Original Link: https://www.anandtech.com/show/2310
A New SSE Instruction Set: AMD Announces SSE5
by Ryan Smith on August 30, 2007 4:00 PM EST- Posted in
- CPUs
A couple of weeks ago we had our first look at AMD's Lightweight Profiling Proposal with the promise of more to come as part of AMD's latest initiative in improving computer performance via additions to the x86 instruction set. Today AMD has lifted the veil off of the next part, and as we have been expecting, this part is a more traditional extension to the x86 instruction set with the addition of new high-performance instructions. This marks the first time AMD has made such a move since the last revision of the 3DNow instruction set several years ago.
To that extent, AMD has opted to cease development of 3DNow and instead focus on further augmenting Intel's SSE instruction set, which won the instruction set wars some time ago with AMD's adoption of it. The result, confusingly enough, is what AMD is calling SSE5, breaking the tradition of all of the iterations of SSE being an Intel product. This is part of a larger AMD effort to inject themselves in to the process of developing further iterations of SSE, as along with the SSE5 specification they are already telling us they're hard at work getting the discussion going in the computing industry about SSE6 and beyond. Intel's name is noticeably absent from any of today's materials, so we will no doubt be hearing their opinion soon on AMD's encroachment in to designing SSE specifications.
As for SSE5, today's announcement is in many ways a very standardized one for an industry that produces a new iteration of SSE approximately every 2 years. Citing the slow growth in clock speed and instruction per second rates in the past few years, AMD has been looking at other ways to improve the performance of their processors. One such way has been by adding more processor cores for extracting additional performance via thread-level parallelism, which has given birth to the modern core wars. Another such effect has been adding more execution units in a single processor core to extract more instruction-level parallelism within a thread, which we have seen occur with Intel's Conroe design, and which AMD will be doing themselves with the upcoming Barcelona core and its derivatives.

Finally however there is improving processor performance at an instruction level, either by making instructions execute/retire faster or designing new instructions, the latter of which is the traditional scope of SSE and is where AMD is focusing SSE5 today. As with the past iterations of SSE, AMD is calling for new instructions that will improve the performance of computing-intensive tasks. For SSE5 AMD is focusing on improving performance in 3 specific areas: Security applications, traditional computing-intensive applications, and the now obligatory multimedia applications category. As far as the instructions go, few are actually field limited, but these are the areas that AMD believes will improve the most from the instructions they've selected.
With that said, it's important to note that while AMD is announcing SSE5 on the eve of the Barcelona launch, SSE5 is not going to be shipping with Barcelona or any of its derivatives or immediate successors. AMD will start including SSE5 support in the Bulldozer core, which with an expected launch date of 2009 is still two years off. Today's announcement and publication of their specifications is being done a bit more ahead of time than what we've seen in the past with other variations of SSE so that developers have ample time to learn about it and implement it in time for Bulldozer's launch. Ideally AMD hopes to bypass some of the chicken/egg problems that have occurred with past iterations of SSE.
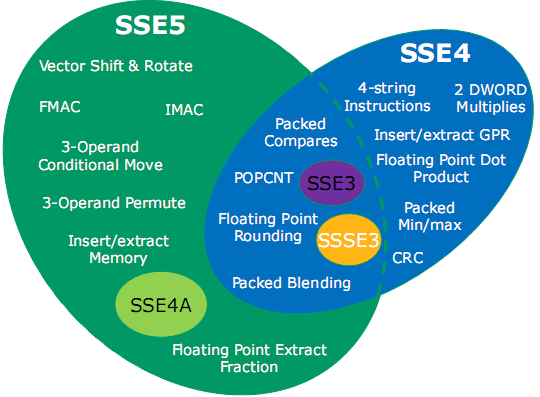
Unfortunately, with AMD's own SSE5 support we feel they have made a major snafu here in not supporting other versions of SSE. Previously, SSE has been entirely backwards compatible; if a processor supported SSE3 for example, you could count on it supporting SSE2, SSE1, and MMX. Intel's own new SSE extension, SSE4, is launching with Penryn later this year, but AMD will only be supporting a fraction of the SSE4 instruction set in Bulldozer, as seen in the graph below.
We're extremely disappointed in AMD going this route. Some of SSE4's instructions are quite potent, others we have been told are not; AMD believes that the subset of SSE4 they are including are the most useful of these. But we believe it's still worth including such instructions, and by using the name SSE5 and adding it to Bulldozer they have made a very strong implication about backwards compatibility that isn't all there. While this is a valid addition to the SSE instruction set, AMD should have named it something other than SSE5 to avoid confusion.
