Intel's Xeon Cascade Lake vs. NVIDIA Turing: An Analysis in AI
by Johan De Gelas on July 29, 2019 8:30 AM ESTConvolutional Neural Network Training
For a long time, the way forward in CNNs was to increase the number of layers – increasing the network depth for "even deeper learning". As you can probably guess, this resulted in diminishing returns and made the already complex neural networks even harder to tune, leading to more training errors.
The ResNet-50 benchmark is based upon residual networks (hence ResNet), which have the merit of fewer training errors as the network gets deeper.
Meanwhile, as a little bit of internal housekeeping here, for regular readers I’ll note that the benchmark below is not directly comparable to the one that Nate ran for our Titan V review. It is the same benchmark, but Nate ran the standard ResNet-50 training implementation that is included in NVIDIA's Caffe2 Docker image. However, since my group is mostly using TensorFlow as a deep learning framework, we tend to with stick with it. All benchmarking
tf_cnn_benchmarks.py --num_gpus=1 --model=resnet50 --variable_update=parameter_server
The model trains on ImageNet and gives us throughput data.
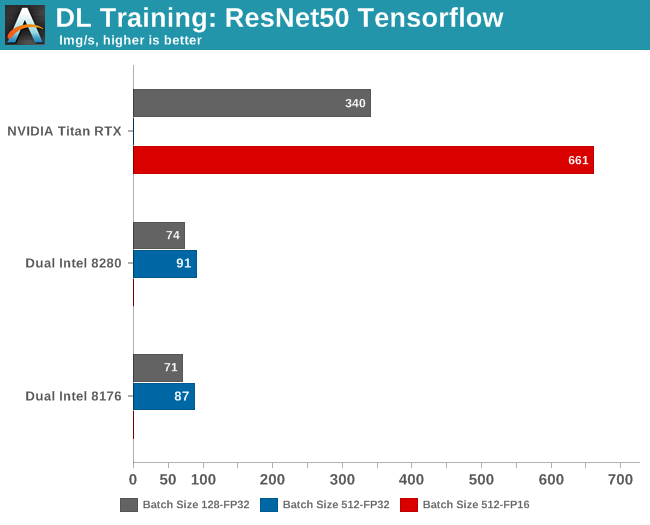
Several benchmarks are missing, and for a good reason. Running a batch size of 512 training samples at FP32 precision on the Titan RTX results in an "out of memory" error, as the card "only" has 24 GB available.
Meanwhile on the Intel CPUs, half precision (FP16) is not (yet) available. AVX512_BF16 (bfloat16) will be available in the Cascade Lake's successor, Cooper Lake.
It has been observed that using a larger batch can causes significant degradation in the quality of the model, as measured by its ability to generalize. So although larger batch sizes (512) make better use of the massive parallelism inside the GPU, the results with the lower batch sizes (128) are useful too. The accuracy of the model loses only a few percent, but in many applications a loss of even a few percent is a significant.
So while you could quickly conclude that Titan RTX is seven times faster than the best CPU, it is more accurate to say that it is between 4.5 and 7 times faster depending on the accuracy you want.
Inception (v3)
Inception is based upon GoogLeNet. Contrary to the earlier dense neural networks, GoogLeNet was based on the idea that neural networks can be much more efficient if you do not connect every neuron in every layer to the next one. The downside of this optimization is that this results in sparse matrices, which are far from optimal for the typical SIMD/GPU architectures and their BLAS software.
Overall, the main goal of "Inception" was to turn GoogLeNet into a neural network that would result in dense matrix multiplication. Or in other words, something that ran a lot faster on a GPU or SIMD hardware. In the end, version 3 of this neural network has proven to be even more accurate than ResNet-50.
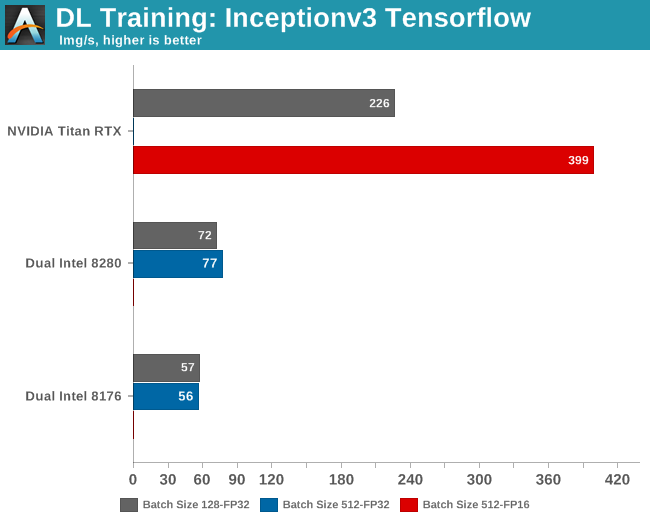
This time, the GPU is about 3 to 5 times faster, depending on the batch size. It is interesting to note that ResNet is more GPU friendly than Inception. But of course, this only matters for academics and hardware enthusiasts.
Software engineers who have to build AI models will however remark quickly that a $3k GPU is at least 3 times faster than a $20k+ (or worse) CPU configuration. And they are right: there is no contest. When it comes to Convolutional Neural Networks, the rock stars of AI, a good GPU (with a good software stack) will mop the floor with even the best CPUs. In a datacenter you typically encounter the NVIDIA Tesla GPUs which cost around four times more, but offer anywhere from 1.5x to 2x the performance of similar Titan cards.








56 Comments
View All Comments
tipoo - Monday, July 29, 2019 - link
Fyi, when on page 2 and clicking "convolutional, etc" for page 3, it brings me back to the homepageRyan Smith - Monday, July 29, 2019 - link
Fixed. Sorry about that.Eris_Floralia - Monday, July 29, 2019 - link
Johan's new piece in 14 months! Looking forward to your Rome review :)JohanAnandtech - Monday, July 29, 2019 - link
Just when you think nobody noticed you were gone. Great to come home again. :-)Eris_Floralia - Tuesday, July 30, 2019 - link
Your coverage on server processors are great!Can still well remember Nehalem, Barcelona, and especially Bulldozer aftermath articles
djayjp - Monday, July 29, 2019 - link
Not having a Tesla for such an article seems like a glaring omission.warreo - Monday, July 29, 2019 - link
Doubt Nvidia is sourcing AT these cards, so it's likely an issue of cost and availability. Titan is much cheaper than a Tesla, and I'm not even sure you can get V100's unless you're an enterprise customer ordering some (presumably large) minimum quantity.olafgarten - Monday, July 29, 2019 - link
It is available https://www.scan.co.uk/products/32gb-pny-nvidia-te...abufrejoval - Tuesday, July 30, 2019 - link
Those bottlenecks are over now and P100, V100 can be bought pretty freely, as well as RTX6000/8000 (Turings). Actually the "T100" is still missing and the closest siblings (RTX 6000/8000) might never get certified for rackmount servers, because they have active fans while the P100/V100 are designed to be cooled by server fans. I operate a handful of each and getting budget is typically the bigger hurdle than purchasing.SSNSeawolf - Monday, July 29, 2019 - link
I've been trying to find more information on Cascade Lake's AI/VNNI performance, but came up dry. Thanks, Johan. Eagerly putting this aside for my lunch reading today.