Expensive Quad Sockets vs. Ubiquitous Dual Sockets
by Johan De Gelas on October 6, 2009 1:00 AM EST- Posted in
- IT Computing
vApus Mark I: Performance-Critical applications virtualized
You might remember from our previous article that the vApus Mark I, our in-house developed virtualization benchmark, is designed to measure the performance of "heavy" performance-critical applications. Virtualization vendors are very actively promoting that you should virtualize these OLTP and heavy websites too, so that you can let the virtualization software dynamically manage them. In other words, if you want high-availability, load balancing, and low power (by shutting down servers which are not used), everything should be virtualized.
That is where vApus Mark I comes in: one OLAP, one DSS, and two heavy websites are combined in one tile. These are the kind of demanding applications that still received their own dedicated and natively running machine a year ago. vApus Mark I shows what will happen if you virtualize them. If you want to fully understand our benchmark methodology, vApus Mark I has been described in great detail here. We enabled large pages as it is generally considered a best practice with AMD's RVI and Intel's EPT.
vApus Mark I uses four VMs with four server applications:
- An SQL Server 2008 x64 database running on Windows 2008 64-bit, stress tested by our in-house developed vApus test.
- Two heavy duty MCS eFMS portals running PHP, IIS on Windows 2003 R2, stress tested by our in-house developed vApus test.
- One OLTP database, based on Oracle 10G Calling Circle benchmark of Dominic Giles.
The beauty is that vApus (stress testing software developed by the Sizing Servers Lab) uses actions made by real people (as can be seen in logs) to stress test the VMs, not some benchmarking algorithm.
To make things more interesting, we enabled and disabled HT-assist on the quad Opteron 8435 platform. HT-assist (described here in detail) steals 1MB from the L3 cache, reducing the size of the L3 cache to 5MB. The 1MB of cache is used as a very fast directory which eliminates a lot of snoop traffic. Eliminating snoop traffic reduces the "bandwidth pressure" on the CPU interconnects (hence the name HyperTransport Assist), but more importantly it reduces the latency of a cache request.

Thanks to HT Assist, the 24 Opteron cores communicate and perform about 9% faster. That is not huge, but it widens the gap with the dual Xeon somewhat. The dual Xeon X5570 keeps up with the much more expensive quad socket Intel server: eight cores are just as fast as 24.
Two tiles, 4 VMs and 4 vCPUs per VM: a total of 32 vCPUs are active in the previous test. 32 vCPUs are harder to schedule on a hex-core CPU, and especially on 24 cores in total. So let us see what happens if we reduce the total amount of vCPUs to 24 vCPUs.
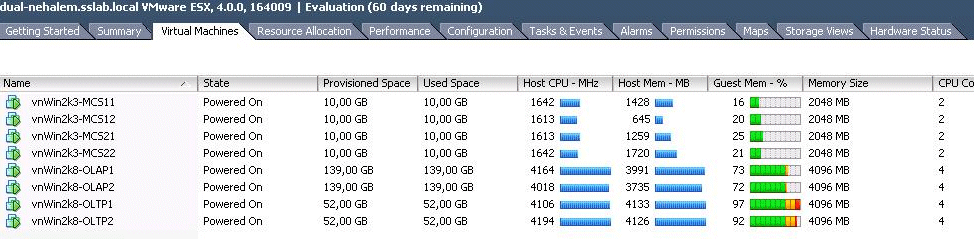 |
8 VMs, 2 tiles of vApus Mark I, 24 vCPUs
We reduced the number of vCPUs on the web portal VMs from 4 to 2. That means that we have:
- Two times 4 vCPUs for the OLAP test
- Two times 4 vCPUs for the OLTP test
- Two times 2 vCPUs for the web test
That makes a total of 24 vCPUs. The 32 vCPU test is somewhat biased towards the quad-core CPUs such as the Xeon X5570 while the test below favors the hex-cores.
