Original Link: https://www.anandtech.com/show/1854
Itanium - is there light at the end of the tunnel?
by Johan De Gelas on November 9, 2005 12:05 AM EST- Posted in
- CPUs
Introduction
On HP's website, these prophetic words are hidden, but can still be found:
"EPIC is the old term for what is now known as the ItaniumTM processor family architecture, co-developed by HP and Intel®. This design philosophy will one day replace RISC and CISC. It is a gateway into the 64-bit future but it still remains completely 32-bit compatible."These sentences showed how bullish HP and Intel were a few years ago about their new creation. But in 2005, the reality is somewhat different:
"Dell will phase out its remaining computer based on Intel's Itanium microprocessor, in another sign of the waning interest in a chip that cost an estimated several billion dollars to develop." The Wall Street Journal, September 15th 2005.While it is hardly news that Dell, who doesn't believe in "big iron" anyway, is dropping Itanium, the rest of the sentences that the WSJ journalist wrote down seem to spell doom.
As the Itanium market is still limited to HPC and (ultra) high-end servers, Microsoft is losing interest in the Itanium. IA 64 versions of Longhorn are low priority and only the future of the High Performance Computing version for Itanium seems certain. Visual Studio 2005 does not even support the Itanium platform. Dell and IBM are no longer interested. It is not going too well for Itanium.
A few years ago, analysts predicted doom for Sun; not completely without reason, as the Intel Itanium 2 and IBM Power 5 clearly wipe the floor performance-wise with the UltraSparc CPUs. However, Sun's revenge is very sweet. Sun's newest Galaxy servers with up to 16 Opteron cores are a very competitive platform for the expensive Itanium servers. The Galaxy servers are well suited for clustering, so even in the market niche that requires more than 16 CPUs, are the Itanium based machines threatened by a cheaper alternative?
Although the AMD Opteron targets a different market than the Intel Itanium, the Opteron market is expanding towards the high end, thanks to Sun, which in turn forces Intel to expand the feature set of the Xeon. Back in 2004 when EM64T was introduced, Intel pointed out that EM64T was only introduced on the Xeon DP. Intel probably expected the Opteron to be limited to workstations and entry level servers. However, the Opteron was very successful in the quad CPU market, and then it entered the 8-way and 16-way CPU market too. Intel had no choice then to counter attack and equip the Xeon MP with EMT64 and much higher clockspeeds than before the Opteron era, better RAS features and massive (for x86) L3 caches, up to 8MB big.
Is Itanium nothing more than over an ambitious project that resulted in a CPU of titanic proportions? In this article, we try to answer the question of whether or not the EPIC CPU has a bright future ahead. To answer that question, we'll focus on the technical advantages and disadvantages of the chip, and look ahead to see if the architecture can still grow enough to outpace the competition.
The End of a Generation
Indeed, you might ask yourself, why do we even bother writing articles about Itanium? It is, after all, a massive CPU that ends up in very expensive machines, mostly huge database servers and HPC machines for scientific purposes; machines that most of us will never consider buying, not even for business purposes.

Sturdy heatsinks for the Itanium
Still, despite its rather dull reputation of a big iron CPU, and the flood of negative predictions, the EPIC has something fascinating. From a purely technical and academic point of view - completely ignoring the economical and business logic - there are some strong indications that time may well be on the side of the EPIC CPU despite all doom scenarios. That might sound insane right now, but allow me to explain this statement.
As we stated in the "The Quest for More Processing Power, Part One", the CPU performance increase that we enjoyed during the golden era of the PC from 1981 to 2002 has hit the brakes, and is decreasing quickly. Back in the nineties, Intel and others introduced techniques like superscalar wide issue, out of order execution with big reorder buffers, speculative execution, integrated L2-caches, register renaming and dynamic branch prediction, which all increased the number of instructions that could be processed per cycle (IPC) on average. The AMD Athlon, which was introduced in 1999, and the Thunderbird incarnation in 2000 could be considered as the last representatives of this superscalar generation. Macro ops fusion, introduced in the Athlon, where two operations are travelling down the pipeline together until they get separated to get executed, was one of the last major tricks of this generation.
