AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
AMD Zen 2 Microarchitecture Overview
The Quick Analysis
At AMD’s Tech Day, on hand was Fellow and Chief Architect Mike Clark to go through the changes. Mike is a great engineer to talk to, although what always amuses me (for any company, not just AMD) is that engineers that talk about the latest products coming to market are already working one, two, or three generations ahead at the company. Mike remarked that it took him a while to think back to the specific Zen+ to Zen 2 changes, while his mind internally is already several generations down the line.
An interesting element to Zen 2 is around the intention. Initially Zen 2 was merely going to be a die shrink of Zen+, going from 12nm down to 7nm, similar to what we used to see with Intel in its tick-tock model for the initial part of the century. However, based on internal analysis and the time frame for 7nm, it was decided that Zen 2 would be used as a platform for better performance, taking advantage of 7nm in multiple ways rather than just redesigning the same layout on a new process node. As a result of the adjustments, AMD is promoting a +15% IPC improvement for Zen 2 over Zen+.
When it comes down to the exact changes in the microarchitecture, what we’re fundamentally looking at is still a similar floorplan to what Zen looks like. Zen 2 is a family member of the Zen family, and not a complete redesign or different paradigm on how to process x86 – as will other architectures that have familial updates, Zen 2 affords a more efficient core and a wider core, allowing better instruction throughput.
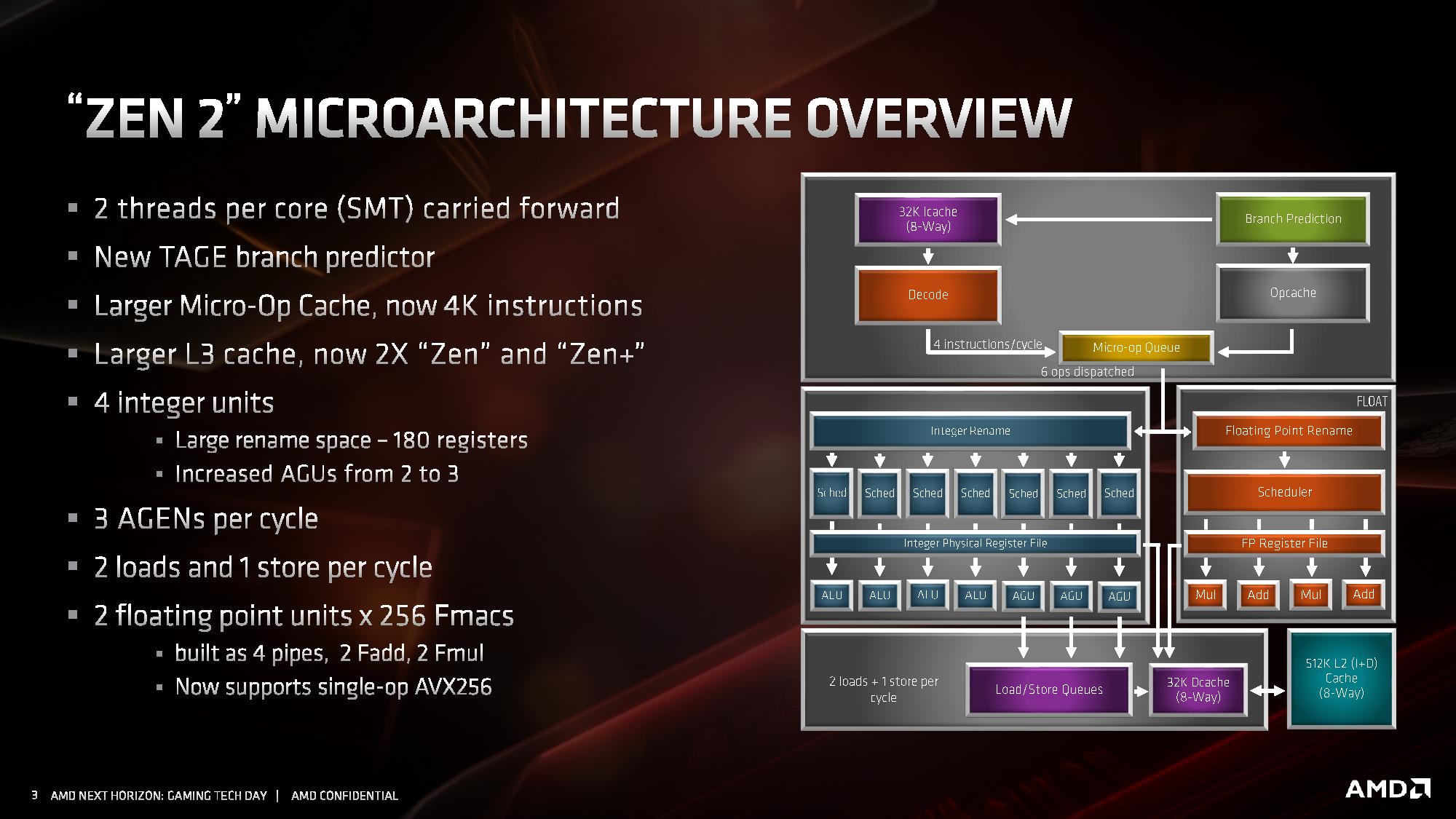
At a high level, the core looks very much the same. Highlights of the Zen 2 design include a different L2 branch predictor known as a TAGE predictor, a doubling of the micro-op cache, a doubling of the L3 cache, an increase in integer resources, an increase in load/store resources, and support for single-operation AVX-256 (or AVX2). AMD has stated that there is no frequency penalty for AVX2, based on its energy aware frequency platform.
