The Intel Xeon E7-8800 v3 Review: The POWER8 Killer?
by Johan De Gelas on May 8, 2015 8:00 AM EST- Posted in
- CPUs
- IT Computing
- Intel
- Xeon
- Haswell
- Enterprise
- server
- Enterprise CPUs
- POWER
- POWER8
Haswell Architecture Improvements
We have discussed the advantages that the Haswell core brings here in more detail. In a nutshell:
- The core can sustain about 10% more integer instructions per clock cycle than its predecessor, Ivy Bridge.
- Virtualized applications should perform slightly better thanks to the lower VM exit/entry latency.
- HPC applications could/should benefit much more if they are recompiled to make use of the improved AVX2 and Fused Multiply Add (FMA) support
- Database transactional applications should benefit more thanks to the lower synchronization latency.
- In-memory databases should benefit if they are adapted to make use of the AVX-2 256 bit integer vector operations.
Again, the same is true about the Xeon E5-2600v3. So what makes the E7 special?
Transactional Synchronization Extensions: I'll be back
There is one "new" - or rather "now working" - feature: TSX or the famous Transactional Synchronization eXtensions. These extensions are all about making locking more "optimistic" (you let the CPU handle the bookkeeping to maintain consistency). TSX is quite powerful, but also can be a liability in the wrong use case. Developers will need a deep understanding of the locking and parallel programming to be able to make good use of TSX, as
- ... you still have to rewrite your code (inserting hints)
- TSX may reduce performance in some situations: if indeed a pessimistic lock was necessary, the transaction has to be re-executed with a "traditional" conservative way of locking. You could call it a "lock misprediction".
Introducing TSX in software requires assessing the different locks in application, using different libraries and quite a bit of of tuning. SAP and Intel did this for the expensive in-memory data mining SAP HANA software.
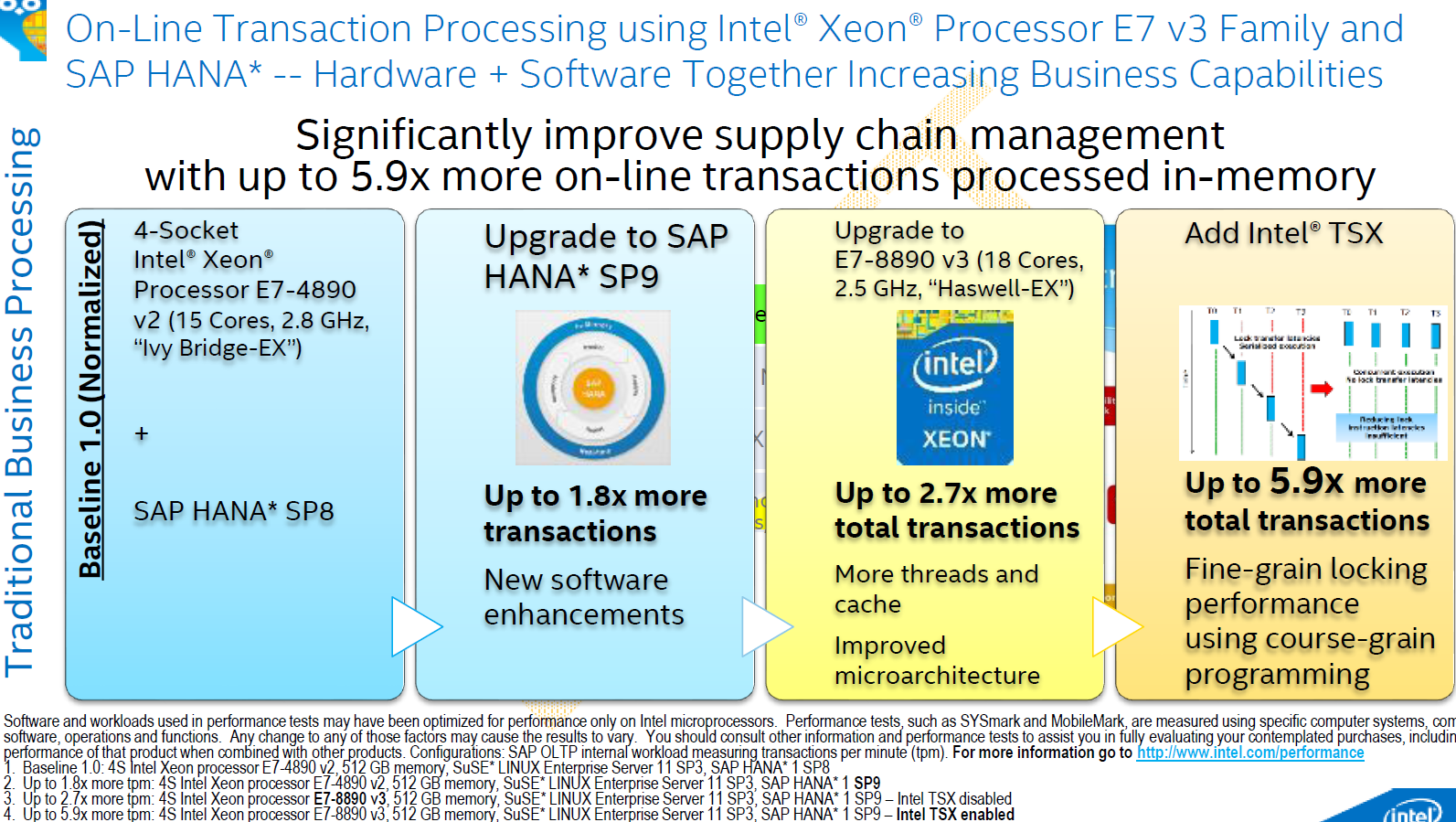
The upgrade from "Ivy Bridge EX" to "Haswell-EX" yielded 50% performance, while introducing TSX roughly doubled performance. So in TSX enabled data mining software, Haswell-EX has the potential to reduce the waiting time by a factor of 3 and more.








146 Comments
View All Comments
Shadowmaster625 - Friday, May 8, 2015 - link
This kind of provides more proof that Intel would do well to incease its SMT threads per core count.nathanddrews - Friday, May 8, 2015 - link
I'd like to see that alongside another GHz War.Brutalizer - Sunday, May 10, 2015 - link