Since then, only one improvement has really pushed performance per cycle forward: the on die memory controller (ODMC). Sure, there have been other "little tricks" that have steadily improved performance, but nothing spectacular. The CPU engineers still have a few tricks upon their sleeves that can improve IPC somewhat, but are limited to those that do not increase leakage and dynamic power loss. The focus is no longer on IPC or Instruction Level Parallelism (ILP). It is on Thread Level Parallelism (TLP).
A good example of how the engineering focus has shifted is branch prediction. Quite a bit of resources have been spent on the Pentium 4's branch predictor, involving a whole team of Intel engineers. The result was that, on average, the Pentium 4 branch predictor is accurate 95-97% of the time, while the P6 BPU was accurate only 90% of the time.
At Spring IDF 2005, when Anand, Derek and I asked Justin Rattner what Intel is doing in the field of even more advanced Branch prediction, he smiled. He told us that the current team who works on branch prediction is very small...around one person.
There is no doubt that the whole industry has shifted their focus away from ramping clock speed and improving ILP to increasing performance by exploiting TLP. So, how does this affect Itanium and its EPIC foundation? Before we answer that, let us quickly review the basics behind the Itanium/EPIC philosophy.
EPIC 101
The basics of EPIC (Explicitly Parallel Instruction-set Computing) is a mix of typical RISC and VLIW (very long instruction word) features. From RISC, it copies a relatively straightforward instruction set, a very large register file (128 registers for integer and floating point) and three operand instructions that use registers. Using three operands, two source registers and a destination register (R1 = R2 +R3), instead of two (R2 = R1 + R2), does the calculation job in less instructions and avoids - given enough registers - unnecessary trips to hidden registers or the L1- cache.
Load and Store instruction are used to getting data and instructions from the memory; instructions that actually calculate do not reference memory locations as in x86.
A fixed instruction length makes it much easier to decode, like RISC ISA's, and completely contrary to the x86 instruction set where decoding is a very painful job that requires many pipeline stages. These additional stages are necessary to obtain high clockspeeds, but they make the pipeline unnecessarily long and the branch prediction penalty worse. The Itanium 2 has only an 8-stage pipeline, but is still able to clock up to 1.7 GHz (conservative) using a 130 nm process. Compared to the Xeon MP (130 nm), which clocked up to 3 GHz, it needed a 28-stage pipeline (20 after Trace cache + 8 before) to achieve less than a twice as high a clock speed.
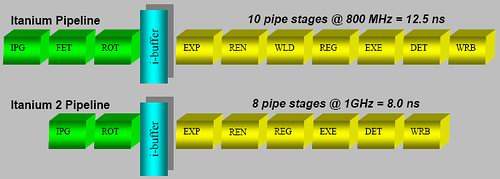
The short Itanium and Itanium 2 pipeline
Inside the hardware, the Itanium uses instruction bundles that are 128 bits large. Such a bundle consists of three 41 bit instructions and one 5 bit template. It is this 5 bit template that contains the "compiler grouping" information about the parallelism between the different instructions. Thus, compilers will use this template to tell the CPU what instructions should be issued together. It gets even better; this template also contains an end-of-bundle bit. With this bit, the compiler can indicate whether or not the bundle is finished after the first three instructions or if the CPU should chain two (or even more) bundles together.

