Original Link: https://www.anandtech.com/show/2786
Application Workloads and Performance
It's no secret, we love performance tuning at AnandTech IT. It is simply in our blood to want to get the very best out of each platform available to us, and especially on as sticky a subject as virtualization. During the past year of intensive virtualization research at our lab, and the building up of our own "real world" benchmark suite, we have encountered countless applications that take quite a bit of work to get performing as expected with virtualization.
We know that in the past, virtualization vendors' claims of virtualization providing virtually no overhead "out of the box" tended to be rather blatantly false. Their claims considered only CPU-intensive applications, requiring little of any other resource, ruling out I/O-intensive platforms like databases as ripe for virtualization. At this year's VMworld, VMware sought to see this perception changed, by organizing several sessions that focused solely on the performance of exactly these kinds of applications.
This series of two articles will be a culmination of those sessions, mixed with our own experiences with performance optimization. The aim is to help our readers with a virtualized data center to avoid the common pitfalls and feel confident in their ability to get the most out of the technology.
Naturally, we don't like just handing out this information without any context to our readers. As IT researchers ourselves, we are all too familiar with the "random web search approach", where you need to find a fix for something quick and end up trying out the first one the search results offer - sometimes with disastrous results. For that reason, we want to bring you answers and solutions, only with a dash of knowledge added in.
A Quick Overview of ESX
To start, we need to brush up on what a hypervisor actually looks like, and clarify its different components. The term "hypervisor" is at this point nicely marketed to encompass basically everything that allows us to run multiple virtual machines on a single physical platform. Of course, that's pretty vague on what exactly a hypervisor denotes. Johan wrote an excellent article about the inner workings of the hypervisor last year, but we'll quickly go over the basics to keep things clear.
Kernels and Monitors
In VMware's ESX, the hypervisor is made up of two completely separate technologies that are both essential in keeping the platform running: the VMkernel and the Monitor. The Monitor provides the virtual interface to the virtual machines, displaying itself as a standard set of hardware components for the virtualized OS. This layer is responsible for the actual translation of the VM's calls for hardware (be it through the use of hardware virtualization, binary translation, or paravirtualization), and sends them through to the actual kernel, namely VMware's own kernel.
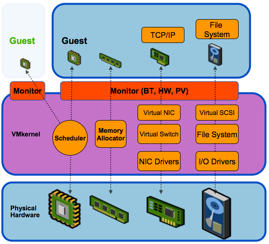
This monitor is the same across VMware's bare-metal (ESX) and hosted solutions (think VMware Workstation and Server). The difference in ESX is in its VMkernel, the kernel that acts as the miniature OS that supports all the others. This is the part that interacts with the actual hardware through various device drivers and takes care of things like memory management and resource scheduling.
This short explanation should make it a bit more clear what kind of workloads these two components need to handle. Limitations of the VMkernel are mostly rooted in its robustness and the amount of raw throughput it can handle efficiently through its scheduling mechanics: e.g. more or less the same limitations any OS would suffer in some way. On the other hand, limitations of the Monitor are mostly a matter of using the correct configuration for your workload, and depend largely on the features of the hardware you allow the Monitor to work with.
Limitations to Keep in Mind When Virtualizing
Keeping the Monitor and VMkernel's tasks in mind, which aspects of your application are the most easily affected by virtualization?
As it stands, VMware sees about an 80/19/1 division in application performance profiles. To put this more clearly, they estimate that 80% of all applications will notice very little to no performance impact from being virtualized, 19% will experience a noticeable performance hit, while 1% is deemed completely unfit for virtualization.
These numbers don't say a whole lot for your application, though, so here is a listing of parameters VMware looks for:
CPU usage. Just by looking at your task manager (or whichever monitoring tool you prefer), you can make a reasonable guess at what will happen when you virtualize. If you're seeing generally high CPU usage with very little kernel time, and you're generally not too worried about I/O, your application has a good chance of running fine in a virtual environment. Why is that?
User-mode CPU instructions can generally be run without any additional overhead. The Monitor is able to simply let these pass through to the CPU scheduler, because there's no danger in these instructions causing a mess for the other VMs. The dangerous instructions are the ones that require kernel mode to kick in, usually because the Operating System in question is not aware of its virtualized state, and could prevent the other VMs from functioning properly. Different solutions have been developed to work around this, but it's important to realize which type is used in which situation.
