AMD EPYC Milan Review Part 2: Testing 8 to 64 Cores in a Production Platform
by Andrei Frumusanu on June 25, 2021 9:30 AM ESTSPECjbb MultiJVM - Java Performance
Moving on from SPECCPU, we shift over to SPECjbb2015. SPECjbb is a from ground-up developed benchmark that aims to cover both Java performance and server-like workloads, from the SPEC website:
“The SPECjbb2015 benchmark is based on the usage model of a worldwide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations. It exercises Java 7 and higher features, using the latest data formats (XML), communication using compression, and secure messaging.
Performance metrics are provided for both pure throughput and critical throughput under service-level agreements (SLAs), with response times ranging from 10 to 100 milliseconds.”
The important thing to note here is that the workload is of a transactional nature that mostly works on the data-plane, between different Java virtual machines, and thus threads.
We’re using the MultiJVM test method where as all the benchmark components, meaning controller, server and client virtual machines are running on the same physical machine.
The JVM runtime we’re using is OpenJDK 15 on both x86 and Arm platforms, although not exactly the same sub-version, but closest we could get:
EPYC & Xeon systems:
openjdk 15 2020-09-15
OpenJDK Runtime Environment (build 15+36-Ubuntu-1)
OpenJDK 64-Bit Server VM (build 15+36-Ubuntu-1, mixed mode, sharing)
Altra system:
openjdk 15.0.1 2020-10-20
OpenJDK Runtime Environment 20.9 (build 15.0.1+9)
OpenJDK 64-Bit Server VM 20.9 (build 15.0.1+9, mixed mode, sharing)
Furthermore, we’re configuring SPECjbb’s runtime settings with the following configurables:
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT -Dspecjbb.forkjoin.workers=N -Dspecjbb.forkjoin.workers.Tier1=N -Dspecjbb.forkjoin.workers.Tier2=1 -Dspecjbb.forkjoin.workers.Tier3=16"
Where N=160 for 2S Altra test runs, N=80 for 1S Altra test runs, N=112 for 2S Xeon 8280, N=56 for 1S Xeon 8280, and N=128 for 2S and 1S on the EPYC system. The 75F3 system had the worker count reduced to 64 and 32 for 2S/1S runs, with the 7443, 7343 and 72F3 also having the same thread to core ratiio.
The Xeon 8380 was running at N=140 for 2S Xeon 8380 and N=70 for 1S - the benchmark had been erroring out at higher thread counts.
In terms of JVM options, we’re limiting ourselves to bare-bone options to keep things simple and straightforward:
EPYC & Altra systems:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC "
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms48g -Xmx48g -Xmn42g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon Cascade Lake systems:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms172g -Xmx172g -Xmn156g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon Ice Lake systems (SNC1):
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms192g -Xmx192g -Xmn168g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon Ice Lake systems (SNC2):
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms96g -Xmx96g -Xmn84g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
The reason the Xeon CLX system is running a larger back-end heap is because we’re running a single NUMA node per socket, while for the Altra and EPYC we’re running four NUMA nodes per socket for maximised throughput, meaning for the 2S figures we have 8 backends running for the Altra and EPYC and 2 for the Xeon, and naturally half of those numbers for the 1S benchmarks.
For the Ice Lake system, I ran both SNC1 (one NUMA node) as SNC2 (two nodes), with the corresponding scaling in the back-end memory allocation.
The back-ends and transaction injectors are affinitised to their local NUMA node with numactl –cpunodebind and –membind, while the controller is called with –interleave=all.
The max-jOPS and critical-jOPS result figures are defined as follows:
"The max-jOPS is the last successful injection rate before the first failing injection rate where the reattempt also fails. For example, if during the RT-curve phase the injection rate of 80000 passes, but the next injection rate of 90000 fails on two successive attempts, then the max-jOPS would be 80000."