IA-64 instruction bundle
Another 6 bits specify the 64 combinations of predication that allow the compiler to eliminate branches, as each instruction can be conditional. So, instead of:
Compare R1 to 0 (IF...)You get:
If false jump to Label
R2 =R3 ("Then" instructions)
Label: (Else instructions)
R2 =R1
On the condition that R=0, R2=R3So you eliminate the conditional jump ("If false, jump to") and replace the whole "IF THEN ELSE" clause with an instruction that checks the register and then moves the contents from R3 to R2 in one sweep. Conditional jumps are dependant on the instruction before it and they have to wait until the "Compare R1 to 0" instruction is done. Conditional instructions, however, travel through the pipeline for execution and don't have to wait for anything. You could say that the "IF" part and "Then" part are fused together. For the "else" part, you get:
On the condition that R<>0, R2 = R1Predication makes the code more compact, and eliminates branches and dependencies. Branches can make up 20% of your code, easily. So, with one branch every 5 instructions, it is very hard to issue many instructions in parallel. By converting them into conditional instructions, you eliminate the dependencies and the ILP can get much higher.
The instruction grouping and elimination of most of the branches opens the way to higher ILP. So, while the Athlon 64 can sustain at most 3 instructions per clock cycle, the Itanium can fetch, decode, issue, execute and retire 2 bundles or 6 instructions per clock cycle.
Contrary to old VLIW designs, the compiler is not obliged to put the instruction in a strict order in a bundle. But there are certain limitations to what kind of instruction mix you can find inside a bundle, as you can see in the table below.
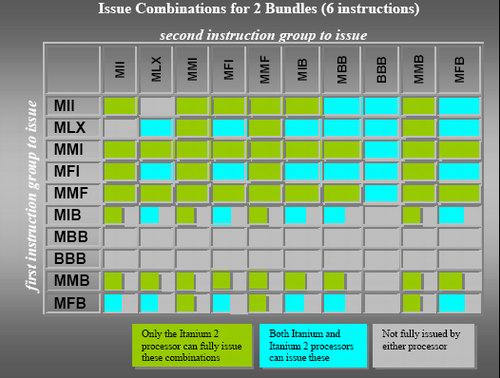
Possible bundles
Cache hints, data and instruction pre-fetching and data speculation are a few of the tricks that the Itanium and its compiler can use to keep the caches full with the right instructions and data. Those tricks and the large caches are essential to the Itanium: a L2 cache miss can result in a real stall, as the CPU cannot check dynamically for independent instruction to issue.
In a nutshell, the Itanium has the following advantages:
- Easy decoding leads to a shorter pipeline as less decoding work has to be done, so less stages are necessary;
- In order issue and execution means that dispatch hardware is much simpler, which leads to a shorter pipeline and less transistors;
- Removing conditional jumps and letting the compiler do the scheduling extracts more ILP; and
- 128 registers and the load/store model reduce the number of memory/cache accesses significantly,
- No out-of-order execution makes cache misses and pipelines stalls much more costly; and
- 128 registers and the whole bundle and group system make the instructions on average much longer than x86.
The CPU industry in three words
If we would summarize the current trends in the CPU industry in three words, we think that those three words would be "TLP, caches and power consumption"[2]. TLP gets exploited more and more with the introduction of multi-threaded and multi-core CPUs. Caches get bigger and bigger as they don't increase power, but rather save power by preventing costly accesses to the memory controller. Power consumption determines which performance increasing techniques get the spotlight: wasteful techniques such as Dynamic Multi-Threading, double-pumped ALUs and extremely deep Out Of Order (OOO) windows that have fallen out of grace as they consume too much power.
It is pretty clear that these three trends - bigger caches, power consumption being a deciding factor in CPU design, and TLP - will continue to influence the CPU architectures heavily in the coming years. How would this be beneficial to an EPIC CPU?
The Cache story
Bigger caches are what the EPIC CPU needs. One of the biggest disadvantages of the EPIC CPU is code inflation. When we compiled some source (64 bit) code on the Itanium back in 2001, the code was about 2.5 to 3 times bigger than (32 bit) x86 code. That is not really surprising: an IA-64 128 bit bundle contains 3 instructions. An x86 instruction can be from 1 to 17 bytes long, but is on average a little less than 3 bytes or 24 bits long. That means that x86 instructions are on average about 2 times more compact. There are many other reasons why EPIC code is more bloated than x86. Because of restrictions on the types of instructions that can be placed in each slot of an IA-64 bundle and the fact that a bundle must be of the same length, IA-64 requires NOPs in unfillable slots. This leads to the insertion of NOPs or useless instructions that take up space.
