The Ampere Altra Max Review: Pushing it to 128 Cores per Socket
by Andrei Frumusanu on October 7, 2021 8:00 AM EST- Posted in
- Servers
- Arm
- Neoverse N1
- Ampere
- Altra Max
SPECjbb MultiJVM - Java Performance
Moving on from SPECCPU, we shift over to SPECjbb2015. SPECjbb is a from ground-up developed benchmark that aims to cover both Java performance and server-like workloads, from the SPEC website:
“The SPECjbb2015 benchmark is based on the usage model of a worldwide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations. It exercises Java 7 and higher features, using the latest data formats (XML), communication using compression, and secure messaging.
Performance metrics are provided for both pure throughput and critical throughput under service-level agreements (SLAs), with response times ranging from 10 to 100 milliseconds.”
The important thing to note here is that the workload is of a transactional nature that mostly works on the data-plane, between different Java virtual machines, and thus threads.
We’re using the MultiJVM test method where as all the benchmark components, meaning controller, server and client virtual machines are running on the same physical machine.
The JVM runtime we’re using is OpenJDK 15 on both x86 and Arm platforms, although not exactly the same sub-version, but closest we could get:
EPYC & Xeon systems:
openjdk 15 2020-09-15
OpenJDK Runtime Environment (build 15+36-Ubuntu-1)
OpenJDK 64-Bit Server VM (build 15+36-Ubuntu-1, mixed mode, sharing)
Altra system:
openjdk 15.0.1 2020-10-20
OpenJDK Runtime Environment 20.9 (build 15.0.1+9)
OpenJDK 64-Bit Server VM 20.9 (build 15.0.1+9, mixed mode, sharing)
Furthermore, we’re configuring SPECjbb’s runtime settings with the following configurables:
SPEC_OPTS_C="-Dspecjbb.group.count=$GROUP_COUNT -Dspecjbb.txi.pergroup.count=$TI_JVM_COUNT -Dspecjbb.forkjoin.workers=N -Dspecjbb.forkjoin.workers.Tier1=N -Dspecjbb.forkjoin.workers.Tier2=1 -Dspecjbb.forkjoin.workers.Tier3=16"
Where N=160 for 2S Altra test runs, N=128 for 1S Altra Max runs, N=80 for 1S Altra test runs, N=112 for 2S Xeon 8280, N=56 for 1S Xeon 8280, and N=128 for 2S and 1S on the EPYC system. The 75F3 system had the worker count reduced to 64 and 32 for 2S/1S runs, with the 7443, 7343 and 72F3 also having the same thread to core ratiio. The Xeon 8380 was running at N=140 for 2S Xeon 8380 and N=70 for 1S - the benchmark had been erroring out at higher thread counts.
In terms of JVM options, we’re limiting ourselves to bare-bone options to keep things simple and straightforward:
EPYC systems:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC "
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms48g -Xmx48g -Xmn42g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon Cascade Lake systems:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms172g -Xmx172g -Xmn156g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon Ice Lake (SNC1) & Altra systems:
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms192g -Xmx192g -Xmn168g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
Xeon Ice Lake systems (SNC2):
JAVA_OPTS_C="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_TI="-server -Xms2g -Xmx2g -Xmn1536m -XX:+UseParallelGC"
JAVA_OPTS_BE="-server -Xms96g -Xmx96g -Xmn84g -XX:+UseParallelGC -XX:+AlwaysPreTouch"
The reason the Xeon CLX system is running a larger back-end heap is because we’re running a single NUMA node per socket, while for the Altra and EPYC we’re running four NUMA nodes per socket for maximised throughput, meaning for the 2S figures we have 8 backends running for the Altra and EPYC and 2 for the Xeon, and naturally half of those numbers for the 1S benchmarks.
For the Ice Lake system, I ran both SNC1 (one NUMA node) as SNC2 (two nodes), with the corresponding scaling in the back-end memory allocation.
The back-ends and transaction injectors are affinitised to their local NUMA node with numactl –cpunodebind and –membind, while the controller is called with –interleave=all.
The max-jOPS and critical-jOPS result figures are defined as follows:
"The max-jOPS is the last successful injection rate before the first failing injection rate where the reattempt also fails. For example, if during the RT-curve phase the injection rate of 80000 passes, but the next injection rate of 90000 fails on two successive attempts, then the max-jOPS would be 80000."
