Original Link: https://www.anandtech.com/show/5840/gtc-2012-part-1-nvidia-announces-gk104-based-tesla-k10-gk110-based-tesla-k20
GTC 2012 Part 1: NVIDIA Announces GK104 Based Tesla K10, GK110 Based Tesla K20
by Ryan Smith on May 17, 2012 3:15 AM ESTWe’re here at NVIDIA’s GPU Technology Conference (GTC) 2012, where NVIDIA is holding their semi-annual professional developers conference. There’s been a great deal announced that will take a few days to completely go over, but for now we wanted to start on the product side with NVIDIA’s major product announcements. With the launch of GK104 back in March NVIDIA is now ready to start rolling out some of their professional productions, and while the next generation of Quadro is not yet ready, Tesla is another matter. This brings us to our first part of our GTC coverage: the next generation of Tesla cards, Tesla K10 and Tesla K20.
| Tesla K20* | Tesla K10 | Tesla M2090 | |
| Stream Processors | <=2880 | 2 x 1536 | 512 |
| Texture Units | <=240 | 2 x 128 | 64 |
| ROPs | <=48 | 2 x 32 | 48 |
| Core Clock | ? | 745MHz | 650MHz |
| Shader Clock | N/A | N/A | 1300MHz |
| Memory Clock | ? | 5GHz GDDR5 | 3.7GHz GDDR5 |
| Memory Bus Width | 384-bit | 2 x 256-bit | 384-bit |
| L2 Cache | <=1.5MB | 2 x 512KB | 768KB |
| VRAM | ? | 2 x 4GB | 6GB |
| ECC | Full | Partial (DRAM) | Full |
| FP64 | 1/3 FP32 | 1/24 FP32 | 1/2 FP32 |
| TDP | ? | 225W | 225W |
| Transistor Count | 7.1B | 2 x 3.5B | 3B |
| Manufacturing Process | TSMC 28nm | TSMC 28nm | TSMC 40nm |
The first of the new Teslas, and the only model slated to be available in the near future is the Tesla K10. In an interesting turn of events, Tesla K10 will be based on GK104. Specifically it’s a dual-GPU card based on NVIDIA’s recently launched GTX 690, modified to fit the needs of the GPU compute market. Previous generation Tesla cards have always been based on NVIDIA’s top-tier GPUs – GT200 and GF100/GF110 respectively – so this is the first time NVIDIA has ever split the Tesla market in this way by using a lower tier GPU.
The fact of the matter is that with GK104 first launching in GeForce products, NVIDIA downplayed GK104’s compute capabilities. And our own benchmarking has established that GTX 680’s compute performance is anywhere between slightly ahead of the Fermi based GTX 580 to well behind it. Being a descendant of GF114, GK104 had a fair bit of its compute capabilities stripped out relative to GF110, not the least of which is double-precision floating point performance, ECC cache protection, and a about half of the number of registers per CUDA core relative to Fermi.
Given the questionable compute performance of GK104, this makes NVIDIA’s decision to launch a Tesla part based on it quite unexpected. Still, this is not to say that GK104 can’t perform well in the right situations and this is exactly what NVIDIA designing K10 around. The fact that we’ve found GK104 cards to be slow at compute workloads at times is not lost on NVIDIA; they know better than anyone else what GK104 really can and can’t do and have planned accordingly. For that reason NVIDIA is breaking from what little tradition there is with Tesla as a broad market product and pitching K10 at a very specific market.

NVIDIA’s market strategy here is actually summed up rather well in their K10 press release: “NVIDIA Tesla K10 GPU Accelerates Search for Oil and Gas Reserves, Signal and Image Processing for Defense Industry.” GK104 lacks the ECC and compute flexibility of the Fermi Tesla cards, but what it doesn’t lack is single-precision compute performance and memory bandwidth; and with a dual-GPU card in particular it has both of those in spades. Accordingly, NVIDIA’s goal for K10 is to go after the specific market segments that don’t need ECC and don’t need flexibility, but do need all the raw compute performance they can get. This as it turns out is something gamers are already familiar with: image processing. Image processing doesn’t need the incredible levels of precision that pure computational work does and for that matter it’s rather tolerant of the errant error, so NVIDIA believes there’s a suitably large market there that can be served by GK104 rather than GK110.
With that said, I must admit that if GK110 had come first I don’t know if we’d be having this conversation. Even if a dual GK104 card is faster splitting their market like this is not an easy to move to make. But with GK110 not due in retail for another 5-6 months it’s obviously NVIDIA’s only choice if they want to get new Tesla cards out on the market before the end of the year.