Finally, we've been told that full SSE4 support is coming for AMD's chips, but without a date. We know that it won't be in Bulldozer, which means SSE4 support won't be happening until a Bulldozer refresh, which will be no earlier than 2010.
The SSE5 Instruction Set
While extending the x86 instruction set with new iterations of SSE has become a regular activity in the computing industry, many of these additions are in actuality a gradual reshaping of x86 processors. Although as a general purpose CPU design x86 doesn't have any hard limitations (given enough time you can do any kind of calculation required) it has had several weak points patched up over the years. The basis of identifying and patching these weak points has been looking at what processors - general and specialized - are doing well while x86 is doing poorly at the time. Each iteration of SSE so far has then implemented features that these other processors have to erase these weak points.
All told, SSE5 includes 46 unique "base" instructions, with many of those instructions featuring several variations that work on different data types. With all of these variations, the total number of instructions introduced altogether with SSE5 is 170. For comparison's sake, the entire original x86 instruction set was a mere 80 instructions.
With SSE5, AMD is focusing on 5 groups of instructions. Those groups are:
- Fused multiply accumulate (FMACxx) instructions
- Integer multiply accumulate (IMAC, IMADC) instructions
- Permutation and conditional move instructions
- Vector compare and test instructions
- Precision control, rounding, and conversion instructions
As we hinted to earlier, many of these instructions are implementations of features found elsewhere. DSPs in particular have been and continue to be a major source of new instructions for new versions of SSE, with many of these instructions allowing for a CPU to process data for specialized cases at DSP-like speeds.
Additionally, AMD has taken a particular interest in the weakness of the very core of x86, which is how the instructions are formed and handled. A single binary-form instruction for an x86 processor (or most other processors for that matter) is a combination of two parts: an opcode and operands. The opcode is the segment of the instruction that says what to do, the operands are the data elements that will be operated upon and any further specifiers the processor needs to execute the instruction. As far as the x86 instruction set is concerned, this is normally very cut & dry: 2 bytes for the opcode, and then the rest of the instruction is the operands, with the vast majority of instructions using between 0 and 2 data element operands.

AMD is making changes to both the opcode and operand design as part of SSE5, with the latter in particular intended to make many of the new performance-improving instructions possible. For the opcode, AMD is adding a third byte to the opcode - this is necessary to provide the bits needed to identify the new instructions, and provide some controls over the use of the new operand features. As for the operand, SSE5 includes numerous instructions that require the use of more than 2 data element operands; the format of the operands is not so much the point here as is the potential power of having additional operands. One way to improve performance is to operate on more pieces of data in a given instruction, and this requires the ability to address more than 2 data elements.

It's a MADD, MADD World
So what's so important about being able to use 3+ operands? In a word: MADD, Multiply-ADDition operations (aka multiply-accumulate/MAC), such as C=(A*B)+C. Matrix math is the cornerstone of data processing and image rendering, and one of the cornerstone operations in manipulating a matrix is multiplying two elements and adding them to a third, which would require 3 operands. Modern GPUs are MADD powerhouses, with their stream processors capable of processing a mind-boggling number of such instructions in a short period of time; being fast at MADD is one of the specialized tasks that makes a GPU so fast at its job.
Meanwhile x86 processors have no real MADD abilities, so any time a CPU is doing the kind of image manipulation work that would benefit from MADD, instead it is executing separate multiply and addition instructions (and sometimes more). It should come as no surprise that AMD's favorite/most-publicized part of SSE5 then are instructions using 3+ operands since fusing two instructions in to one can theoretically double performance in certain situations. Furthermore using such instructions can cut down on the number of register load/store operations needed, which can save yet more time.
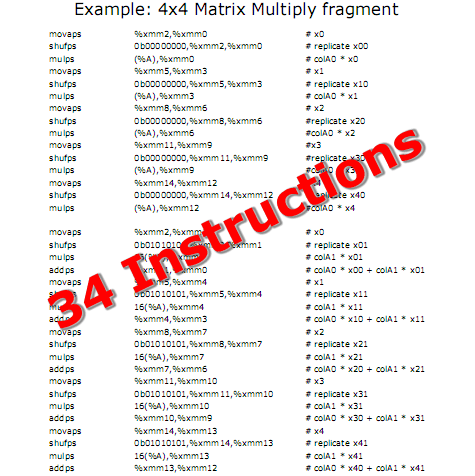
AMD has provided us with an example of such a situation, with the code for a 4x4 matrix multiplication operation, one coded optimally in SSE3, the other optimized via SSE5. The SSE3 code requires 34 instructions, meanwhile the SSE5 code does it in 20. Now there is more to the performance of such a code segment than the number of instructions (so this example isn't necessarily 41% faster) since the time to execute and retire an instruction can vary depending on the instruction, but it doesn't negate the performance improvement offered by such code.