This is silly. For serious enterprise use taking on some serious workload, you need large servers. Not low end 2,4 or 8 sockets. The largest x86 servers are all 8 sockets, there are no larger servers for sale and have never been. If we go into high end servers, we will find POWER8 servers, and SPARC servers. The top SAP benchmark is 836,000 saps, and held by a large Fujitsu SPARC M10-4S server. So... no, x86 has no performance of interest. Scalability is difficult, and that is why x86 stops at 8 sockets, and only Unix/Mainframes go beyond, up to 64 sockets. Remember that I talk about business servers, running monolithic software like sap, databases, etc -also called Scale-up servers.The difference is Scale-out servers, I.e HPC clusters, such as SGI UV2000 servers, resembling supercomputers with 100s of sockets. Supercomputers are all clusters. Scale out servers can not run business software, because the code branches too much. They can only run HPC parallel workloads, where each PC node computes in a tight for loop, and at the end summarizes the result of all nodes. The latency in far away nodes is very bad, so scale out servers can not run heavily branching code (business software such as SAP, databases, etc). All top SAP benchmarks are held by large Unix scale up servers, there are no scale out servers on the SAP benchmark list (SGI, ScaleMP).
So, if we talk about serious business workloads, x86 will not do, because they stop at 8 sockets. Just check the SAP benchmark top - they are all more than 16 sockets, Ie Unix servers. X86 are for low end and can never compete with Unix such as SPARC, POWER etc. scalability is the big problem and x86 has never got passed 8 sockets. Check SAP benchmark list yourselves, all x86 are 8 sockets, there are no larger.
Sure, if you need to do HPC number crunching, then SGI UV2000 cluster is the best choice. But clusters suck at business software.
Kevin G - Monday, May 11, 2015 - link
Oh this again? The UV 2000 is a single large SMP machine as it has a unified memory space, cache coherent and a single OS/hypervisor can manage all the processors. Take a look at this video from SGI explaining it:https://www.youtube.com/watch?v=KI1hU5g0KRo
And then while you're at it, watch this following video where you see first hand that Linux sees their demo hardware as a 64 socket, 512 core machine (and the limit is far higher):
https://www.youtube.com/watch?v=lDAR7RoVHp0
As for your claim that systems like the UV2000 cannot run scale-up applications, SGI sells a version specifically for SAP's HANA in-memory database because their hardware scales all the way upto 64 TB of memory. http://www.enterprisetech.com/2014/06/03/sgi-scale...