The whole complex x86 architecture has been built to conserve RAM space as RAM was very expensive in the days during which x86 was developed. In more recent years, this feature has helped x86 as it didn't need the big caches that RISC and EPIC CPUs need. A RISC instruction is (at least) 32 bits long, or at least 33% bigger than an x86 instruction.
Currently, it seems that EPIC compilers produce code that is at least - roughly estimated - twice as big as AMD64 or EM64T code. This means that if you want to compare an Itanium instruction cache to the Opteron instruction cache, you have to divide the Itanium Instruction cache in two.
So, the L1 cache of 8 KB (16 KB/2) looks tiny compared to the massive 64 KB of the Opteron. If we assume that data and instructions take about the same size in the shared L2, the Itanium 2's L2 is 192 KB big (128 KB/2 I + 128 KB D), which is small compared to the Opteron's 1 MB and Xeon's 2 MB L2. That is the reason why Montecito has a 1 MB L2-I Cache and a 256 KB Data cache. This will increase IPC significantly: cache misses are deadly for the in order Itanium.
Time is on the side of the Itanium. As new process technology was introduced, cache sizes have been growing very quickly during the past years, without introducing extra cost or high latency. No competitor has the advantages that Itanium has:
- As caches get bigger, Itanium benefits more than the x86 competition. X86 CPUs target higher clock speeds and, as such, it is more difficult to use large low latency caches.
- Intel has mastered as no other the skill to produce very dense and fast cache structures.
The limits of TLP...
Hardware engineers do not believe in massive superscalar CPUs anymore[2]. Increasing ILP a tiny bit requires exponentially bigger out-of-order hardware, which exponentially requires more power.
TLP and multi-core is hot and trendy. But the same problems that were true for squeezing ILP out of hardware are true about TLP in software. On the exception of naturally parallel applications such as rendering and database servers, getting more and more threads out of the majority of hardware will require exponentially more programming and debugging time. There are more high TLP designs such as Sun's Niagara that increase throughput, but also response time. And while the numbers of users that can update and read the database matters, the response time of the database can be important too. For example, while OLTP loads consist of many relatively simple SQL selects, Decision Support Systems (DSS or OLAP) fire off very complex queries with a high response time. To offer a good "data mining" experience, the single thread performance must not be neglected. The same can be said for some HPC and many typical workstation applications.
So, while designs that sacrifice ILP completely on the altar of TLP, such as Sun's Niagara, they may well be very popular in some markets such as webserving. Single thread performance is going to make the difference between the different multi-core solutions.
Here, the Itanium can leverage two big advantages: higher ILP and smaller cores. This last comment might seem ridiculous, given that the current Itanium Madison is about 432 mm2 large. However, if we look at the core (L1 inclusive), there about 25 million transistors that take about 80 mm2 die space. Note that the pictures below have been scaled and resized to reflect the relative proportions of the different cores.
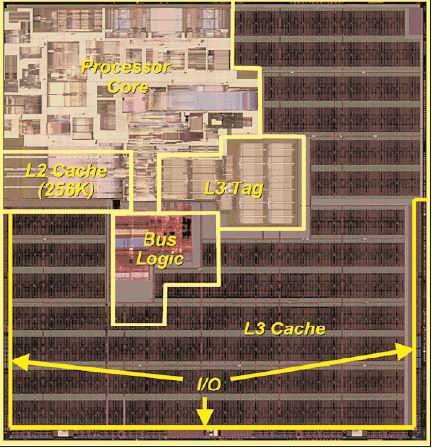
Madison 9 MB die
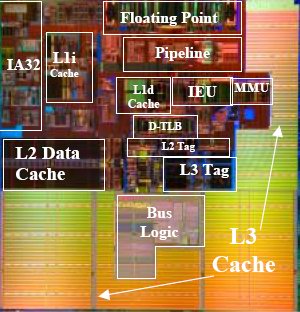
Madison core parts

Opteron die, rotated 90°
Itanium: a slim figure
We compare the different CPU cores in the table below. We consider the L1-cache being part of the core, but we list the number of transistors separately to be clear. To keep it fair, we compare all CPU using the same process technologies, 0.13µ, with the exception of the Intel Xeon.