"The overall critical-jOPS is computed by taking the geomean of the individual critical-jOPS computed at these five SLA points, namely:
• Critical-jOPSoverall = Geo-mean of (critical-jOPS@ 10ms, 25ms, 50ms, 75ms and 100ms response time SLAs)
During the RT curve building phase the Transaction Injector measures the 99th percentile response times at each step level for all the requests (see section 9) that are considered in the metrics computations. It then computes the Critical-jOPS for each of the above five SLA points using the following formula:
(first * nOver + last * nUnder) / (nOver + nUnder) "
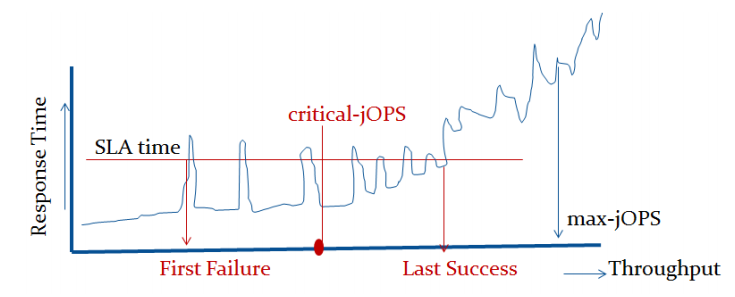
That’s a lot of technicalities to explain an admittedly complex benchmark, but the gist of it is that max-jOPS represents the maximum transaction throughput of a system until further requests fail, and critical-jOPS is an aggregate geomean transaction throughput within several levels of guaranteed response times, essentially different levels of quality of service.
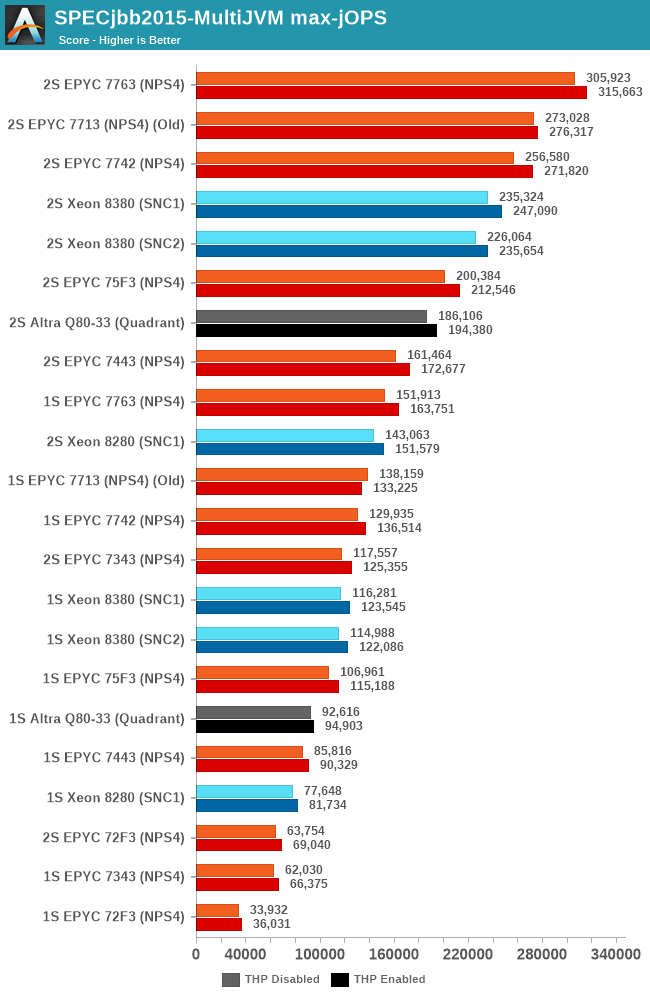
In the max-jOPS metric, the re-tested 7763 increases its throughput by 5%, while the 75F3 oddly enough didn’t see a notable increase.
The 7343 here doesn’t fare quite as well to the Intel competition as in prior tests, AMD’s high core-to-core latency is still a larger bottleneck in such transactional and database-like workloads compared to Intel’s monolithic mesh approach. Only the 7443 manages to have a slight edge over the 28-core Intel SKU.