"The overall critical-jOPS is computed by taking the geomean of the individual critical-jOPS computed at these five SLA points, namely:
• Critical-jOPSoverall = Geo-mean of (critical-jOPS@ 10ms, 25ms, 50ms, 75ms and 100ms response time SLAs)
During the RT curve building phase the Transaction Injector measures the 99th percentile response times at each step level for all the requests (see section 9) that are considered in the metrics computations. It then computes the Critical-jOPS for each of the above five SLA points using the following formula:
(first * nOver + last * nUnder) / (nOver + nUnder) "
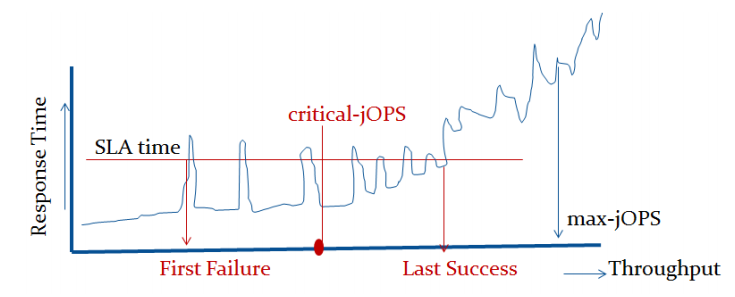
That’s a lot of technicalities to explain an admittedly complex benchmark, but the gist of it is that max-jOPS represents the maximum transaction throughput of a system until further requests fail, and critical-jOPS is an aggregate geomean transaction throughput within several levels of guaranteed response times, essentially different levels of quality of service.
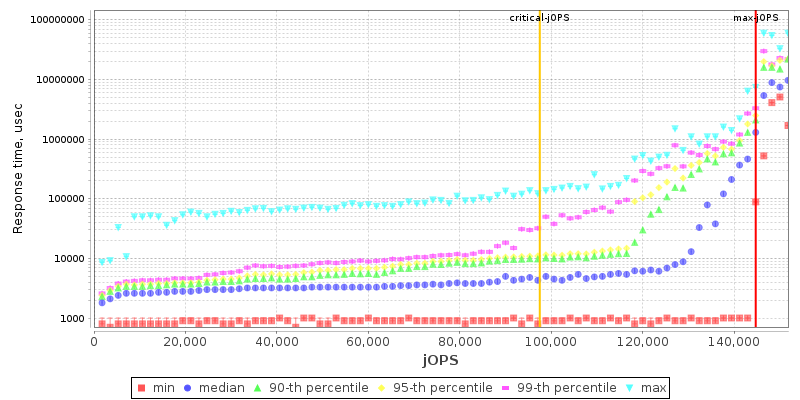
On the SLA graph with the response times across increasing load, we see the Altra Max not differ too much from its predecessor, though it’s simply showcasing improved performance.
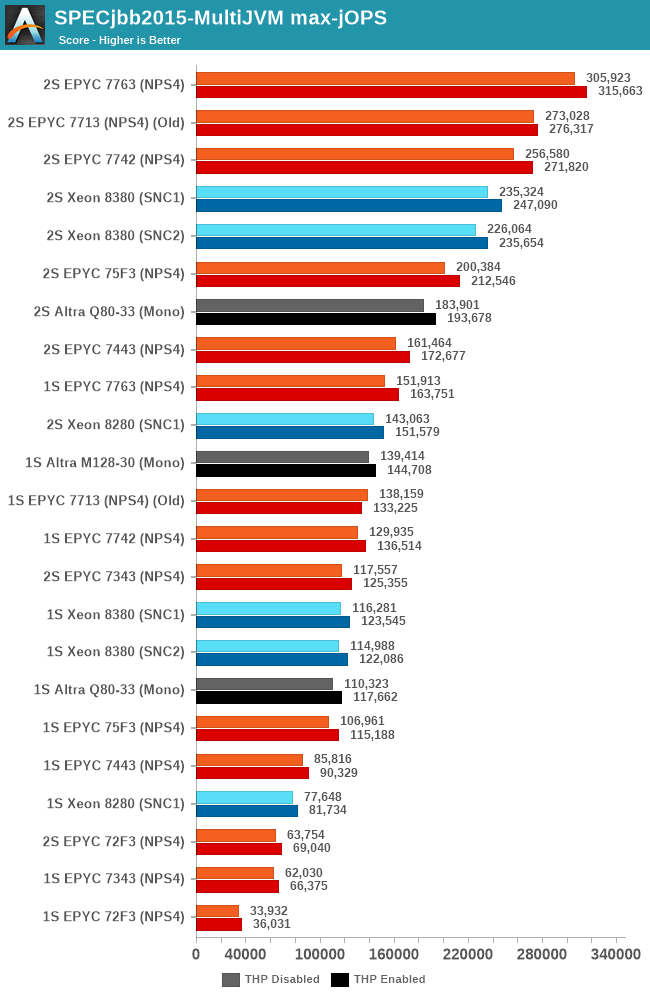
In our initial review of the Q80-33 last year, we had noted that the chip offered lacklustre performance metrics in the SPECjbb benchmark, and though this was somehow attributed to Java performance on AArch64. After spending some more time trying to debug the issue prior to this review, I surprisingly found out that the issue, at least in our configuration, was due to the Altra chip’s operating mode. While we first had tested the chip in quadrant mode, where the chip is partitioned in respective four NUMA nodes, and running four SPECjbb back-ends (one per NUMA node). Running the chip in monolithic mode as an experiment, surprisingly resolved all our performance issues with SPECjbb, with the Q80-33 now running in line where