Luckily, for ESX 4 Scott Drummonds provided a nice overview of which combinations are used in every situation, allowing us to check and make sure our VMs are using the best our hardware has to offer.
| AMD Virtualization Tech Use Summary | |||
| Configuration | Barcelona, Phenom and Newer | AMD64 Pre-Barcelona | No AMD64 |
| Fault Tolerance Enabled | AMD-V + SPT | Won't run | Won't run |
| 64-bit guests | AMD-V + RVI | BT + SPT | Won't run |
| VMI Enabled | BT + SPT | BT + SPT | BT + SPT |
| OpenServer, UnixWare, OS/2 | AMD-V + RVI | BT + SPT | BT + SPT |
| 32-bit Linux and 32-bit FreeBSD | AMD-V + RVI | BT + SPT | BT + SPT |
| 32-bit Windows XP, Windows Vista, Windows Server 2003, Windows Server 2008 | AMD-V + RVI | BT + SPT | BT + SPT |
| Windows 2000, Windows NT, DOS, Windows 95, Windows 98, Netware, 32-bit Solaris | BT + SPT | BT + SPT | BT + SPT |
| 32-bit guests | AMD-V + RVI | BT + SPT | BT + SPT |
| Intel Virtualization Tech Use Summary | |||||||
| Configuration | Core i7 | 45nm Core 2 VT-x | 65nm Core 2 VT-x Flex Priority | 65nm Core 2 VT-x No Flex Priority | P4 VT-x | EM64T No VT-x |
No EM64T |
| Fault Tolerance Enabled | VT-x + SPT | VT-x + SPT | VT-x + SPT | VT-x + SPT | Won't run | Won't run | Won't run |
| 64-bit guests | VT-x + EPT | VT-x + SPT | VT-x + SPT | VT-x + SPT | VT-x + SPT | Won't run | Won't run |
| VMI Enabled | BT + SPT | BT + SPT | BT + SPT | BT + SPT | BT + SPT | BT + SPT | BT + SPT |
| OpenServer, UnixWare, OS/2 | VT-x + EPT | VT-x + SPT | VT-x + SPT | VT-x + SPT | VT-x + SPT | BT + SPT | BT + SPT |
| 32-bit Linux and 32-bit FreeBSD | VT-x + EPT | VT-x + SPT | BT + SPT (*) | BT + SPT (*) | BT + SPT (*) | BT + SPT | BT + SPT |
| 32-bit Windows XP, Windows Vista, Windows Server 2003, Windows Server 2008 | VT-x + EPT | VT-x + SPT | VT-x + SPT | BT + SPT (*) | BT + SPT (*) | BT + SPT | BT + SPT |
| Windows 2000, Windows NT, DOS, Windows 95, Windows 98, Netware, 32-bit Solaris | BT + SPT (*) | BT + SPT (*) | BT + SPT (*) | BT + SPT (*) | BT + SPT (*) | BT + SPT | BT + SPT |
| 32-bit guests | VT-x + EPT | VT-x + SPT | VT-x + SPT | VT-x + SPT | VT-x + SPT | BT + SPT | BT + SPT |
(*) denotes the capability of dynamically switching to VT-x mode when the guest requires it.
For more information on Shadow Page Tables (SPT), Extended Page Tables (EPT), RVI (Rapid Virtualization Indexing), Intel Hardware Virtualization (Intel VT-x) and AMD Hardware Virtualization (AMD-V), refer to our previous articles on these subjects.
Network bandwidth: To VMware, bandwidth is the biggest reason why an application could prove troublesome when virtualized. The theoretical amount of throughput ESX can maintain is claimed to be about 16Gbps. Adding in a big dash of realism, VMware places applications with a requirement for over 1Gbps in the "troublesome" category: Virtualization is possible, but they don't rule out that there might be a performance hit. What we have noticed ourselves here is a great amount of CPU overhead on the side of the initiator when teaming up multiple NICs to increase bandwidth. Teaming up to three Gigabit switches together causes a CPU load of about 40% inside a Windows Server 2003 VM running on four vCPUs of a 2.93GHz Nehalem processor. This overhead is greatly reduced when updating to Windows 2008 (to about 15%), and is further reduced to less than 5% when using ESX's own iSCSI initiator. Much thanks to Tijl Deneut of the Sizing Servers Lab for this tip.