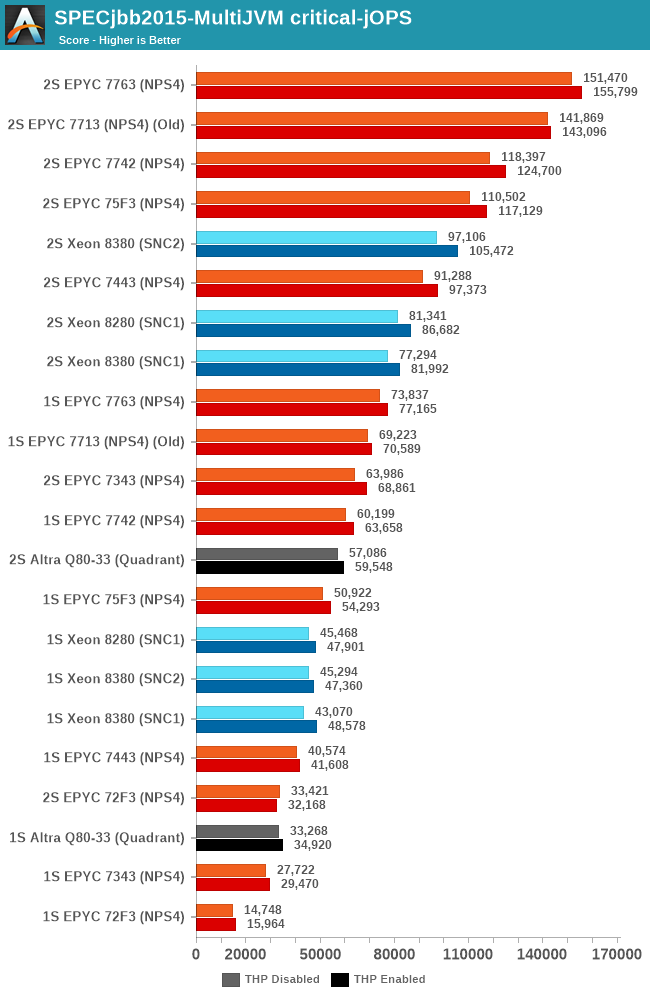
In the critical-jOPS metric, both the 16- and 24-core EPYCs lose out to the 28-core Xeon. Unfortunately we don’t have the Xeon 6330 numbers here due those chips and system being in a different location.








58 Comments
View All Comments
eastcoast_pete - Friday, June 25, 2021 - link
Interesting CPUs. Regarding the 72F3, the part for highest per-core performance: Dating myself here, but I recall working with an Oracle DB that was licensed/billed on a per-core or per-thread basis (forgot which one it was). Is that still the case, and what other programs (still) use that licensing approach?And, just to add perspective: the annual payments for that Oracle license dwarfed the price of the CPU it ran on, so yes, such processors can have their place.
flgt - Friday, June 25, 2021 - link
More workstation than server, but companies like Ansys still require additional license packs to go beyond 4 cores with some of their tools, and they often come with hefty 5-figure price tags depending on the program and your organizations bargaining ability.RollingCamel - Friday, June 25, 2021 - link
It was refreshing to see Midas NFX running without core limitations.The core limitations archaic and doesn't represent the current development. Unless the license policies has evolved in the past years.
realbabilu - Monday, June 28, 2021 - link
Interesting to see The fea implementation with latest math kernel available like midas nfx bench in anandtech. Hopefullly anandteam got demos from midas korea for testing. Abaqus, msc nastran, inventor fea anything will do.However i dont think midas improved their math kernel, i had midas civil and gts licensed, but cant use all threads and all memory i had On my pc, like others fea dis.
