree rather than a hardware tree walker. So it's more than a level 2, but less than a level 3. And there's also the issue that implies they're a linear progression - that level 4 follows level 3, but there's nothing specific about ray coherency sorting that *requires* a hardware BVH tree walker.
Categorizing hardware is complex because hardware implementation details are complex. At some point every abstraction breaks down. Reply
FWhitTrampoline - Thursday, June 13, 2024 - link
Yes things are not directly comparable but TPU's GPU Database does list ROP counts and those "ROPs" usually process 1 Pixel per clock per "ROP" and so the G-Pixel fill rates can be estimated for that and used as a metric to compare different makers GPU hardware for pixel processing numbers(Theoretical Max Numbers).And the RDNA2 GPU micro-architecture received no proper GPU Whitepaper at release and so folks interested in that Ray Tracing on RDNA2 only got some minimal slides sans any in-depth Whitepaper explanation of that, other than a link to the RDNA1 whitepaper that lacked any hardware Ray Tracing at all! And as far as I can tell there was never any formal RDNA2 whitepaper released!
But I do value your Input with regards to the Levels Number for RDNA2's Ray Tracing and is there any reading material out there that you know of that's not behind some NDA that goes into some whitepaper like deep dive into RDNA2's actual RT Pipeline and maybe with some flow charts as well.
The hardest thing for me is Pay-walled Publications and the difficulties around getting access to College Libraries in the large Urban areas of the NE US where that's closed down to students only and no way to get access to that. And so The Microprocessor Report and all the other Trade Journals that I used to have access to when I was in College are not accessible to me now! Reply
GeoffreyA - Friday, June 14, 2024 - link
What about your city's municipal reference library, rather than the lending and university ones? Often, one can get access to different journals there. ReplyFWhitTrampoline - Friday, June 14, 2024 - link
My Public Library is not subscribed to the usual academic Trade and Computing Sciences Journals and lacks the funding. But even with some College Libraries Being federal depository libraries they are not as open to non students as the CFR/USC requires. And so that makes things harder in the NE US. Now if I lived om the West Coast of the US and in some large Urban Area things are different there and even in the Southern US Cities surprisingly. ReplyGeoffreyA - Friday, June 14, 2024 - link
I understand. It's a sad state of affairs for information to be unaccessible. Replymode_13h - Saturday, June 15, 2024 - link
> is there any reading material out there ... that goes into some whitepaper like deep dive> into RDNA2's actual RT Pipeline and maybe with some flow charts as well.
Have you seen this?
https://chipsandcheese.com/2023/03/22/raytracing-o... Reply
name99 - Saturday, June 15, 2024 - link
https://sci-hub.se ReplySoulkeeper - Friday, June 14, 2024 - link
To the few comments complaining about "marketing slides" or no benchmarks ...I appreciate this article, it's a pre release technical overview of a new cpu design.
This kind of technical stuff is what made anandtech great.
We are smart enough to spot the marketing, consume the author's input, and judge for ourselves (and should be patient enough to wait for benchmarks).
Keep up the good work. Reply