Arm had expected the system to land, which meant increase in the max-jOPS metric and a more massive increase in the critical-jOPS metric as we’ll see in a bit. Unfortunately, trading in one issue with another, we ran into other issues on the 2-socket test scenario where the test ran into issues at large thread counts. The 2S Q80-33 figures here only stresses 130 cores, while I wasn’t able at all to get 2S M128-30 figures at reasonable core counts, so I completely omitted results here.
Focusing on the 1-socket results instead, both the Q80-33 and the new M128-30 now showcase much better performance than what we had seen in the first review of the Altra. The new M128-30 sees a +26% boost in peak throughput performance compared to the Q80-33, however, the chip still lags behind AMD’s flagship EPYC 7763.
The Altra Max here not only is able to increase performance through more cores, but it’s also just outright able to make more usage of its system TDP of 250W. The workload being more data-plane bound, which is also the reason it scales well with SMT, had the effect that the 80-cores on the Q80-33 were running at lower execution resources and lower power, averaging at ~180W, quite below the 250W TDP. The per-core utilisation doesn’t change on the M128-30, but throwing more cores at the matter does help saturate more of the available TDP and result in more performance.
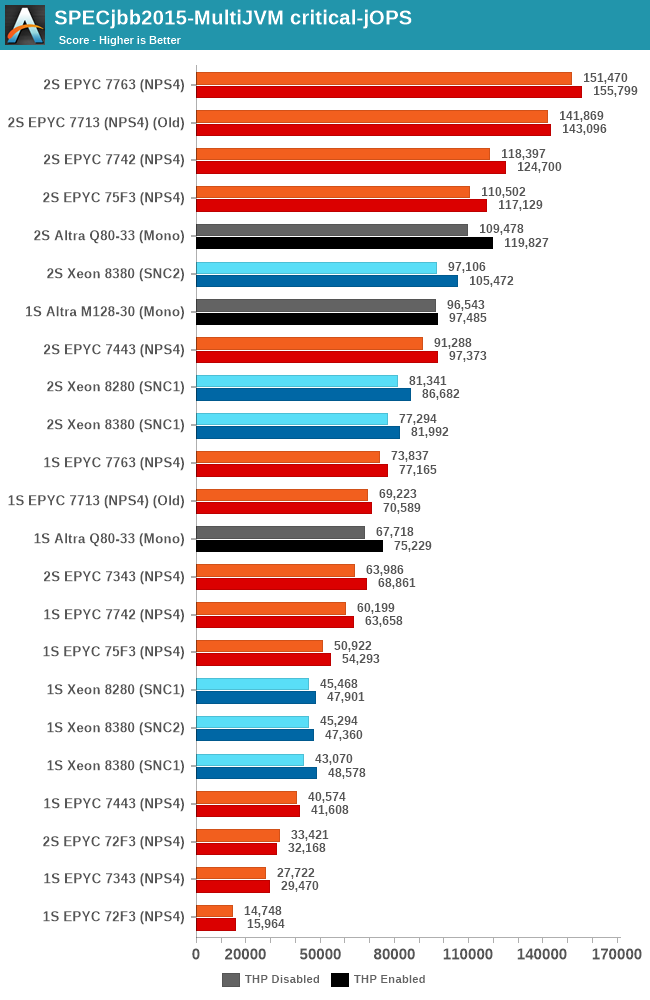
The new critical-jOPS figures for this review are massively improved, with the Q80-33 now posting double that of what we had originally measured. The new M128-30 now further pushes this up, reaching an impressive figure of 96k-jOPS, significantly above the second-best CPU which is the EPYC 7763 at 73k. These new results are much more in line with what we had expected of a single large monolithic CPU design, and showcases the Altra Max in its best possible light and what Ampere tries to focus on – better performance predictability than what the competition can offer with SMT.
