The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra
SPEC - Single-Threaded Performance
Starting off with SPECint2017, we’re using the single-instance runs of the rate variants of the benchmarks.
As usual, because there are not officially submitted scores to SPEC, we’re labelling the results as “estimates” as per the SPEC rules and license.
We compile the binaries with GCC 10.2 on their respective platforms, with simple -Ofast optimisation flags and relevant architecture and machine tuning flags (-march/-mtune=Neoverse-n1 ; -march/-mtune=skylake-avx512 ; -march/-mtune=znver2).
While single-threaded performance in such large enterprise systems isn’t a very meaningful or relevant measure, given that the sockets will rarely ever be used with just 1 thread being loaded on them, it’s still an interesting figure academically, and for the few use-cases which would have such performance bottlenecks. It’s to be remembered that the EPYC and Xeon systems will clock up to respectively 3.4GHz and 4GHz under such situations, while the Ampere Altra still maintains its 3.3GHz maximum speed.
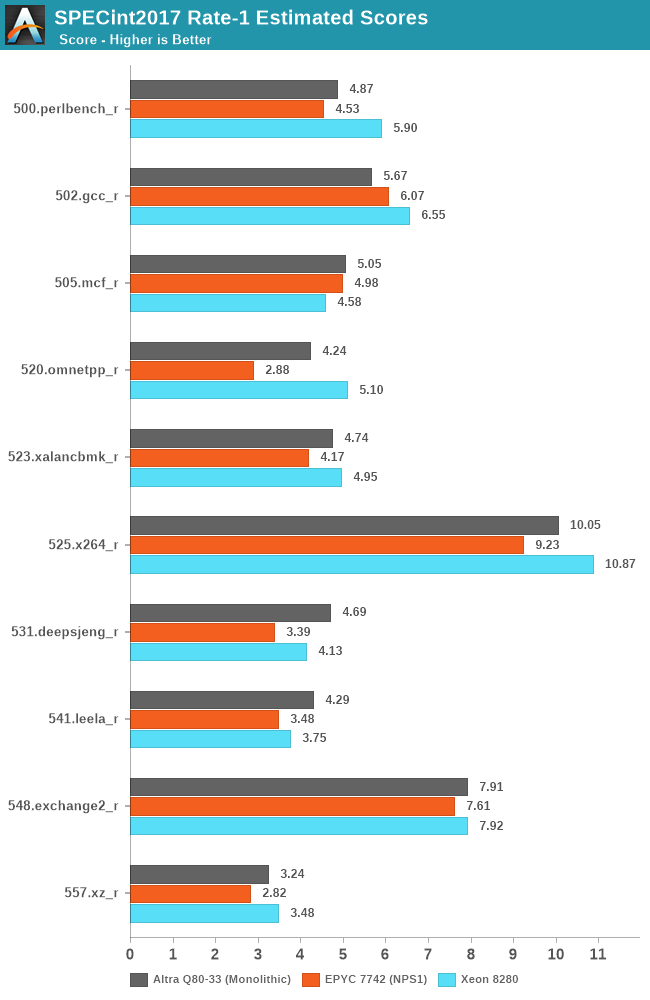
In SPECint2017, the Altra system is performing admirably and is able to generally match the performance of its counterparts, winning some workloads, while losing some others.
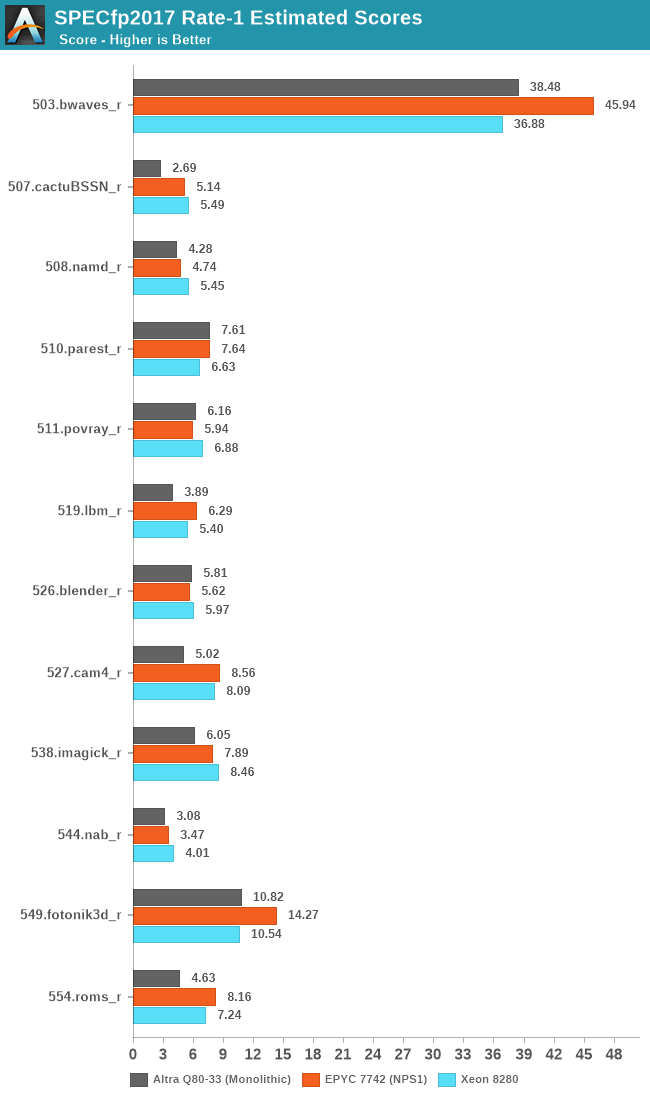
In SPECfp2017 the Neoverse-N1 cores seem to more generally fall behind their x86 counterparts. Particularly what’s odd to see is the vast discrepancy in 507.cactuBSSN_r where the Altra posts less than half the performance of the x86 cores. This is actually quite odd as the Graviton2 had scored 3.81 in the test. The workload has the highest L1D miss rate amongst the SPEC suite, so it’s possible that the neutered prefetchers on the Altra system might in some way play a more substantial role in this workload.
