Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
Integer Processing
To measure the integer processing potential of the various CPUs, we'll turn to several different workloads. First up, we have 7z LZMA compression and decompression, again looking at performance with one to four threads. On the next page, we'll look at gcc compiler performance.
Compression
Compression is a low IPC workload that's sensitive to memory parallelism and latency. The instruction mix is a bit different, but this kind of workload is still somewhat similar to many server workloads.
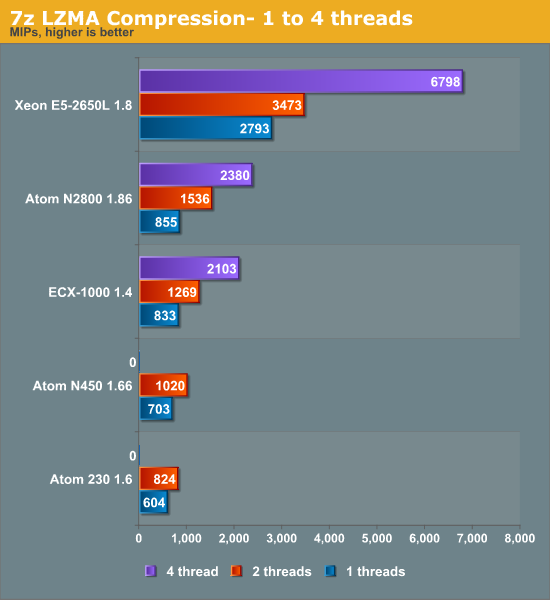
Clock for clock, the out-of-order Cortex-A9 inside the Calxeda EXC-1000 beats the in-order Atom core. A single Cortex-A9 has no trouble beating the older Atoms while likewise coming close to the much higher clocked N2800. The N2800 and ECX-1000 perform similarly.
Decompression
Decompression is pretty branch intensive and depends on the latencies of multiply and shift instructions.
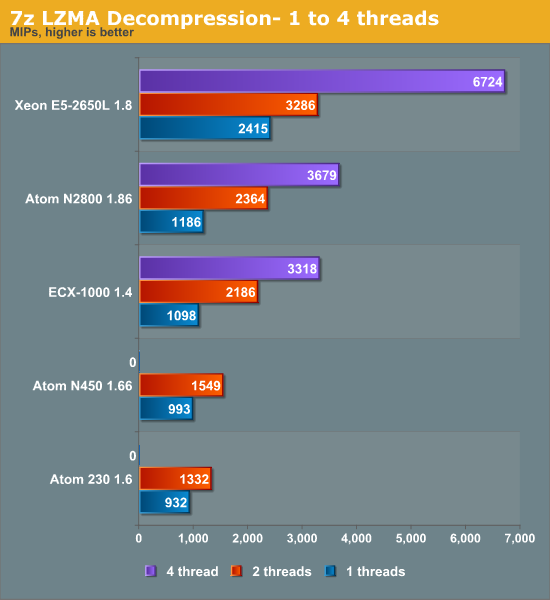
Branch mispredictions are common and the Atom tackles branch mispredictions well with its Simulteanous MultiThreaded (SMT) core. The boost from Hyper-Threading is very large here: a second ARM Cortex-A9 core gives a 52% boost and Hyper-Threading gives a 56% boost. This is very much the exception as far as Hyper-Threading performance is concerned.
Looking at both decompression and compression, it looks like a quad ARM Cortex-A9 is about as fast as one Xeon core (without Hyper-Threading) at the same clock. We need about six Cortex-A9 cores to match the Xeon core with Hyper-Threading enabled. The quad-core ECX-1000 1.4GHz is also close to the dual-core, four-threaded Atom at 1.86GHz. This bodes well for Calxeda as the 6.1W S1240 only runs at 1.6GHz.








99 Comments
View All Comments
Gigaplex - Tuesday, March 12, 2013 - link
I wouldn't call that a spectacular performance per watt ratio. It's a bit faster than the Xeon under a cherry picked benchmark (much slower under others), and is only marginally lower power. Best case it's an 80% improvement over Sandy Bridge with regards to performance per watt, and Atom wasn't represented. Considering all the hype, I was expecting something a little more... exciting. Ignoring Ivy Bridge improvements, Haswell isn't far off.spronkey - Tuesday, March 12, 2013 - link
Yeah... I agree. It also only seems to really come into its own in high concurrency. The Xeons idle quite similarly in terms of power - what happens if you compare it to more Xeon cores? It seems like on a per core basis, Intel still has the advantage on both fronts?spronkey - Tuesday, March 12, 2013 - link
I would also point out that the A15 has already been compared against Sandy and Ivy cores and come up short in performance per watt; so I'm very interested to see what the next step for these ARM node servers is.JohanAnandtech - Wednesday, March 13, 2013 - link
I warned against the hype in the first sentences. :-) ARM CPUs are still rather weak and not a good match for most applications. However, the fact that we could actually find a case where they do a lot better than the current Xeon systems was surprising to me.wsw1982 - Wednesday, April 3, 2013 - link
No, it should not surprise any people regarding how picky the use case is. I mean, I do think you can find a use case the ARM 11 output perform Xeon. E.g. Serving 1 web request per hour :)LogOver - Tuesday, March 12, 2013 - link
24 servers ran inside 24 VM's on Xeon server, while for ARM server you used the 24 physical server nodes... Hmm... Does not seems to me like apple to apple comparison. Why not to compare, for example, 16 physical nodes on both, xeon and arm servers?haplo602 - Wednesday, March 13, 2013 - link
And how do you slice the Xeon server into 16 physical nodes ? It does not support any kind of HW partitioning that I am aware of. On the other hand the Calxeda machine is a cluster by design. If you try 16 Xeon nodes you'll go through the roof with power.Colin1497 - Wednesday, March 13, 2013 - link
I think the question is this:Was 24 VM's optimal for the Xeon? Since we're visualizing the Xeon, why 24? Just because you had 24 ARM nodes? Would the Xeon done better with 4VM's? Or 16? Or 1000? 24 seems arbitrary.
JohanAnandtech - Wednesday, March 13, 2013 - link
We tested with 16 as I briefly mentioned in the conclusion. The 2650L did 170 responses/s per VM, or about 40% better. Total Throughput = 2.7k/s, while with 24, 2.9 K/s. THe flexibility that the Xeon has to reduce the number of VMs if higher throughput is necessary is definitely an advantage, but the performance numbers are not that different with different VM configs.Kurge - Wednesday, March 13, 2013 - link
How about with 0 VM's? Just run it on the metal.