For actual performance numbers with SSE5, AMD has told us that they've found that a discrete cosine transform - an operation important for image and movie encoding - can be done 30% faster using SSE5 than SSE3. They have even more impressive numbers for encryption processing, with a 5x performance improvement possible on certain encryption tasks, although we suspect this case is more limited than their image encoding scenario. Either way the promise of other performance improvements is there, however this is going to heavily depend on how well programmers will be able to extract additional performance out of SSE5, and how good AMD's own optimized math libraries will be once those are released.
This also isn't taking in to significant account instructions that are not part of the MADD/MAC set. All of AMD's examples today deal with improvements due to those instructions, meanwhile we don't have a lot of information on the performance aspects of the permutation, vector, or precision instructions. We have no doubt that they'll be similarly useful, we just don't know to what degree at this point.
Finally, as we're always watching how the predicted merging of CPUs and GPUs is progressing, this is a notable time. Although AMD is not targeting GPUs specifically with SSE5, as we mentioned before GPUs are particularly fast at MADD operations and meanwhile SSE5 is providing CPUs a shot in the arm in that area. This won't kill (or even significantly maim) the GPU, but it is one less thing that the GPU advantage is shrinking in. As SSE iterations keep coming out and implementing features similar to DSPs and GPUs, they will keep chipping away at their side of the barrier between the CPU and the GPU until very little is left and the two become one.
First Thoughts
Unlike AMD's Lightweight Profiling Proposal, today we're not looking at an idea for a possible future, but instead a specification for something that will happen. While AMD is still soliciting feedback for their earlier proposal, as of today they are moving at full speed ahead with SSE5. A SSE5 software simulator should be released today that will allow developers to experiment with SSE5 optimized code and see how well it will perform, well over a year ahead of when they will be able to see real engineering sample processors to test their code on. 2008 and beyond will see SSE5 support coming to the GCC compiler, along with AMD's optimized software libraries. AMD is going through great efforts to spur the adoption of SSE5.
It bears mentioning that there exists some potential issues between now and then however. First and foremost is the 800lb gorilla: Intel. Under normal conditions Intel's support is critical for new extensions to take off, the only exception to that has been AMD64/x86-64, which came at a time when that specification was far better suited for the computing industry than Intel's own IA64 specification. Simply put, we believe AMD will be unsuccessful with SSE5 if Intel is unwilling to add it to their own processors; the performance improvements are important, but it's not an AMD64 situation where AMD has the influence and technical advantages to get what it wants. Without Intel's support developers will code for the least-common-denominator among the extensions, or worse will focus on any Intel-only extensions should the two CPU families further diverge, something that is more likely to result now due to AMD's failure to include full SSE4 support on Bulldozer.
There's also the issue of the all-important compiler. Although AMD will have SSE5 support in GCC, and likely in the Visual Studio Compiler too, Intel failing to support SSE5 at the hardware level will mean that they will also not include it with their compiler. Intel's compilers are near-legendary in their ability to optimize code in the right situations (and in snubbing AMD chips at times), with developers working on computationally intensive applications likely unwilling to move away from using Intel's compiler.
Finally there's AMDs own hardware issues. It's impossible to predict what their situation will be like in 2 years, but we are always more concerned about them than Intel due to AMD's operating position. SSE5 is reliant on Bulldozer, AMD will need to get Bulldozer out on time if they want SSE5 to launch without a hitch. A late CPU can lead to SSE5 missing a chance to get in to new software development cycles.
But with those warnings out of the way, don't take this as a disapproval of SSE5. We believe that this will be the most important extension to the x86 instruction set since SSE2, and the new instructions like MADD in particular can offer the kind of performance improvements AMD wants to hit while avoiding the need to increase clock speeds significantly and the problems that result from such. What such a performance increase will be on actual applications however is something we're going to have to wait on the delivery of Bulldozer silicon to find out.
Finally, this isn't the last announcement from AMD we will see on the subject of AMD's instruction set performance initiative. We're still waiting on the rest of the proposals for the Hardware Extensions for Software Parallelism to be released, at which point we'll have a better idea of how AMD is going to tackle thread-level parallelism in the next few years. AMD hasn't put a date on that, but we'd expect something before the end of the year.