As for x86 scaling to 8 sockets, that is the limit for 'glueless' topologies but you just need to add some glue to the interconnect system. Intel's QPI bus for coherent traffic is common between their latest Xeons and Itanium chips. This allowed HP to use the node controller first introduced in an Itanium system as the necessary glue logic to offer the 16 socket, x86 based Superdome X 'Dragonhawk' system. This is not the systems limit either at the node controller and recent Xeons could scale up to 64 sockets. Similarly when IBM was still in the x86 server game, they made their own chipsets and glue logic to offer 16 or 32 socket x86 systems for nearly a decade now.
As for SAP benchmarks, x86 is in the top 10 and that is only with an 8 core machine. We oddly haven't yet seen results from HP's new Superdome X system which should be a candidate for the top 10 as well.
One of these days you'll drop the FUD and realize that there are big SMP x86 offerings on the market. Given your history on the topic, I'm not going to hold my breath waiting.
Brutalizer - Monday, May 11, 2015 - link
There are no stupid people, only uninformed people. You sir, are uninformed.First of all, scale up is not equal to smp servers. Sure, SGI claims UV2000 servers are smp servers (miscrosoft claims windows is an enterprise os) but no one use SGI servers for business software, such as SAP or databases which run code that branches heavily. Such code penalizes scale out servers such as SGI clusters because latency is too bad in far away nodes. The only code fit for scale out clusters are running a tight for loop on each node, doing scientific computations.
But instead of argiung over this, disprove me. I claim no one use SGI nor ScaleMP servers for Business software such as SAP or databases. Prove me wrong. Show me a SAP benchmark with an x86 server having more than 8 sockets. :)
SAP Hana you mentioned, is a clustered database. It is not monolithic, and a monolithic database running on a scale up server easily beats a cluster. It is very difficult to synchronize data among nodes and guarantee data integrity (rollback etc) on a cluster. It is much easier and faster to do on a scale up server. Oracle M7 server with 32 sockets and 64 TB ram will easily beat any 64 TB SGI cluster on business software. It has 1.024 cores and 8.192 threads. SPARC M7 cpu is 3-4x faster than the SPARC M6 cpu, which is the latest generation cpu, having several records today. One M7 cpu does SQL queries at a rate of 120 GB/sec, whereas a x86 cpu does... 5GB/sec (?) sql queries.
Oracle data warehouse that some have tried on a scale out cluster, is not a database. It is exclusively used for data mining of static data, which makes heavy use of parallel clustered computations. No one modifies data on a DWH so you dont need to guarantee data integrity on each node, etc.
So, please show me ANY x86 server that can compete with the top SPARC servers reaching 836.000 saps on the SAP benchmark. SAP is monolithic, which means scaling is very difficult, if you double the number of sockets, you will likely gain 20% or so. Compare the best x86 server on SAP to large Unix servers. SGI or ScaleMP or whatnot. The largest x86 server benchmarked on SAP has 8 sockets. No more. There are no scale out servers on sap. Prove me wrong. Go ahead.
The HP superdome server is actually a Unix architectured server, that is slowly being transformed to x86 server. Scaling on x86 is difficult, so the new and shiny x86 superdome will never scale as well as the old Unix server having 32 sockets, x86 superdome will remain at 8-16 sockets for a long time, maybe another decade or two. IBM has also tried to compile linux onto their P795 unix server, with bad results but that does not make the p795 a linux server, it is still a unix server. Good luck on getting a good SAP score with any x86 server, HP Superdome, SGI UV2000, whatever.
Instead of arguing, silence me by proving me wrong: prove that ANY x86 server can compete with large Unix servers on SAP. Show us benchmarks that rival SPARC 836,000 saps. :). It is very uninformed to believe that x86 can get high SAP scores. As i said you will not find any high x86 scores. Why? Answer: x86 does not scale. x86 clusters can not run SAP because of bad latency, that is why SGI nor ScaleMP is benching SAP.
FUD, eh? It is you that FUD, claiming that x86 can get high scores on bisuness software. If you speak true, then you can show us any good SAP score. If you can not, you are uninformed and hopefully, you will not say so again.
Btw, both SGI and ScaleMP claim their servers are scale out, only suited for HPC number crunching, (not for business scale up work loads).I can link to these claims straoght from them both.
patrickjp93 - Monday, May 11, 2015 - link
The amount of BS you post is astounding! Latencies over Infiniband are in the < 10nanosecond range these days. Rollback and sync are also easy! MPI fixed those problems a long damn time ago. And monolithic anything is far too expensive and has the same failure rates as x86 machines. Scale up is only worthwhile if you're limited to a janitor's closet for your datacenter.SAP is also a fundamentally broken benchmark which Linpack created an equivalent for a long time ago which x86 basically ties in.
patrickjp93 - Monday, May 11, 2015 - link
God damnit Anandtech create an edit feature!Furthermore, do you have any knowledge of the networking fabric Intel rolled out a few years ago? Scaling issues in x86 died back with Ivy Bridge.