There is no doubt that a 0.13µ Xeon MP is no match for either of the IBM Power 5, the Itanium or Opteron with both Spec FP2000 and SpecInt around 1200 for a Xeon MP 3 GHz. The Xeon MP 0.13µ is also a 32 bit CPU, so it does not belong in the list below.
The reason why I listed the 90nm Xeon (DP) is to show how complex an x86 architecture can get when it has 64 bit and an extremely deep pipeline in a quest for high clock speeds, which must negate the low ILP. With more than 50 million transistors, it is no wonder that Xeon "Irwindale/Nocona" is the hottest CPU (per core) of the bunch despite being manufactured in a more advanced process.
Why do we use Spec FP2000 and Spec Int2000[3]? It is true that these benchmarks are close to meaningless when you want to compare server or workstation performance in the real world. Spec FP is a decent predictor of HPC/scientific performance, but fails to predict Digital Content Creation performance despite containing a few OpenGL benchmarks. The reason why we use these two benchmarks is that currently, we are evaluating the CPU architecture, its future potential and current compiler performance, and not the complete system.
| CPU feature | Intel Itanium "Madison" | Intel Xeon P4 Irwindale | IBM Power 5 (+) | AMD Opteron |
| Process technology | 0.13 µ CU | 0.09 µ CU | 0.13 µ CU SOI | 0.13 µ CU SOI |
| Die Size (mm2) | 432 | 130 | 389 | 190 |
| Number of transistors (Million) | 592 | 169 | 276 | 106 |
| Number of transistors (Million) L1-cache | 1.8 | +/- 6 | 5.3 | 7.7 |
| Number of transistors (Million) L2 Cache | 14 | 113 | 107 | 57 |
| Number of transistors (Million) L3 Cache | 510 | 0 | off die | 0 |
| Number of transistors (Million) Tag (L2 + L3) | 23 | 4 | 33 | 4 |
| Number of transistors (Million) Core | 20 | 50 | 35* | 40 |
| Pure logic core (-L1) | 18 | 44 | 30 | 32 |
| Top clock speed | 1600 | 3800 | 1900 | 2600 |
| Best Spec FP2000 Score | 2712 | 1898 | 2839 | 1955 |
| Best Spec Int2000 Score | 1590 | 1810 | 1470 | 1713 |
| TDP | 107 W | 115-130 W | 200 W** | <95W |
** for two cores
To calculate the cache sizes, we used the following formula:
Cache size expressed in Bytes x 9 bits per byte (8 + 1 bit ECC/parity protection) x 6 Transistors per bit (SRAM)We calculated the Power 5 core as follows. The PowerPC 970FX, aka Apple's G5, is essentially a Power 4 core with Altivec, but without the L3 cache tag. If we subtract the number of transistors of the L2 cache (28 million) from the total number of transistors in the PowerPC 970, we end up with about 30 million transistors. The Power 5 core is a bit more complex (SMT and a few tweaks have been added), so we estimate it at about 35 million transistors.
HP and Intel have stated that the Itanium 2 core, including the L2-cache, has about 40 million transistors. If we subtract the L2 cache, we end up with about 26 million transistors, which still includes the x86 compatibility transistors (about 4 million) and the L2-tag. It wouldn't be fair to include the x86 transistors when we compare the merits of EPIC with x86 and RISC.