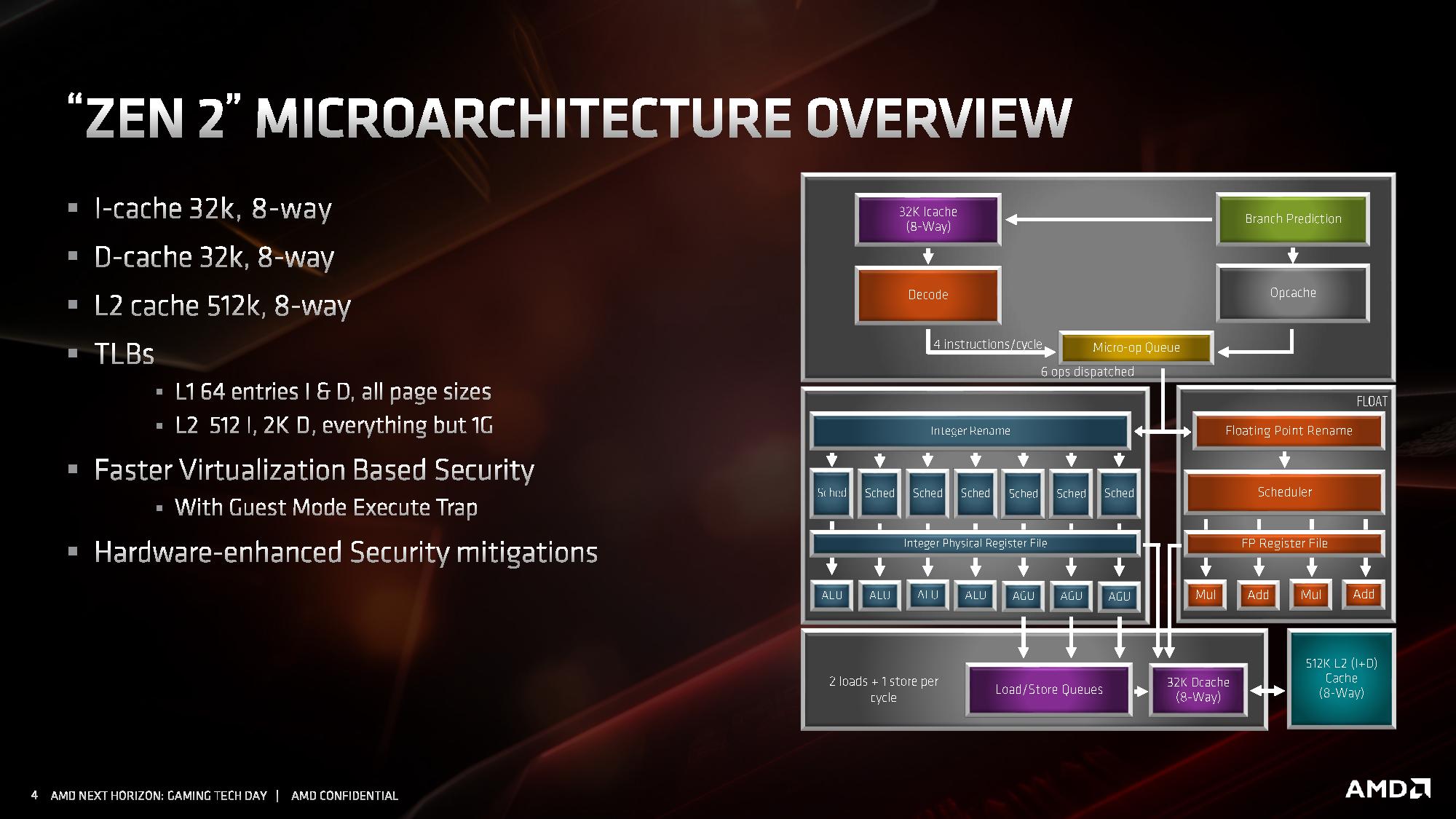
AMD has also made adjustments to the cache system, the most notable being for the L1 instruction cache, which has been halved to 32 kB, but associativity has doubled. This change was made for important reasons, which we’ll go into over the next pages. The L1 data cache and L2 caches are unchanged, however the translation lookaside buffers (TLBs) have increased support. AMD also states that it has added deeper virtualization support with respect to security, helping enable features further down the pipeline. As mentioned previously in this article, there are also security hardening updates.
