Rendering and HPC Benchmark Session Using Our Best Servers
by Johan De Gelas on September 30, 2011 12:00 AM ESTInvestigating the Opteron Performance Mystery
What really surprised us was the Opteron's abysmal performance in Stars Euler3D CFD. We did not believe the results and repeated the benchmark at least 10 times on the quad Opteron system. Let us delve a little deeper.
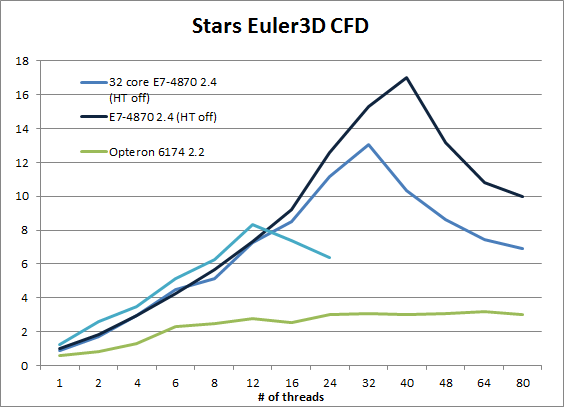
Notice that the Intel Xeons scale very well until the number of threads is higher than the physical core count. The performance of the 40 core E7-4870 only drops when we use 48 threads (with HT off). The Opteron however only scales reasonably well from 1 to 6 threads. Between 6 and 12 threads scaling is very mediocre, but at least performance increases. From there, the performance curve is essentially flat.
The Opteron Performance Remedy?
We contacted Charles of Caselab with our results. He gaves us a few clues:
1. The Euler3d CFD solver uses an unstructured grid (spider web appearance with fluid states stored at segment endpoints). Thus, adjacent physical locations do not (cannot!) map to adjacent memory locations.
2. The memory performance benchmark relevant to Euler3D appears to be the random memory recall rate and NOT the adjacent-memory-sweep bandwidth.
3. Typical memory tests (e.g. Stream) are sequential "block'' based. Euler3D effectively tests random access memory performance.
So sequential bandwidth is not the answer. In fact, in most "Streamish" benchmarks (including our own compiled binaries), the Quad Opteron was close to 100GB/s while the Quad Xeon E7 got only between 37 and 55GB/s. So far it seems that only the Intel compiled stream binaries are able to achieve more than 55GB/s. So we have a piece of FP intensive software that performs a lot of random memory accesses.
On the Opteron, performance starts to slow down when we use more than 12 threads. With 24 or even better 48 threads the application spawns more threads than the available cores within the local socket. This means that remote memory accesses cannot be avoided. Could it be that the performance is completely limited by the threads that have to go the furthest (2 hops)? In others words, some threads working on local memory finish much faster, but the whole test cannot complete until the slowest threads (working on remote memory) finish.
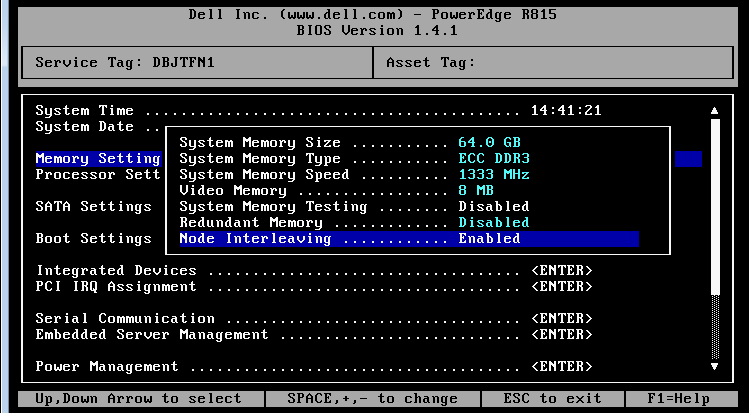
We decided to enable "Node Interleaving" in the BIOS of our Dell R815. This means that data is striped across all four memory controllers. Interleaved accesses are slower than local-only accesses because three out of four operations traverse the HT link. However, all threads should now experience a latency that is more or less the same. We prevent the the worst-case scenario where few threads are seeing 2-hop latency. Let us see if that helped.








52 Comments
View All Comments
derrickg - Friday, September 30, 2011 - link
Would love to see them benchmarked using such a powerful machine.JohanAnandtech - Friday, September 30, 2011 - link
Suggestions how to get this done?derrickg - Friday, September 30, 2011 - link
simple benchmarking: http://www.linuxhaxor.net/?p=1346I am sure there are much more advanced ways of taking benchmarks on chess engines, but I have long since dropped out of those circles. Chess engines usually scale very well from 1P and up.
JPQY - Saturday, October 1, 2011 - link
Hi Johan,Here you have my link how people can test with Chess calculatings in a very simple way!
http://www.xtremesystems.org/forums/showthread.php...
If you are interested you can always contact me.
Kind regards,
Jean-Paul.
JohanAnandtech - Monday, October 3, 2011 - link
Thanks Jean-Paul, Derrick, I will check your suggestions. Great to see the community at work :-).fredisdead - Monday, April 23, 2012 - link
http://www.theinquirer.net/inquirer/review/2141735...dear god, at last the truth. Interlagos is 30% faster
hey anand, whats up with YOUR testing.
fredisdead - Monday, April 23, 2012 - link
everybody, the opteron is 30% fasterhttp://www.theinquirer.net/inquirer/review/2141735...
follow thew intel ad bucks ... lol
anglesmith - Friday, September 30, 2011 - link
i was in a similar situation on a 48 core opteron machine.without numa my app was twice slower than a 4 core i7 920. then did a test with same number of threads but with 2 sockets (24 cores), the app became faster than with 48 cores :~
then found the issue is all with numa which is not a big issue if you are using a 2 socket machine.
once i coded the app to be numa aware the app is 6 times faster.
i know there are few apps that are both numa aware and scale to 50 or so cores but ...
tynopik - Friday, September 30, 2011 - link
benhcmarklike it Phenom
JoeKan - Friday, September 30, 2011 - link
I'd llove to see single core workstations used as baseline comparisons. In using a server to render, I'd be wondering which would be more cost effective to render animations. Maybe use an animation sequence as a render performance test.