There is also no scale-up workload that cannot be refactored for scale-out with minimal loss in scaling.
Brutalizer - Tuesday, May 12, 2015 - link
@KevingGYou are still uninformed. But let me inform you. I will not answer to each post, I will only make one post, because otherwise there will be lot of different branches.
First of all, you post a link about the US Postal Service use SGI UV2000 to successfully run a Oracle database, which supposedly proves that I am wrong, when I claim that no one use SGI UV2000 scale-out clusters with 100s of sockets, for business software such as SAP or databases.
Here we go again. Well for the umpteen time, you are wrong. The Oracle database in question is TimesTen, which is an IMDB (In Memory DataBase). It stores everything in RAM. The largest TimesTen customer has 2TB data. Which is tiny compared to a real DB:
http://www.oracle.com/technetwork/products/timeste...
I will quote this technical paper about In Memory DataBases below:
http://www.google.se/url?sa=t&rct=j&q=&...
The reason you store everything in RAM, instead of disk, is you want to optimize for analytics, Business Intelligence, etc. If you really want to store data, you use permanent storage. If you only want fast access, you use RAM. TimesTen is not used as a normal DB, it is a nische product similar to a Data WareHouse exclusively for analytics. Your link has this title: "U.S. Postal Service Using Supercomputers to Stamp Out Fraud"
i.e. they use the UV2000 to analyse and find fraud attempts. Not to store data. Just analyse read queries, like you would a Data WareHouse.
A normal DB alters data all the time, inducing locks on rows, etc. In Memory DataBases often dont even use locking!! They are not designed for modyfying data, only reading.
Page 44: "Some IMDBs have no locking at all"
This lock cheating partly explains why IMDBs are so fast, they do small and simple queries. US Postal Service has a query roundtrip at 300 milliseconds. A real database takes many hours to process some queries. In fact, Merrill Lynch was so happy about the new Oracle SPARC M6 server, because it could even complete some large queries which never even finished on other servers!!!
This read only makes IMDB easy to run on clusters, you dont have to care about locking, synchronizing data, data integrity, etc - which makes it easy to parallelize. Like SAP Hana, both Oracle TimesTen are clustered. Both are clustered DBs and runs on different partition nodes, i.e. horizontal scaling = scale-out.
Page 21: "IMDBs Usually scale horizontally over multiple nodes"
Page 55-60: "IMDB Partitioning & Multi Node Scalability".
Also, TimesTen is a database on the application layer, a middle ware database!! A real database acts at the back end layer. Period. In fact, IMDB often acts as cache to a real database, similar to a Data WareHouse. I would not be surprised if US Postal Service use TimesTen as a cache to a real Oracle DB on disk. You must store the real data on disk somewhere, or get the data from disk. Probably a real Oracle DB is involved somehow.
Page 71-72: "TimesTen Cache Connect With Oracle Database"
So, again, you can not run business software on scale-out servers such as SGI or ScaleMP. You need to redesign and rewrite everything. Look at SAP Hana, which is a redesigned clustered RAM database. Or Orace TimesTen. You can not just take a business software such as SAP or Oracle RDBMS Database and run it ontop SGI UV2000 cluster. You need to redesign and reprogram everything:
Page 96: "Despite the blazing performance numbers just seen, don’t expect miracles by blindly migrating your RDBMS to IMDB. This approach
may fetch you just about 3X or lower:... Designing your app specifically for IMDB will be much more rewarding, sometimes even to the tune or 10 to 20X"
Once again, IMDBs can not replace databases:
Page97: "Are IMDBs suited for OLAP? They are getting there, but apart from memory size limitations, IMDB query optimizers probably have a while to go before they take on OLAP"
http://www.google.se/url?sa=t&rct=j&q=&...
Page 4: "Is IMDB a replacement for Oracle? No"
I dont know how many times I must say this? You can not just take a normal business software and run it ontop SGI UV2000. Performance would suxx big time. You need to rewrite it as a clustered version. And that is very difficult to do for transaction heavy business software. It can only be done in RAM.
Here we even see a benchmark of Oracle RDBMS vs Oracle TimeStep. And for large workloads, the Oracle RMDBS database is faster.
http://www.peakindicators.com/index.php/knowledge-...