General I/O: This is the one thing VMware will admit to causing a few applications to be simply "unvirtualizable". ESX at this point can maintain roughly 100,000 IOPS (vSphere is rumored to push this up to 350,000) and a maximum of 600 disks, which is a relatively impressive number considering a hefty Exchange installation requires something to the tune of 5000 IOPS. Counting at roughly 0.3 IOPS per user, that would account for over 16000 users, though of course this number might vary depending on the setup and user profiles. However, there are applications that simply require more IOPS, and they'll experience quite a lot of trouble under ESX. Moreover, changes in the storage layout might turn up some unexpected results, but we'll have more on that in the second article for this series.
Memory requirements: Finally, for very large database systems, there might be an issue here. In ESX 3.5, it is only possible to allocate as much as 64GB of RAM to a single VM. While plenty for most deployments, this might make virtualization of large-scale database systems troublesome. Should this be the case, remember that ESX 4.0 ups this limit to 255GB per VM, allowing even the most memory-hungry databases an impressive amount of leeway.
Keeping these things in mind, however, there are some ways to get the most of your virtualized environment….
CPU Considerations
Although Binary Translation is a very mature and solid technology, no matter how well it performs there is a certain amount of overhead involved. Over the past few years, Hardware-Assist has slowly come around to take its place, while the evolution to 64-bit systems chugs along quietly. The choice therefore would seem rather clear-cut: using newer CPUs should get you better results. Improvements are constantly being made to AMD's and Intel's latest and greatest to better accommodate virtualized environments, fundamentally changing the way ESX operates the hardware. Keeping up with the performance jumps throughout these architectural restructurings can get rather complicated.
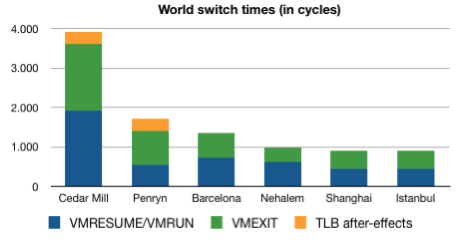
The above graph is a rough attempt at sketching the improvements on world switch times, one of the biggest factors in hardware virtualization performance. It is based on the duration of the VMRESUME (Intel VT-x)/VMRUN (AMD-SVM) and the VMEXIT execution times. A world switch happens when the CPU is for example forced to switch to hypervisor mode ("Ring -1", if you remember Johan's article) to prevent a VM from influencing other VMs. This requires running some instructions that vary according to the machine's hardware. The graph denotes how many cycles are essentially lost performing this operation. The added value of Hardware-Assisted Paging (RVI for AMD, EPT for Intel) is immediately visible here, as are the vast improvements to hardware virtualization performance throughout the years.
Even keeping these improvements in mind, does it make sense to jump on the latest generation CPUs whenever a new one emerges? In this case, it is simply easiest to let the numbers speak for themselves. Johan's recent articles pitting CPUs against each other in real world test scenarios might be of help here, but we want to stress the importance of using multiple data points before coming to a conclusion. The numbers in vApus Mark I project that the differences between CPU choices for heavyweight VMs are not quite as large as one might suspect. Using a Clovertown for a little while longer will not necessarily cripple one's virtualization performance at this point, and though the extra features provide a notable performance increase, they will not immediately justify the cost of a complete server overhaul

A less obvious recommendation, but one not limited to merely the uses of virtualization, is the use of Large Pages to increase the amount of memory covered by the TLB and make it more efficient by reducing the number of misses. We've noticed a performance increase of roughly 5% when large pages are used in combination with Hardware-Assisted Paging.
The drawback here is somewhat the same as when using a large block size in your file system: the bigger the smallest part that can be addressed, the bigger the waste when less than a full page is needed. As virtualization generally tends to put the bulk of the memory to use, this is only a tiny consideration, however.
A second problem, however, is that Large Pages need to be enabled on both the application and the OS level and so you actually need to adapt your own software to it. In SQL Server Enterprise Edition, Large Pages are used automatically provided it is enabled on the OS-level and the amount of RAM present is higher than 8GB, but other software packages might implement it differently. We can tell you how to implement it on the OS-level, though.