The Itanium core is twice as small as the Xeon's
And, what about the Pentium M? Well, the core is about 25 million transistors, but it is pretty hard to compare this CPU with Itanium as the Pentium M is optimised for low power consumption. If we keep it fair and compare the two cores using the same process technology, the Pentium M isn't even close when it comes to performance. A 2 GHz Pentium M scores a respectable 1500 in SpecInt, but trails far behind with a specfp score of about 1000.
The benefits of TLP...
It is clear that the Itanium core has a big advantage in the area of threading and power dissipation constraints. If you are not convinced, the dual core Itanium Montecito (90 nm process) has no less than 1.72 billion transistors, but it is still able to consume less than 130 W. Compare this with the 300 million transistor Power 5+, which consumes about 170 W on a 90 nm SOI process.
And there is more. X86 CPUs are limited to a maximum of 3 decoded, issued and retired instructions. This might increase to 4 next year. But compared to the best x86 design today - the AMD Opteron -, the Itanium does about 60% more work per clock cycle in integer, and about 115% more work per cycle in floating point. Don't get me wrong, these numbers are no indication of superiority of any kind - clock speed matters just as much. But what these numbers tell you is that x86 designs are less brainiac in nature, and that the x86 ISA limits the ILP much more than IA-64 (we will give more proof in a later article). x86 designs prefer the speed-demon approach with deeper pipelines.
The Itanium can sustain 6 instructions per cycle and can issue up to 11 instructions. A lot of this potential goes to waste, but it also means that the potential gains for Multi-Threading techniques are much higher. While the Pentium 4 Xeon was unable to show any significant performance advantage due to SMT in our server tests[4], Montecito is claimed to be 30% faster in typical database loads, thanks to a Coarse Multi-Threading technique that is less advanced than Hyper Threading.
Itanium's future...
There is no doubt about it, the delay of Montecito and Intel's poor execution is a serious blow to the Itanium family. The Montecito based Itanium 2 has the features that it needs to be competitive in the server world for the next years: dual core, multi-threading and virtualization (Silverdale). Without these features, Itanium is hopelessly behind the competition, especially the dual core Xeon, Opteron and Power 5+. The Xeon and Opteron might still be a bit behind on the RAS features, but this can change quickly and is only important for a small part of the market.
If we ignore Intel's poor execution during the past months and the economic realities, and focus on the architecture, it is clear, however, that the Itanium has time on its side and is most likely the architecture with the highest potential.
Although the Itanium is capable of sustaining a theoretical maximum of 6 instructions and executing up to 11 instructions, and despite its massive register set, it uses fewer transistors for its core than all competitors. The main disadvantage is that it needs much more cache and instruction fetch width, but the disadvantage of needing more cache diminish as process technology gets better (smaller). To improve performance, the Itanium needs much bigger caches than its competitors, but this adds very little to the overall power consumption. As superscalar RISCs in x86 competitors increase their instruction execution width, they need to upgrade the Out-Of-Order buffers and more importantly, increase the complexity of the schedulers. This leads to a much higher complexity and power consumption.
As the focus shifts to Thread Level Parallellism, the Itanium's small cores make it easier to use more cores without increasing the power consumption too much. Montecito will be the living proof of this. The Itanium is also wider than the competition, which results in bigger benefits from threading techniques.
While Itanium may not be very popular in the hardware enthusiast community, it is definitely an architecture that, from an academic and technical point of view, deserves a lot more attention. We'll delve deeper in upcoming articles.
References
[1] The Quest for More Processing Power, Part One: "Is the single core CPU doomed?"
http://www.anandtech.com/cpuchipsets/showdoc.aspx?i=2343
[2] Hyper-Threading Technology Architecture and Microarchitecture
http://www.intel.com/technology/itj/2002/volume06issue01/art01_hyper/p01_abstract.htm
[3] Ace's hardware Specmine
http://www.aceshardware.com/SPECmine/
[4] Linux database server CPU comparison
http://www.anandtech.com/IT/showdoc.aspx?i=2447