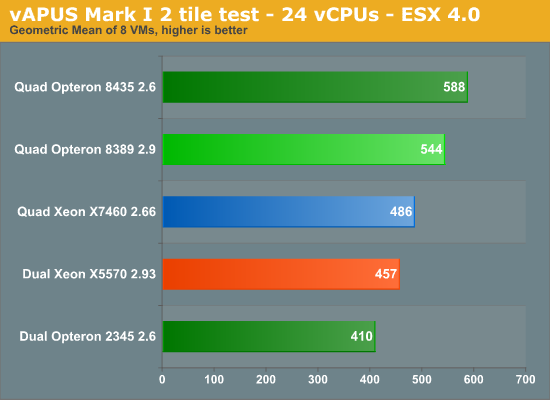
The "Dunnington" platform beats the 16 thread, 8 core Nehalem server but it is nothing to write home about: the 24 core machine outperforms Intel's latest dual socket by 6%. The advantage of the Opteron 8435 compared to the Xeon X7460 shrinks from 28 to 21%, but that is still a tangible performance advantage. Our understanding of virtualization performance is growing. Take a look at the table below.
| Virtualization Testing Results | |||
| Server System Comparison | vApus Mark I - 24 vCPUs |
vApus Mark I - 32 vCPUs |
VMmark |
| Quad Xeon X7460 vs. Dual Xeon X5570 2.93 |
6% | -2% | -15% |
| Quad Opteron 8435 vs. Dual Xeon X5570 2.93 |
29% | 26% | 21% |
| Quad Opteron 8435 vs. Quad X7460 |
21% | 28% | 42% |
| Dual Xeon X5570 2.93 vs. Dual Opteron 2435 |
11% | 30% | 54% |
Notice how the VMmark benchmark absolutely prefers the new "Nehalem" platform: the Dual Xeon X5570 is 54% faster, while it is only 11-30% on vApus Mark I. The quad Opteron 8435 is up to 30% faster than Intel's speed demon, while VMmark indicates only a 21% lead. But notice that vApus Mark I is also more friendly towards the Intel hex-core: VMmark tell us that eight Nehalems are 15% faster than 24 Dunnington cores. vApus Mark I tells us that the quad X7460 is about as fast as the dual Xeon X5570. So why is VMmark so much happier on the Xeon X5570 server? The answer might be found in the table below.
One VMmark tile generates about 21,000 interrupt per second, 22 MB/s of Storage I/O and 55 Mbit/s of network traffic. We have profiled vAPUS Mark in depth before. The table below compares both benchmarks from a Hypervisor point of view.
| Virtualization Benchmarks Profiling | ||
| vApus Mark I (Dual Xeon X5570) |
VMmark (Dual Xeon X5570) |
|
| Total interrupts per second | 2 x 19 K = 38 K/s | 17 * 21 = 357 K/s |
| Storage | 2 x 4.1MB/s = 8.2MB/s | 17*22 = 374 MB/s |
| Network | 2 x 50M bit/s = 100Mbit/s | 17* 55 MB/s = 935 Mbit/s |
VMmark places a lot more stress on the hypervisor and the way it handles I/O. It produces about 10 times more interrupts and almost a 100 times more storage I/O. We know from our profiling that vApus Mark I does a lot of page management, which is a logical result of the application choice (databases that open and close connections) and the amount of memory per VM.
The result is that VMmark with its huge number of VMs per server (up to 102 VMs!) places a lot of stress on the I/O systems. The reason for the Intel Xeon X5570's crushing VMmark results cannot be explained by the processor architecture alone. One possible explanation may be that the VMDq (multiple queues and offloading of the virtual switch to the hardware) implementation of the Intel NICs is better than the Broadcom NICs that are typically found in the AMD based servers.








32 Comments
View All Comments
blasterrr - Thursday, January 28, 2010 - link
how about itanium 2 benchmarks.we use itanium 2 in our company for our SAP Systems. i d like to compare itanium 2 performance with x86 performance.
does anyone know which architecture is better for most sap applications?
joekraska - Thursday, October 8, 2009 - link
Gentlemen,I run a large virtualization enterprise for a fortune 500 company. The platform of choice for virtualization is two socket systems. There are several reasons for this. First, VMWare charges roughly $2600 per socket. Second, 4 socket systems don't generally double the performance of two 2 socket systems. Third, 4 socket systems cost significantly more than two socket systems. Finally, the best 2 socket systems for virtualization have a large number of DIMM slots per cpu (e.g., our choice: Dell M/R710, 9 DIMM slots per CPU, or theoretically CISCO UCS 250, 24 slots per cpu), and virtualization enterprises want memory. VMWare doesn't charge you for the amount of memory you install, and that's what you need: memory.