mrvco - Friday, June 25, 2021 - link
Power unit pricing! LOL, the dreaded Oracle audit when they needed to find a way to make their quarterly numbers!?!?!eek2121 - Friday, June 25, 2021 - link
It blows my mind that people still use Oracle products.Urbanfox - Sunday, June 27, 2021 - link
For a lot of things there isn't a viable alternative. The hotel industry is a great example of this with Opera and Micros.phr3dly - Friday, June 25, 2021 - link
In the EDA world we pay per-process licensing. As with your scenario, the license cost dwarfs the CPU cost, particularly over the 3-year lifespan of a server. You might easily spend 50x the cost of the server on the licenses, depending on the number of cores. Trying to optimize core speed/core count/eventual server load against license cost is a fun optimization problem.So yeah, the CPU cost is irrelevant. I'm happy to pay an extra several thousand dollars for a moderate performance improvement.
eldakka - Saturday, June 26, 2021 - link
> Oracle DB that was licensed/billed on a per-core or per-thread basis (forgot which one it was). Is that still the case, and what other programs (still) use that licensing approach?Lots of Enterprise applications still use that approach, Oracle (not just DB), IBM products - WebSphere Application Server (all flavours, standalone, ND, Liberty, etc.), messaging products like WebSphere MQ, I believe SAP uses it, many RedHat 'middleware' products (e.g. JBOSS web server, EAS, etc.) use it as well.
In the enterprise space, it is basically the expected licensing model.
And the licensing cost per-core is usually 'generation' dependant. So you usually just can't upgrade from, say, a 20-core Xeon 6th-gen to a 20-core 8th gen and expect to pay the same.
The typical model is a 'PVU', Processor Value Unit (different companies may give it a different label - and value different processors differently, but it usually boils down to the same thing). Each platform-generation (as decided by the software vendor, i.e. Oracle, or IBM, etc.) has a certain PVU per core. E.g., (making up numbers here) a POWER8 (2014ish release) might have a PVU of 4000, and an Intel Haswell/Ivy Bridge - E5/7 v2/3 I think (2014/15ish)- might be given 3500. So if using an 8-core P8 LPAR that'd be 32000 PVU, while an 8 core VI on E7 v3 would be 28000. And P9 might be 7000 PVU, a Milan might be 6000 PVU, so for 8-cores it'd be 56000 or 48000 respectively. Then there will be a doller per PVU multiplier based on the software, so software bob could be x1 per year, so in the P9 case $56k/year license, whereas software fred mught be a x4 multiplier, so $224k/year. And yes, there can be instances where software being run on a single server (not even necessarily a beefy server) can be $millions/year licensing. If some piece of software is critical, but low CPU/memory requirements, such as an API-layer running on x86 hardware that allows midrange-based apps to interface directly to mainframe apps, they can charge millions for it even if its only using combined 8-cores across 4 2-core server instances (for HA) - though in this case, where they know it requires tiny resources, they'll switch to a per-instance rather than a per-core pricing model, and charge $500k per instance for example.
The per-core PVU can even change within a generation depending on specific CPU feature sets, e.g. the 2TB per-socket limited Xeon might be 5000 PVU, but the 4TB per-socket SKU of the same generation might be 6000 PVU, just because the vendor thinks "they need lots of memory, therefore they are working on big data sets, well, obviously, that's more money!" they want their tithe.
Oh, and nearly forgot to mention, the PVU can even change depending on whether the software vendor is tring to push their own hardware. IBM might give a 'PVU' discount if you run their IBM products on IBM Power hardware versus another vendors hardware, to try and push Power sales. So even though, in theory, a P9 might be more PVU than a Xeon, but since you are running IBM DB2 on the P9, they'll charge you less money for what is conceptually a higher PVU than on say a Xeon, to nudge you towards IBM hardware. Oracle has been known to do this with their aquired SPARC (Sun)-based hardware too.
eastcoast_pete - Saturday, June 26, 2021 - link
Thanks! I must say that I am glad I don't have to deal with that aspect of computing anymore. I also wonder if people have analyzed just how severely these pricing schemes have blunted or prevented advancements in hardware capabilities?