Intel Xeon 7460: Six Cores to Bulldoze Opteron
by Johan De Gelas on September 23, 2008 12:00 AM EST- Posted in
- IT Computing
ESX 3.5 Update 2 Virtualization Results
Disclaimer: Do not try to interpret these results if you are in a hurry!
We apologize for this warning to our astute readers, for whom it will be obvious that you cannot simply take the following graphs at face value. Unfortunately, many people tend to skip the text and just look at the pictures, which could lead to many misinterpretations. We want to make it clear that when you combine three different software layers - Hypervisor, OS or "Supervisor", and Server Application - on top of different hardware, things get very complex.
In our very first virtualization benchmark, we give each VM four virtual CPUs. With two and four VMs, we do not "oversubscribe", i.e. each virtual CPUs corresponds at least one physical CPU. In the case of six VMs, we oversubscribe some of the servers: the Xeon 73xx (Tigerton) and Opteron (Barcelona) platforms only have 16 physical CPUs, and we allocate 24. Oversubscribing is a normal practice in the virtualization world: you try to cut your costs by putting as many servers as is practical on one physical server. It's rare that all your servers are running at 100% load simultaneously, so you allow one VM to use some of the CPU power that another VM is not currently using. That is the beauty of virtualization consolidation after all: making the best use of the resources available.
The virtual CPUs are not locked to physical cores; we let the hypervisor decide which virtual CPU corresponds to which physical CPU. There is one exception: we enable NUMA support for the Opteron of course. For now, we limit ourselves to six VMs as several non-CPU related (probably storage) bottlenecks kick in as we go higher. We are looking at how we can test with more VMs, but this will require additional research.
This limit is a perfect example for understanding how complex virtualization testing can get. We could disable flushing the logs immediately after commit, as this would reduce the stress on our disk system,and make it a more CPU limited benchmark even with more than six VMs. However, this would mean that our test loses ACID compliance, which is important for an OLTP test. In a native test, this may be acceptable if you are just looking to test the CPU performance; it's probably just a matter of adding a few more spindles. However, this kind of reasoning is wrong when you work with virtualized servers. By disabling the immediate flushing of logs, you are lowering the impact on the hypervisor in several ways. Your hypervisor has to do less work, hence the impact on the CPU is lowered, and the objective of this test is to see how well a CPU copes with a virtualized environment.
Consolidation courtesy of virtualization is a compromise between performance per VM and total throughput of the physical machine. You want to put as many virtual servers as possible on one physical server to maximize throughput and cost reduction, but you do not want to see individual VM performance decrease below a certain threshold. If you sacrifice too much individual virtual server performance in order to get more VMs on one server, your CFO will be happy but your users will complain. It is therefore important to look at both the performance per virtual server and total throughput of the physical machine. The first graph shows you the number of transactions per Virtual Server. For those interested, this is an average and individual virtual servers show +/-5% compared to this average.
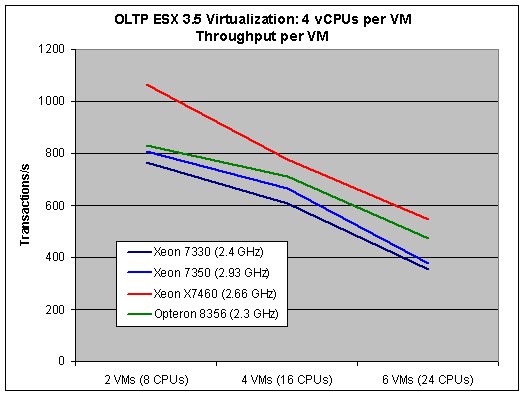
As expected, the highest result per virtual server is achieved if we only run two VMs. That is normal, since it means that the physical server has eight CPUs left to handle the console and hypervisor overhead. Nevertheless, those two factors cannot explain why our results fall so much once we activate four VMs and all 16 CPUs cores are busy.
| Performance loss from 2 VMs to 4 VMs | |
| Xeon 7330 (2.4GHz) | -21% |
| Xeon 7350 (2.93GHz) | -17% |
| Xeon X7460 (2.66GHz) | -27% |
| Opteron 8356 (2.3GHz) | -15% |
Our internal tests show that you should expect the Hypervisor to require about 12% of the CPU power per VM and the impact of the console should be minimal. In the first test (two VMs) there is more than enough CPU power available as we use only half (Opteron 8356, Xeon 73xx servers) to one third (X7460 server) of what is available. The real performance losses however are in the range of 15% (Opteron) to 27% (Xeon X7460). So where is the other bottleneck?
The database is 258MB per VM, and therefore runs almost completely in our INNODB buffer pool. We suspect the extra performance comes from the extra bandwidth that two extra VMs demand. Notice how the Opteron - the server with the highest bandwidth - has the lowest loss. That gives us our first hint, as we know that more VMs also result in higher bandwidth demands. Secondly, we see that the Xeon X7350 loses a little less than the E7330 (percentagewise) when you fire up two extra VMs. The slightly bigger cache on the X7350 (2x4MB) reduces the pressure on the memory a bit.