As an aside I favor 2 socket systems categorically. If and only if someone has a high-count single system SMP need would I consider or permit anything else. 4 socket systems cost too much for what you get. It requires a problem that can not be solved without one to justify the investment.
Joe Kraska
San Diego CA
USA
solori - Wednesday, October 7, 2009 - link
The vAPUS tile graphics marked as 2345 are really 2435... What happended to the 2389 in those tests?solori - Wednesday, October 7, 2009 - link
John,Good follow-up to your earlier comparisons. A lot of work goes into these things and your team's done compiling the information here. I have just a few comments:
With respect to the VMmark reference, you've taken a vector value (X@Y) and made a scalar out of if. The performance number (X) is granted across a number of VMs running (Y, in tiles) which, in turn, helps to increase the scalar part you refer to a "speed" (i.e. 13% slower, etc.) In fact, your speed component could be determined by taking the X/Y and looking at the "tile ratio" to determine unit performance per tile. In doing so, you should see the "performance" gap close a bit.
This evaluation method also lends itself to what VMmark was created to achieve - a determination of performance as the platform scales across VMs. In other words, the implication of VMmark is that a system cannot scale due to its constituent applications being thread bound. By employing virtualization, the net number of active threads is maximized with little degradation on the per-application performance. When resource availability is impacted, the number of application groups (tiles) is at its maximum.
Perhaps a significant reason VMmark and vAPUS differ so widely is that VMmark creates a case for resource exhaustion and vAPUS use of resources is more arbitrary. Fitting a benchmark to the available resources for one system seems very hard to avoid, and your attention to hex-core versus quad-core scheduling is right on point -hence the significant difference in vAPUS.1 results. Kudos again for taking that into account - it is something that systems architects need to be more aware of and a lot of benchmarks step around.
One interesting result of the 24 vCPU case is that the difference between 2P,12-core opteron and 2P,16-thread Xeon is down to the ratio of their clock speeds. Likewise, the difference between the 4P and 2P cases would indicate that the number of vAPUS tiles could have been increased for those systems.
The issue still puzzling me about vAPUS is the sizing of the OLTP VMs. On the AMD machines you have in the lab, you could easily use the full database size with memory to spare and increase the size of RAM to the VMs accordingly. Doing so in the memory-cramped EP box would likely cripple its performance, but produce an admittedly more "real world" result. We don't see databases getting smaller out there anytime soon, nor do we see them being split-up to fit nominal hardware... The 24GB Xeon is kind of base-model compared to the 64GB Opterons - you might want to reconsider your testing policy where that's concerned.
On the virtualization use case, you cannot divorce the CAPEX economics of "right-sizing" your memory component. Too little memory and the Xeon has more threads than you can practically use. Too much memory, and you either out-strip the thread capacity (AMD or Intel) and get into higher $/VM due to memory costs. With 8GB/DDR2 about 1/2 the cost of 8GB/DDR3 (reg, ecc for both) you are looking at memory being the largest single factor between 5500's and 2400's where $/VM is concerned. Mixing consolidation and performance workloads across a VMM cluster (i.e. DRS in VMware) make the value of additional GB/core per-platform important.
Likewise, if you look at mature virtualization market approaches - rack or blade systems - you will not see many 2P systems force-fitted into 4P use cases. Likewise, you will not see 4P systems used where 2P systems would suffice. Therein, the advantage to having a 2P and 4P eco-system that supports seamless migration (i.e. vMotion or Live Migration) requires (today) coming down in one camp or the other. In this case, the advantage lies with AMD (for now), and your report shows that to be a decent choice.
I agree that EX will create a significant price gulf between EP and likely not help the Intel case in the 4P use virtualization use case. With AMD's Magny-Cours on track for Q1/2010 in 2P and later 4P (same basic platform) use cases today that are solid 4P Istanbul contenders have a drop-in for 2P Magny-Cours with solid enhanced migration capabilities. This can't do anything but put pressure on Intel to create a 4P competitor in both capability and price for AMD's offering.