So you are wrong. No body use SGI UV2000 scale out clusters to run business software. The only way to do it, is to redesign and rewrite everything to a clustered version. You can never take a normal monolithic business software and run it ontop SGI UV2000. Never. Ever.
@Patrickjp93
No, you are wrong, latency will be bad in large scale out clusters. The problem with scaling, is that ideally, every socket needs a direct data communication channel to every other socket. Like this. Here we see 8 sockets each having a direct channel to every other socket. This is very good and gives excellent scaling:
http://regmedia.co.uk/2012/09/03/oracle_sparc_t5_c...
Here we have 32 sockets communicating to each other in a scale-up server. We see that at most, there is one step to reach any other socket. Which is very good and gives good scaling, making this SPARC M6 server suitable for business software. Look at the mess with all interconnects!
http://regmedia.co.uk/2013/08/28/oracle_sparc_m6_b...
Now lets look at the largest IBM POWER8 server E880 sporting 16 sockets. We see that only four sockets communicate directly with each other, and then you need to do another step to reach another four socket group. To reach far away sockets, you need to do several steps, on a smallish 16 socket server. This is cheating and scales bad.
http://www.theplatform.net/wp-content/uploads/2015...
Here is another example of a 16 socket x86 server. Bull Bullion. Look at the bad scaling. Every socket is grouped as four and four. And to reach sockets far away, you need to do several steps. This construction might be exactly like the IBM POWER8 server above and is bad engineering. Not good scaling.
https://deinoscloud.files.wordpress.com/2012/10/bu...
In general, if you want to connect each socket to every other, you need O(n^2) channels. This means for a SGI UV2000 with 256 sockets, you need 35.000 channels!!! Every engineer realizes that it is impossible. You can not have 35.000 data channels in a server. You need to cheat a lot to bring down the channels to a manageble number. Probably SGI has large islands of sockets, connected to islands with one fast highway, and then the data needs to go into smaller paths to reach the destining socket. And then locking signals will be sent back to the issuing socket. And forth to synch. etc etc. The latency will be VERY slow in a transaction heavy environment. Any engineer sees the difficulties with latency. You can have throughput or low latency, but not both.
Do you finally understand know, why large clusters can not run business software that branches all over the place??? Scalability is difficult! Latency will be extremely bad in transaction heavy software, with all synchronizing going on, all the time.
SGI explains why their huge Altix cluster with 4.096 cores (predecessor of UV2000) is not suitable for business software, but only good for HPC calculations:
http://www.realworldtech.com/sgi-interview/6/
"...The success of Altix systems in the High Performance Computing market are a very positive sign for both Linux and Itanium. Clearly, the popularity of large processor count Altix systems dispels any notions of whether Linux is a scalable OS for scientific applications. Linux is quite popular for HPC and will continue to remain so in the future,
...
However, scientific applications (HPC) have very different operating characteristics from commercial applications (SMP). Typically, much of the work in scientific code is done inside loops, whereas commercial applications, such as database or ERP software are far more branch intensive. This makes the memory hierarchy more important, particularly the latency to main memory. Whether Linux can scale well with a SMP workload is an open question. However, there is no doubt that with each passing month, the scalability in such environments will improve. Unfortunately, SGI has no plans to move into this SMP market, at this point in time ...."
ScaleMP explains why their large scale-out server with 1000s of cores are not suitable for business software:
http://www.theregister.co.uk/2011/09/20/scalemp_su...
"...ScaleMP cooked up a special software hypervisor layer, called vSMP, that rides atop the x64 processors, memory controllers, and I/O controllers in multiple server nodes....vSMP takes multiple physical servers and... makes them look like a giant virtual SMP server with a shared memory space. vSMP has its limits.
...
The vSMP hypervisor that glues systems together is not for every workload, but on workloads where there is a lot of message passing between server nodes – financial modeling, supercomputing, data analytics, and similar parallel workloads. Shai Fultheim, the company's founder and chief executive officer, says ScaleMP has over 300 customers now. "We focused on HPC as the low-hanging fruit..."
https://news.ycombinator.com/item?id=8175726
">Still don't understand why businesses buy this SPARC M7 scale-up server instead of scaling-out. Cost? Complexity?"
>>I'm not saying that Oracle hardware or software is the solution, but "scaling-out" is incredibly difficult in transaction processing. I worked at a mid-size tech company with what I imagine was a fairly typical workload, and we spent a ton of money on database hardware because it would have been either incredibly complicated or slow to maintain data integrity across multiple machines. I imagine that situation is fairly common.