Next, we compare the architectures. To do this, we standardize the Xeon E7330 (2.4GHz) result to 100%.
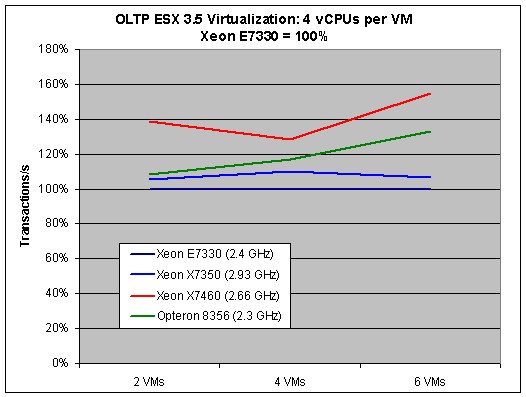
This graph is worth a very close investigation, since we can study the impact of the CPU core architecture. As we are using only eight CPUs and 4GB if we run two VMs, the Xeon 7460 cannot leverage its most visible advantage: the two extra cores. With two VMs, performance is mostly determined - in order of importance - by:
- (Futex) Thread synchronization (we have up to 32 threads working on the database per VM)
- Raw integer crunching power
- VM to Hypervisor switching time (to a lesser degree)
The X7460 is based on the Penryn architecture. This 45nm Intel core features slightly improved integer performance but also significantly improved "VM to Hypervisor" switching time. On top of that, synchronization between CPUs is a lot faster in the X74xx series thanks to the large inclusive L3 cache that acts as filter. Memory latency is probably great too, as the VMs are probably running entirely in the L2 and L3 caches. That is the most likely reason why we see the X7460 outperform all other CPUs.
Once we add two more VMs, we add 4GB and eight CPUs that the hypervisor has to manage. Memory management and latency become more important, and the Opteron advantages come into play: the huge TLB ensures that TLB misses happen a lot less. The TLB is also tagged, making sure "VM to Hypervisor" switching does not cause any unnecessary TLB flushes. As we pointed out before, the complex TLB of the Barcelona core - once the cause of a PR nightmare - now returns to make the server platform shine. We measured that NPT makes about a 7-8% difference here. That might not seem impressive at first sight, but a single feature capable of boosting the performance by such a large percentage is rare. The result is that the Opteron starts to catch up with the Xeon 74xx and outperforms the older 65nm Xeons.
The impact of memory management only gets worse as we add two more VMs. The advantages described above allow the Opteron to really pull away from the old Xeon 73xx generation. However, in this case the Xeon X7460 can leverage its eight remaining cores, while the Opteron and older Xeon servers do not have that luxury. The hypervisor has to juggle six VMs that are demanding 24 cores, while there are only 16 cores available on the Opteron and Xeon 73xx servers. That is why in this case the Xeon X7460 is again the winner here: it can consolidate more servers at a given performance point than the rest of the pack.
To appreciate what the 6-core Xeon is doing, we need to look at the total throughput.
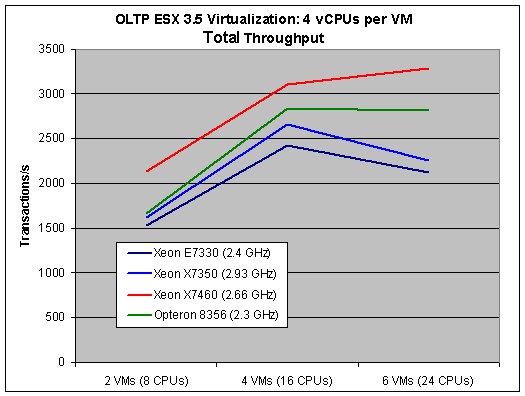
Notice how the Opteron is able to keep performance more or less stable once you demand 24 virtual CPUs, while the performance of Xeon 73xx takes a nosedive. The winner is of course the Intel hex-core, which can offer 24 real cores to the hypervisor. The Dunnington machine is capable of performing almost 3300 transactions per second, or no less than 45% more than its older brother that is clocked 11% higher. The Opteron does remarkably well with more than 2800 transactions per second, or about 24% better than the Xeon that has twice the cache and a 27% better clock speed (X7350 at 2.93GHz).