We’ll continue to try to figure out what’s happening with the system in the dual-socket scenarios – it’s possible we’re hitting some sort of inherent scaling issue with SPECjbb at these massive thread counts.








60 Comments
View All Comments
Jurgen B - Thursday, October 7, 2021 - link
Love your thorough article and testing. This is some serious firing power from the Ampere and makes some great competition for Intel and AMD. I really like the 256T runs on the AMD Dual socket EPYCs (they really are serving me well in floating point research computing), but it seems that future holds some nice innovations in the field!mode_13h - Thursday, October 7, 2021 - link
Lack of cache seems to be a serious liability, though. For many, it'll be a deal breaker.Wilco1 - Friday, October 8, 2021 - link
Yet it still beats AMD's 7763 with its humongous 256MB L3 in all the multithreaded benchmarks. Sure, it would be even faster if it had a 64MB L3 cache, however it doesn't appear to be a serious liability. Doing more with far less silicon at a lower price (and power) is an interesting design point (and apparently one that cloud companies asked for).Jurgen B - Friday, October 8, 2021 - link
Yes, Cache will play a role for many. However, people buying such servers likely have a very specific workload in mind. And thus they now have more choices which of the manufacturer options they prefer, and these choices are really good to see. Compared to 10 years ago, when AMD was much less competitive, it is wonderful to see the innovation.schujj07 - Friday, October 8, 2021 - link
That isn't true at all. The SPEC java benchmarks have the Epyc ahead, SpecINT Base Rate-N Estimated they are almost equal (despite having half the cores), FP Base Rate-N Estimated the Epyc is ahead, compiling the Epyc is ahead. Anything that will tax the memory subsystem by not fitting into the small cache of the Altra and the performance is lower for the Altera. Per core performance isn't even close.mode_13h - Saturday, October 9, 2021 - link
Thanks for correcting the record, @schujj07.The whole concept of adding 60% more cores while halving cache is mighty suspicious. In the most charitable view, this is intended to micro-target specific applications with low memory bandwidth requirements. From a more cynical perspective, it's merely an exercise in specsmanship and maybe trying to gin up a few specific benchmark numbers.
Wilco1 - Saturday, October 9, 2021 - link
If you're that cynical one could equally claim that adding *more* cache is mighty suspicious and gaming benchmark numbers. Obviously nobody would spend a few hundred million on a chip just to game benchmarks. The fact is there is a market for chips with lots of cores. Half the SPEC subtests show huge gains from 60% extra cores despite the lower frequency and halved L3. So clearly there are lots of applications that benefit from more cores and don't need a huge L3.Wilco1 - Saturday, October 9, 2021 - link
The Altra Max wins the more useful critical-jOPS benchmark by over 30%. It also wins the LLVM compile test and SPECINT_rate by a few percent. The 7763 only wins SPECFP by 18% (not Altra's market) and max-jOPS by 13%.So yes my point is spot on, the small cache does not look at all like a serious liability. Per-core performance isn't interesting when comparing a huge SMT core with a tiny non-SMT core - you can simply double the number of cores to make up for SMT and still use half the area...
mode_13h - Saturday, October 9, 2021 - link
> Per-core performance isn't interesting when comparing ...Trying to change the subject? We didn't mention that. We were talking only about cache.
> The Altra Max wins the more useful critical-jOPS benchmark by over 30%.
That's really about QoS, which is a different story. Surely, relevant for some. I wonder if x86 CPUs would do better on that front with SMT disabled.
> the small cache does not look at all like a serious liability.
Of course it's a liability! It's just a very workload-dependent one. You need only note the cases where Max significantly underperforms, relative to its 80-core sibling, to see where the cache reduction is likely an issue.
The reason why there are so many different benchmarks is that you can't just seize on the aggregate numbers to tell the whole story.
mode_13h - Saturday, October 9, 2021 - link
Apologies, I now see where schujj07 mentioned per-core performance. I even searched for "per-core" but not "per core".