>>Generally it's just that it's really difficult to do it right. Sometime's it's impossible. It's often loads more work (which can be hard to debug). Furthermore, it's frequently not even an advantage. Have a read of https://research.microsoft.com/pubs/163083/hotcbp1... Remember corporate workloads frequently have very different requirements than consumer."
@KevinG
But instead of arguing over how you wish x86 servers would look like, lets go to real hard facts and real proofs instead. Lets settle this once and for all, instead of arguing.
Fact: x86 servers are useless for business software because of the bad performance. We have two different servers, scale-up (vertical scaling) servers (one single huge server, such as Unix/Mainframes) and scale-out (horizontal scaling) servers (i.e. clusters such as SGI UV2000 and ScaleMP - they only run HPC number crunching on each compute node).
1) Scale-up x86 servers. The largest in production has 8-sockets (HP Superdome is actually a Unix server, and no one use the Superdome x86 version today because it barely only goes to 16-sockets with abysmal performance, compared to the old Unix 32-socket superdome). And as we all know, 8 sockets does not cut it for large workloads. You need 16 or 32 sockets or more. The largest x86 scale up server has 8 sockets => not good performance. For instance, saps score for the largest x86 scale up server is only 200-300.000 or so. Which is chicken sh-t.
2) Scale-out x86 servers. Because latency is so bad in far away nodes, you can not use SGI UV2000 or ScaleMP clusters with 100s of sockets. I expect the largest SGI UV2000 cluster post scores of 100-150.000 saps because of bad latency, making performance grind to a halt.
To disprove my claims and prove that I am wrong: post ANY x86 benchmark with good SAP. Can you do this? Nope. Ergo, you are wrong. x86 can not tackle large workloads. No matter how much you post SGI advertising, it will not change facts. And the fact is: NO ONE USE x86 FOR LARGE SAP INSTALLATIONS. BECAUSE YOU CAN NOT GET HIGH SAP SCORES. It is simply impossible to use x86 to get good business software performance, such as SAP, databases, etc. Scale-up dont do. Scale-out dont do.
Prove me wrong. I am not interested in you bombarding links on how good SGI clusters are. Just disprove me on this. Just post ONE single good SAP benchmark. If you can not, I am right and you are wrong, which means you probably should sh-t up and stop FUD. There is a reason we have a highend Unix/Mainframe market, x86 are for lowend and can never compete.
I dont expect you to ever find any good x86 links, so let the cursing and shouting begin. :-)
Kevin G - Tuesday, May 12, 2015 - link
“Here we go again. Well for the umpteen time, you are wrong. The Oracle database in question is TimesTen, which is an IMDB (In Memory DataBase). It stores everything in RAM. The largest TimesTen customer has 2TB data. Which is tiny compared to a real DB:”That is very selective reading as the quote is ‘over 2 TB’ from your source. The USPS TimesTen data base is a cache for a >10 TB Oracle data warehouse. Also from the technical paper you linked below, this is not a major issue as several in-memory database applications can spool historical data to disk;
“I will quote this technical paper about In Memory DataBases below:”
The main theme of that paper as to why in memory databases have gain in popularity is that they remove the storage subsystem bottleneck for a massive increase in speed. That is the main difference that the technical paper is presenting, not anything specific about the UV 2000.
“A normal DB alters data all the time, inducing locks on rows, etc. In Memory DataBases often dont even use locking!! They are not designed for modyfying data, only reading.
Page 44: "Some IMDBs have no locking at all"”
First off, analytics is a perfectly valid use of a database for businesses.
Second, the quote form page 44 is wildly out of context to the point of willful ignorance. The word in that sentence is ‘some’ and the rest of that page indicates various locking mechanisms used in In Memory Databases.
I should also indicate that there are traditional databases that have been developed to not use locking either like MonetDB. In otherwords, the locking distinction has no bearing on being an in-memory database or not.
“Also, TimesTen is a database on the application layer, a middle ware database!! A real database acts at the back end layer. Period. In fact, IMDB often acts as cache to a real database, similar to a Data WareHouse. I would not be surprised if US Postal Service use TimesTen as a cache to a real Oracle DB on disk. You must store the real data on disk somewhere, or get the data from disk. Probably a real Oracle DB is involved somehow.”