For the quick analysis, it’s easy to tell that doubling the micro-op cache is going to offer a significant improvement to IPC in a number of scenarios, and combine that with an increase in load/store resources is going to help more instructions get pushed through. The double L3 cache is going to help in specific workloads, as would the AVX2 single-op support, but the improved branch predictor is also going to showcase raw performance uplift. All-in-all, for an on-paper analysis, AMD’s +15% IPC improvement seems like a very reasonable number to promote.
Over the next few pages, we’ll go deeper into how the microarchitecture has changed.








216 Comments
View All Comments
JohnLook - Monday, June 10, 2019 - link
@Ian Cutress Are you sure the Io dies are on TSMC's 14 & 12 nm processes ?all info so far was that they were on GloFo's 14 nm ...
Ian Cutress - Monday, June 10, 2019 - link
Sorry, glofo 14 and 12. Matisse IO die is Glofo 12nm. We triple confirmed.JohnLook - Monday, June 10, 2019 - link
Thanks :-)scineram - Tuesday, June 11, 2019 - link
It still says Epyc is TSMC.John_M - Tuesday, June 11, 2019 - link
It would be nice if the article was updated as not everyone reads the comments section and AnandTech articles do often get cited in Wikipedia articles.Smell This - Wednesday, June 12, 2019 - link
I feel safe in saying that Wiki-Dom will be right on it . . .;-)
So __ those little white lines are the Infinity Scalable Data Fabric (SDF) and the Infinity Scalable Control Fabric (SCF), connecting "Core" chiplets to the I/O core.
"The SDF might have dozens of connecting points hooking together things such as PCIe PHYs, memory controllers, USB hub, and the various computing and execution units."
"The SDF is a superset of what was previously HyperTransport. The SCF is a complementary plane that handles the transmission ..."
https://en.wikichip.org/wiki/amd/infinity_fabric
Of course, I counted them (rolling eyes at myself), and determined there were 32 connecting a single core chiplet to the I/O core. I'm smelling a rational relationship between those 32, and other such stuff. Are the number of IF links a proprietary secret to AMD?
Yah know? It would be a nice 'get' if a tech writer interviewed someone in that former Sea Micro bunch, and spilled a few beans . . .
Smell This - Wednesday, June 12, 2019 - link
Might be 36 ... LOL
Smell This - Wednesday, June 12, 2019 - link
Could be 42- or 46 IF links on the right(I'll stop obsessing)
sweetca - Thursday, June 13, 2019 - link
I don't understand anything you said 🙂Smell This - Sunday, June 16, 2019 - link
I was (am) trolling Ian/AT for a **Deep(er) Dive** on the Infinity Fabric -- its past, and its future. The EPYC Rome processors have 8 "Core" chiplets connecting to the I/O core. Right? Those 'little white lines' (32- to 46?) from each chiplet, presumably, scale to ... infinity?AMD purchased SeaMicro 7 years ago as the "Freedom Fabric" platform was developed. Initially the SM15000 'stitched' together 512 compute cores, 160 gigabits of I/O networking and 5+ petabytes of storage to form a 'very-high-density server.'
And then . . . they went dark.
https://www.anandtech.com/show/9170/amd-exits-dens...
(see the last comment on that link)