In any case we’ll know more about the full performance of K10 soon enough. Based on GTX 680 I think we already have a good idea of GK104’s basic strengths and weaknesses, but I also have to consider the possibility that NVIDIA has been sandbagging the GTX 600 series’ compute performance. NVIDIA has handicapped GeForce performance in a few different ways for quite a number of years in order to create distinct market segments, first for Quadro and more recently for Tesla. With GTX 580 this was done by handicapping both double-precision and geometry performance, but because GK104 is inherently weak at double-precision NVIDIA would need to handicap the GTX 600 series in some other manner if they wanted to maintain this kind of market segmentation. So perhaps GK104 is actually faster at compute than what we’ve seen so far?
Wrapping things up, while NVIDIA hasn’t posted every last spec for K10 they have posted enough for us to work with. Like GTX 690 K10 is using fully enabled GK104 GPUs, so based on NVIDIA’s theoretical performance data of 4.58TFLOPs with 320GB/sec of bandwidth it’s almost certainly clocked at around 745MHz core and 5GHz memory. Meanwhile for memory the card has 8GB of GDDR5, which breaks down to 16 2Gb GDDR5 modules per GPU for a total of 32 on the card. TDP is said to be identical to M2090, which would make it a 225W part. Finally, as far as availability and pricing is concerned officially K10 is available “now” though in practice partners won’t be shipping cards and systems until closer to the end of the month. Pricing is expected to be close to that of the M2090 it replaces, which would mean we’re looking at $2500 and higher.
The other Tesla announced this week is Tesla K20, which is the first and so far only product announced that will be using GK110. Tesla K20 is not expected to ship until October-November of this year due to the fact that GK110 is still a work in progress, but since NVIDIA is once again briefing developers of the new capabilities of their leading compute GPU well ahead of time there’s little reason not to announce the card, particularly since they haven’t attached any solid specifications to it beyond the fact that it will be composed of a single GK110 GPU.

GK110 itself is a bit of a complex beast that we’ll get into more detail about later this week, but for now we’ll quickly touch upon some of the features that make GK110 the true successor to GF110. First and foremost of course, GK110 has all the missing features that GK104 lacked – ECC cache protection, high double precision performance, a wide memory bus, and of course a whole lot of CUDA Cores. Because GK110 is still in the lab NVIDIA doesn’t know what will be viable to ship later this year, but as it stands they’re expecting triple the double precision performance of Tesla M2090, with this varying some based on viable clockspeeds and how many functional units they can ship enabled. Single precision performance should also be very good, but depending on the application there’s a decent chance that K10 could beat K20, at least in the type of applications that are well suited for GK104’s limitations.
As it stands a complete GK110 is composed of 15 SMXes – note that these are similar but not identical to GK104 SMXes – bound to 1.5MB of L2 cache and a 384bit memory bus. GK110 SMXes will contain 192 CUDA cores (just like GK104), but deviating from GK104 they will contain 64 CUDA FP64 cores (up from 8, which combined with the much larger SMX count is what will make K20 so much more powerful at double precision math than K10. Of interesting note, NVIDIA is keeping the superscalar dispatch method that we first saw in GF104 and carried over to GK104, so unlike Fermi Tesla products, compute performance on K20 is going to be a little more erratic as a result of the fact that maximizing SMX utilization will require a high degree of both TLP and ILP.

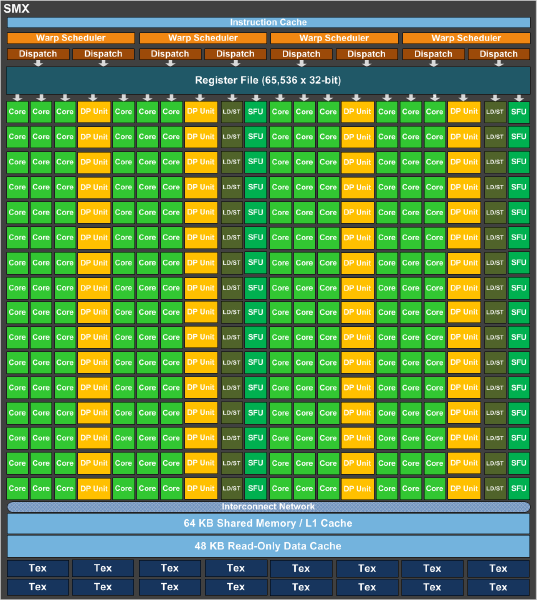
Along with the slew of new features native to the Kepler family and some new Kepler family compute instructions being unlocked with CUDA 5, GK110/K20 will be bringing with it two major new features that are unique to just GK110: Hyper-Q and Dynamic Parallelism. We’ll go over both of these in depth in the near future with our look at GK110, but for the time being we’ll quickly touch on what each of them does.
Hyper-Q is NVIDIA’s name for the expansion of the number of work queues in the GPU. With Fermi NVIDIA’s hardware only supported 1 hardware work queue, whereas GK110 will support 32 work queues. The important fact to take away from this is that 1 work queue meant that Fermi could be under occupied at times (that is, hardware units were left without work to do) if there wasn’t enough work in that queue to fill every SM, even with parallel kernels in play. By having 32 work queues to select from, GK110 can in many circumstances achieve higher utilization by being able to put different program streams on what would otherwise be an idle SMX.


The other major new feature here was Dynamic Parallelism, which is NVIDIA’s name for the ability for kernels to be able to dispatch other kernels. With Fermi only the CPU could dispatch a new kernel, which incurs a certain amount of overhead by having to communicate back and forth with the CPU. By giving kernels the ability to dispatch their own child kernels, GK110 can both save time by not having to go back to the GPU, and in the process free up the CPU to work on other tasks.
Wrapping things up, there are a few other features new to GK110 such as a new grid management unit, RDMA, and a new ISA encoding scheme, all of which are intended to further improve NVIDIA’s compute performance, both over Fermi and even GK104. But we’ll save these for another day when we look at GK110 in depth.