They do and back in 2010 the disk size used for the warehouse was 10TB. Not sure of the growth rate, but considering the SGI UV2000 can support up to 64 TB of memory, a single system image might be able to host the entirety of it in memory now.
“So, again, you can not run business software on scale-out servers such as SGI or ScaleMP. You need to redesign and rewrite everything. Look at SAP Hana, which is a redesigned clustered RAM database. Or Orace TimesTen. You can not just take a business software such as SAP or Oracle RDBMS Database and run it ontop SGI UV2000 cluster. “
If the software can run on ordinary x86 Linux boxes, then why couldn’t they run on the UV2000? What is the technical issue? Performance isn’t a technical issue, it’ll run, just slowly.
“You need to redesign and reprogram everything:
Page 96: "Despite the blazing performance numbers just seen, don’t expect miracles by blindly migrating your RDBMS to IMDB. This approach
may fetch you just about 3X or lower:... Designing your app specifically for IMDB will be much more rewarding, sometimes even to the tune or 10 to 20X"”
That is in the context of an in memory database, not an optimization specifically for the UV 2000. Claiming otherwise is just deceptive.
“Once again, IMDBs can not replace databases:
Page97: "Are IMDBs suited for OLAP? They are getting there, but apart from memory size limitations, IMDB query optimizers probably have a while to go before they take on OLAP"”
The quote does not claim what you think it say. First, not all databases focus on OLAP queries. Two, the overall statement appears to be made about the general maturity of in memory database software, not that it is an impossibility.
“Page 4: "Is IMDB a replacement for Oracle? No"
Wow, you didn’t even get the quote right nor complete it. “Is MCDB a replacement for Oracle? No. MCDB co-exists and enhances regular Oracle processing and has built in synchronization with Oracle.” The fully clarifies that MCDB is a cache for Oracle and it is clear on its purpose. This is applies to the specific MCDB product, not in memory database technologies at as whole.
“I dont know how many times I must say this? You can not just take a normal business software and run it ontop SGI UV2000. Performance would suxx big time. You need to rewrite it as a clustered version. And that is very difficult to do for transaction heavy business software. It can only be done in RAM.”
I’m still waiting for a technical reason as to why. What in the UV 2000’s architecture prevent it from running ordinary x86 Linux software? I’ve linked to videos that demonstrate that the UV2000 is a single coherent system. Did you not watch them?
“So you are wrong. No body use SGI UV2000 scale out clusters to run business software. The only way to do it, is to redesign and rewrite everything to a clustered version. You can never take a normal monolithic business software and run it ontop SGI UV2000. Never. Ever.”
Citation please. This is just one of your assertions. I’d also say that SAP HANA and Oracle TimesTn qualify as normal monolithic business software.
“Here we have 32 sockets communicating to each other in a scale-up server. We see that at most, there is one step to reach any other socket. Which is very good and gives good scaling, making this SPARC M6 server suitable for business software. Look at the mess with all interconnects!”
Actually that is two steps between most nodes: Processor -> node controller -> processor. There are still a few single step processor -> processor hops but they’re a minority.
Also I think I should share the link where that image came from: http://www.theregister.co.uk/2013/08/28/oracle_spa...
That article includes the quote: “This is no different than the NUMAlink 6 interconnect from Silicon Graphics, which implements a shared memory space using Xeon E5 chips”. Ultimately UV 2000 has the same topology to scale up as this SPARC system you are as an example.
“Now lets look at the largest IBM POWER8 server E880 sporting 16 sockets. We see that only four sockets communicate directly with each other, and then you need to do another step to reach another four socket group. To reach far away sockets, you need to do several steps, on a smallish 16 socket server. This is cheating and scales bad.”
This is no different than the SPARC system you linked to earlier: two hops. At most you have processor -> processor - > processor to reach your destination. The difference is that the middle hop on the SPARC platform doesn’t contain a memory region but a lot more interconnections. The advantage of the SPARC topology is going to large socket counts but at the 16 socket level, the IBM topology would be superior.
“In general, if you want to connect each socket to every other, you need O(n^2) channels. This means for a SGI UV2000 with 256 sockets, you need 35.000 channels!!! Every engineer realizes that it is impossible. You can not have 35.000 data channels in a server. You need to cheat a lot to bring down the channels to a manageble number. Probably SGI has large islands of sockets, connected to islands with one fast highway, and then the data needs to go into smaller paths to reach the destining socket. “
SGI is doing the exact same thing as Oracle’s topology with NUMALink6.