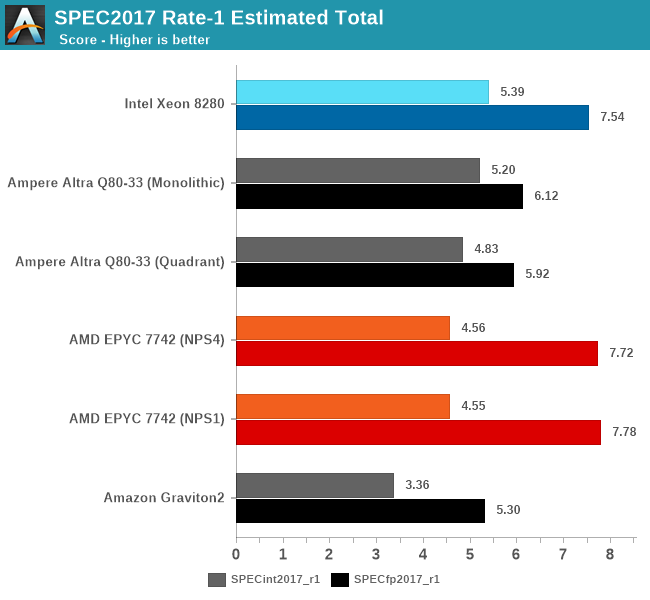
The Altra Q80-33 ends up performing extremely well and competitively against the AMD EPYC 7742 and Intel Xeon 8280, actually beating the EPYC in SPECint, although it loses by a larger margin in SPECfp. The Xeon 8280 still holds the crown here in this test due to its ability to boost up to 4GHz across two cores, clocking down to 3.8, 3.7, 3.5 and 3.3GHz beyond 2, 4, 8 and 20 cores active.
The Altra showcases a massive 52% performance lead over the Graviton2 in SPECint, which is actually beyond the expected 32% difference due to clock frequencies being at 3.3GHz versus 2.5GHz. On the other hand, the SPECfp figures are only ahead of 15% for the Altra. The prefetchers are really amongst the only thing that come to mind in regards to these differences, as the only other difference being that the Graviton2 figures were from earlier in the year on GCC 9.3. The Altra figures are definitely more reliable as we actually have our hands on the system here.
While on the AMD system the move from NPS1 to NPS4 hardly changes performance, limiting the Altra Q80-33 from a monolithic setup to a quadrant setup does incur a small performance penalty, which is unsurprising as we’re cutting the L3 into a quarter of its size for single-threaded workloads. That in itself is actually a very interesting experiment as we haven’t been able to do such a change on any prior system before.








148 Comments
View All Comments
realbabilu - Friday, December 18, 2020 - link
well it support fortran also using Arm Fortran Compiler, unlike m1.realbabilu - Friday, December 18, 2020 - link
my bad. Numerical Algorithms Group (Nag) has fortran for m1. lets battle begin X86 vs armGruenSein - Friday, December 18, 2020 - link
The userbase for fortran on M1 is probably super small anyway. Although.. I can see the HPC cluster entirely made up of Macbook Airs before my eye. Just like the PS3-cluster the air force used to have ;)davidorti - Friday, December 18, 2020 - link
Wouldn't it be way cheaper a cluster of minis?Flunk - Friday, December 18, 2020 - link
No, the hardware would be cheaper but the maintenance would be much more time-intensive. That's why companies that need a lot of processing hardware buy enterprise level hardware. The cost of maintaining the system quickly eclipses the hardware costs. And if you're using a computer to make money, quite often the hardware cost is only a small amount of your costs.FunBunny2 - Friday, December 18, 2020 - link
I dunno about the "quite often the hardware cost is only a small amount of your costs." part. as modern production methods have been ever more automated, (I'm talkin to you, bitcoin mining), there's almost no other cost. now, some may argue, in the extreme case of mining for instance, that power is the largest component; but isn't that 'hardware' cost? it certainly isn't labor or interest or land or even CxOs' cut. fewer and fewer automation efforts are conducted in assembler or even naked C or java or FORTRAN, but in frameworks, often with bespoke syntax and with headcounts way lower than their native languages. so, yeah, now into the foreseeable future, hardware is the biggest byte.at_clucks - Friday, December 18, 2020 - link
The point was a cluster of Minis would probably be cheaper than a cluster of Airs because why pay for screen, battery, keyboard and all that.Spunjji - Monday, December 21, 2020 - link
True, but I did enjoy the holistic response. Just think of the potential: batteries are a built-in UPS, and you don't need to mess about with any sort of KVM arrangement - if a node drops out, you can go right to it and poke it to find out what's up!ProDigit - Saturday, December 19, 2020 - link
I guess the results showing lower TDP despite 100% load, means that the cores are sometimes idling for a part of their clock frequency.It means the cpu is lacking buffers, and isn't fully optimized.
mode_13h - Sunday, December 20, 2020 - link
Buffers and even cache can't completely avoid memory bottlenecks.Also, you can run a core 100% on code with very little parallelism and not draw much power. Code with lots of ILP and especially vector arithmetic burns a lot more power, which is why AVX2 and especially AVX-512 trigger significant clock-throttling on Intel.