We've done significant research in terms of CPU/memory pairings to find the "sweet spot" in $/VM which points to a lag in the market for consolidation utilization (or at least market intelligence). If the "typical" utilization scenario is 12-18 VM's, it is clear from your results that a significant amount of potential is wasted in either Nehalem or Istanbul platform. To maximize return, $/VM and Watt/VM must be considered in the deployment, pushing those numbers up by at least 50% per host. That said, memory re-enters the equation as a limiting factor - well beyond the 20GB in today's vAPUS test case.
As for the hex-core Xeon, the writing was on the wall in the virtualization use case as 8P/quad-core Opterons have proven all but equal on performance (about 95%) to 8P/hex-core Xeons. Dunnington's power use did not help its cause either...
Like you indicated in your piece, specialized systems like Twin2 and blades create a better performance/watt opportunity for both 5500 and 2400 platforms (especially with Fiorano and SR5600 socket-F options.) Perhaps as great follow-up for this series would be a Twin2 comparison of the 5500 and 2400 variants...
Collin C. MacMillan
Solution Oriented LLC
http://blog.solori.net">http://blog.solori.net
JohanAnandtech - Thursday, October 8, 2009 - link
Hi Collin,There is too much interesting stuff in your reaction to address every good point you make, so I will take a bit more time to digest this and send you an e-mail.
A few things on top of my head. Yes, a 64 GB Quad Opteron machine using only 20 GB or so is not optimal. At the same time we verify DQL (Disk Queue Length) so we are pretty sure that you are not going to gain much from making the cache larger. I'll check, maybe we simplified too much there. The reason for doing this is keeping things simple, as it is already hard enough to control the complexity of virtualized benchmarking. It is good suggestion to increase the cache size of the OLTP component for systems with larger amounts of memory, I'll think about it.
The resource exhaustion as done by VMmark is not perfect either as you might be going for maximum throughput at the cost of the response time of individual applications. It is a pretty hard exercise, I Guess we'll have to set a certain SLA: a max response time for each app and then measure total throughput.
skrewler2 - Wednesday, October 7, 2009 - link
Why do you never use a Sun box for your benchmarks?JohanAnandtech - Wednesday, October 7, 2009 - link
Which Sun box do you have in mind? And of course, like everyone, we are waiting to see what Oracle will do with Sun . While the Sun people used to send us testservers quite a few times a year or two ago, it is been very silent the past year.duploxxx - Wednesday, October 7, 2009 - link
Great article, however it might have been a bit more interesting if you would also start to add priceranges, comparing the best at all time is nice, but many people start to think that whatever version thye might buy will always be a better choice for them because they saw the highest benchmarks.duploxxx - Wednesday, October 7, 2009 - link
edit, wasn't finished yet :)knowing that you can buy a 2s E5530 2.4ghz system at the same price as a 2s 2435 2.6GHZ might bring already a whole different perspective.
Also comparing 2s against 4s is nice and i really like your virtual benchmark, it gives much more realistic results just as we have seen in our own sw benchmarking that Vmmark is no longer representative to real world. You still can't compare power consumption. First of all LP dimms costs now as much as normal dimms and secondly you only require 20GB ram in your test as you mentioned so 44GB is wasted but is still consuming a lot of power.
Choosing between 2s and 4s is a difficult choice, we deploy about 400-500 2s servers a year on VM, preferring more availability amount then bigger servers, 4s also needs a lot more fine tuning on IO then a 2s does, for sure if you use DRS, hitting the farm much harder on HA failure etc. Since 2004 we started on AMD and not moving back to intel just because they now have 1 decent server platform and as mentioned, check price/performance and think again if 55xx are so more far superior then 24xx series if you buy mid level servers like 90% of the server market does. Oh and we like Enhanced Vmotion off course.
SLIM - Tuesday, October 6, 2009 - link
Any thoughts on the effect of AMD's new server chipset on vmmark performance (http://www.amd.com/us/products/server/platforms/Pa...">http://www.amd.com/us/products/server/p...core-pro... They claim it will help with I/O and particularly virtualized I/O performance.