34 Comments
View All Comments
duploxxx - Thursday, November 13, 2008 - link
your virtualisation life was very short, perhaps marketing can keep you alive for a while since on paper you are better with the amount of cores.your 24 cores @2,66ghz are just killed by 16cores @2,7ghz
http://www.vmware.com/products/vmmark/results.html">http://www.vmware.com/products/vmmark/results.html
synergyek - Wednesday, October 15, 2008 - link
Why only testing scanline render? It's a slow and old monster. Can you add mental ray render to your tests or, maybe, vray, which is used in arch. visualizations? Also you can use Maya 32/64-bit (software, hardware, mental ray tests) for both windows and linux platforms. Mental ray on Vray uses all cores available in the system, and results must be much better, than ordinary scanline.duploxxx - Saturday, September 27, 2008 - link
Nice article, altough in virtualisation with VMmark it was already clear that the new dunnington had more headroom with the additional cores.only few remark, since you are talking about a retail price of +25000euro you could at least add for information that there are 8socket barcelona for about 5000euro more that scale again way better then dunnington with its 32 cores. So indeed intel did a step up again after there tigertown was heavy beaten by new barcelona in 4s even in low speed but at a certain cost of platform, afterall this dunnington is not cheap. it will be the question what a 4s shangai @3.0 ghz will do against this 6 core giant, afterall it is a huge die and the shangai will be way cheaper and consume less.
lets hope you update this nice article with the soon to be released shangai.
Sirlach - Friday, September 26, 2008 - link
From my research when the hex cores were announced the super micro boards came with an x16 slot. Is it possible to see how CPU restricted multithreaded games perform on this monster? Since it is running server 2008 this is theoretically possible!BaronMatrix - Thursday, September 25, 2008 - link
It seems like a better comparison would be with the number of cores the same. You could take a 4S and remove one chip and match that against a 2S Dunnington.From what I saw, it is nowhere near 50% faster though it has 50% more cores plus 4 times the cache. It looks like Intel may NEVER catch up with Opteron. Shanghai will just increase the difference.
It's just a shame Hector decided to have a "devalue the brand name" fire-sale or we'd be much closer to Bulldozer and SSE5.
trivik12 - Thursday, September 25, 2008 - link
4S has been one market where AMD dominated even after conroe's release. With Tigerton intel chipped away AMD's market share bcos of barcelona issues. with Dunnington Intel has a performance advantage. U dont look at per core performance but overall platform performance. AMD needs to catch up soon bcos with beckton AMD will be behind 8th ball in that market as well.snakeoil - Wednesday, September 24, 2008 - link
intel is cannibalizing nehalem this are desperate measures from a desperate man.this is a dead end road, sooner or later intel will have to dump the front side bus,but its evident that intel is not very confident about nehalem and quick path.
these processor are the last kick of an agonizing technology.
this is just a souped up old car. nothing more.
kingmouf - Wednesday, September 24, 2008 - link
Although a good thing for testing, I'm wondering if by making artificially the VMs more processing intensive rather than memory intensive, one is getting a quite wrong idea of the power consumption between the Intel and the AMD systems.Off-chip activity (coming from signal amplifiers, sensors, external buses etc) results in great power consumption. Actually one should expect it to be a crucial part of the total consumption of a system. In this case, I believe the AMD system has an advantage with the memory controller being incorporated in the processor chip. To one extend this also becomes clear in your testing.
Comparing the Intel CPUs one may observe that the 6-core part has a huge cache memory that seriously limits the main memory accesses. In the case of the 6VMs, there will also be reduced inter-socket communication. Both result in very serious reductions in off-chip activity, which materialises in a whopping 25% reduction in power usage.
Therefore I believe that making the benchmarking process more memory intensive, as you point is the real-world scenario, AMD could earn quite a few points there.
On a more general argument now, I can't stop thinking that chips like the 74xx Xeons are somewhat a waste of transistors. Intel is simply following the "bully" path rather than the "smart" path. I cannot stop thinking what would the results look like if instead of the two extra cores and the huge amount of cache, Intel added a TCP offload engine, a true hardware RAID controller, a block cipher accelerator, a DSP engine or an extra FP processor core (I'm not mentioning a memory controller because someone will pop up and say that they have already done that in the nehalem). All these things - and one could add much more - are integral to any server or HPC system and I believe can offer much more countable results than the two extra cores. Better performance and definitely better power usage. On the other hand, considering the weaknesses of AMD, maybe that is the company that should really get down to it.
Not long there was a lot of hype of AMD opening up their socket and coherent HyperTransport so that people could actually produce accelerators. What has happened with that? Are there any products on that market? It would be interesting to see some benchmarking with these things. :)
JohanAnandtech - Thursday, September 25, 2008 - link
"Im wondering if by making artificially the VMs more processing intensive rather than memory intensive, one is getting a quite wrong idea of the power consumption between the Intel and the AMD systems. "You are right that most virtualized workloads (including the OLTP ones) will need a lot more memory *space*, but they are not necessarily more memory intensive. It is good practice for example to use another scheduler to make it more CPU intensive: you are getting more transactions per second on the same machine. It is pretty bad to lose your watts on anything else but transactions.
jedz - Wednesday, September 24, 2008 - link
It's pretty obvious that AMD is not competing neck to neck in the server arena with their current opteron offerings because of the fact that they are way behind Intel's, and it's not right to compare the opteron to an intel7460 in terms of performance/watt. Why don't you wait for AMD's Shanghai and then redo this benchmarking process.Maybe it will do justice for AMD....