Linux: Add the following lines to /etc/sysctl.conf:
vm/nr_hugepages=2048
vm/hugetlb_shm_group=55
Windows: Enable it for the required users in your Local Policies:
Start > Administrative Tools > Local Security Policy > Local Policies > User Rights Assignment > Lock pages in memory
Thirdly, with the increasing use of NUMA-architectures, there is another important consideration to keep in mind: using it as efficiently as possible by reducing remote memory access to a minimum. Luckily, ESX can take advantage of NUMA just fine with its scheduling capabilities, but as an administrator it's important to optimize the VM layout to fit the NUMA nodes. This can be achieved by preventing a single VM from requiring more memory or cores than is available in a single node. Working this way puts the hardware to use much more efficiently and effectively reduces the amount of time wasted by remote access of memory belonging to other NUMA nodes.

Naturally, this is easier said than done. Luckily, ESXtop provides us with the necessary counters to make sure a VM stays where it is supposed to be. We can make sure of this by using "ESXtop -a" to have ESXtop automatically display every single counter. By pressing "M" we can display the Memory screen, and by pressing F we can filter the display down to show only the counters we are interested in.
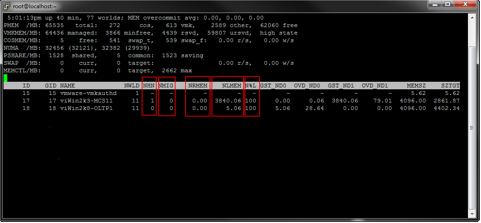
The counters that are most important with regards to NUMA are highlighted in the picture above.
NHN: This is the NUMA home node, the node on which the VM originally started.
NMIG: The amount of node migrations since startup. This should preferably stay at 0. If the VM is found migrating nodes frequently, some tuning of the VM layout may be needed.
NRMEM: This is the amount of memory that the VM is using from a remote NUMA node. Once again, this should be as low as possible, since accessing remote memory in a NUMA system is a very costly procedure.
NLMEM: This is the actual local memory in use by the VM.
N%L: This counter displays the percentage of the VM's memory that is running locally. Ideally, this should be at 100% at all times.
Network Optimizations
Network-wise, the optimizations possible are generally pretty straightforward and depend a lot on the capabilities of the NICs that are used. To get the most out of ESX, VMware recommends using a network adapter that supports the following technologies:
- Checksum offload, TCP segmentation offload, and Jumbo Frames (we'll get into this a bit deeper below): These can be checked for in Windows through the NIC's properties, and in Linux with the use of ethtool.
- Capability to handle high memory DMA (64-bit DMA addresses)
As in any clustered system, try providing separate networks to avoid traffic contention between different kinds of traffic like inter-VM communication, management traffic, storage traffic, etc.
Why would you want to use Jumbo Frames?
Rather than speeding up a network, Jumbo Frames are actually used to reduce the load on the CPU by reducing the amount of interrupts caused by the network interface during continuous traffic. Instead of the standard size of 1500 bytes, a Jumbo Frame can contain 9000 bytes. Because more data can be sent in a single frame, the overall handling costs of traffic go down, and time is freed on the CPU to spend on more exciting tasks.
Configuring a network for the use of Jumbo Frames is a different story altogether, however, because it deviates from the standard settings of a network and requires changes on every single layer of the network in question. In Linux, this is achieved on both the sender and the receiver by issuing the command: "ifconfig eth# mtu 9000" (# stands for the network adapter's number). On Windows, it needs to be set in the advanced properties of the network adapter (Device Manager > Network adapters > VMware PCI Ethernet Adapter > MTU to 9000).
In ESX's own VirtualSwitch, this setting can be changed by typing the following command in the service console: "esxcfg-vswitch -m 9000 vSwitchName". After that, it of course needs to be set on every router or switch on the way to the receiving machine before you're able to take advantage of this functionality.
We must note here that we've found a frame size of 4000 to be optimal for iSCSI, because this allows the blocks to be sent through without being spread of separate frames. Additionally, vSphere adding in support for Jumbo Frames with NFS and iSCSI on both 1Gb and 10Gb NICs allows for a large performance jump when deciding to use the latter. According to VMware, it should be possible to get 10 times as much I/O throughput with a 10Gb NIC.
What else is coming up?
Coming up in a couple of days, we will be adding the second part of this article, diving into aspects such as storage, software configuration, and scheduling mechanics. We are excited to be able to share our experiences with the platform and hope this article allows AnandTech-reading IT administrators to get the edge on their colleagues by bringing out the very best ESX has to offer. Now it's time to get back to work on putting together the second part; expect it in the course of this week.