“SGI explains why their huge Altix cluster with 4.096 cores (predecessor of UV2000) is not suitable for business software, but only good for HPC calculations:
http://www.realworldtech.com/sgi-interview/6/”
The predecessor to the UV 2000 was the UV 1000 which had a slightly different architecture to scale up but it was fully shared memory and cache coherent architecture.
The Altix system you are citing was indeed a cluster but that was A DECADE AGO. In that time frame, SGI has developed a new architecture to scale up by using shared memory and cache coherency.
“Fact: x86 servers are useless for business software because of the bad performance. We have two different servers, scale-up (vertical scaling) servers (one single huge server, such as Unix/Mainframes) and scale-out (horizontal scaling) servers (i.e. clusters such as SGI UV2000 and ScaleMP - they only run HPC number crunching on each compute node).”
INCORRECT. The SGI UV2000 is a scale up system as it is one server. SAP HANA and Oracle TimesTen are not HPC workloads and I’ve given examples of where they are used.
“1) Scale-up x86 servers. The largest in production has 8-sockets (HP Superdome is actually a Unix server, and no one use the Superdome x86 version today because it barely only goes to 16-sockets with abysmal performance, compared to the old Unix 32-socket superdome). And as we all know, 8 sockets does not cut it for large workloads. You need 16 or 32 sockets or more. The largest x86 scale up server has 8 sockets => not good performance. For instance, saps score for the largest x86 scale up server is only 200-300.000 or so. Which is chicken sh-t.”
The best SAP Tier-2 score for x86 is actually 320880 with an 8 socket Xeon E7-8890 v3. Not bad in comparison as the best score is 6417670 for a 40 socket, 640 core SPARC box. In other words, it takes SPARC 5x the sockets and 4.5x the cores to do 2x the work.
“2) Scale-out x86 servers. Because latency is so bad in far away nodes, you can not use SGI UV2000 or ScaleMP clusters with 100s of sockets. I expect the largest SGI UV2000 cluster post scores of 100-150.000 saps because of bad latency, making performance grind to a halt.”
“To disprove my claims and prove that I am wrong: post ANY x86 benchmark with good SAP. Can you do this?”
Yes, I believe I just did:
http://download.sap.com/download.epd?context=40E2D...
Brutalizer - Sunday, May 17, 2015 - link
@KevinG"...I’m still waiting for a technical reason as to why [you can not take normal business software and run ontop SGI UV2000]. What in the UV 2000’s architecture prevent it from running ordinary x86 Linux software?..."
I told you umpteen times. The problem is that scalability in code that branches heavily can not be run on SGI scale-out clusters as explained by links from SGI and links from ScaleMP (who also sells a 100s-socket Linux scale out server). And the SGI UV2000 is just a predecessor in the same line of servers. Again: UV2000 can. not. run. monolithic. business. software. as. explained. by. SGI. and. ScaleMP.
.
"...Citation please [about "No body use SGI UV2000 scale out clusters to run business software"]. This is just one of your assertions. I’d also say that SAP HANA and Oracle TimesTn qualify as normal monolithic business software...."
Again, SAP HANA is a clustered database, designed to run on scale-out servers. Oracle TimesTen is a nische database that is used for in-memory analytics, not used as a normal database - as explained in your own link. No one use scale-out servers to run databases, SAP, etc. No one. Please post ONE SINGLE occurence. You can not.
If scale-out servers could replace an expensive Unix server, SGI and ScaleMP would brag about it all over their website. Business software is high margin and the servers are very very very expensive. The Unix server IBM P595 with 32 sockets for the old TPC-C record costed $35 million - no typo. On the other hand, a large scale-out cluster with 100s of sockets costs the same as 100 nodes. The pricing is linear because you just add another compute node, which is cheap. On scale-up servers, you need to redesign everything for the scalability problem - that is why they are extremely expensive. 32-socket scale up servers cost many times the price of 256-socket scale-out clusters.
Banks would be very happy if they could buy a cheap 256-socket SGI UV2000 server with 64TB RAM, to replace a single 16- or 32-socket server with 8-16TB RAM that costs many times more. The Unix high end market would die in an instant if cheap 256-socket scale-out clusters could replace 16- or 32-socket scale-up servers. And facts are: NO ONE USE SCALE-OUT SERVERS FOR BUSINESS SOFTWARE! Why pay many times more if investment banks could buy cheap x86 clusters? You havent thought of that?
.
"....Yes, I believe I just did: [“To disprove my claims and prove that I am wrong: post ANY x86 benchmark with good SAP. Can you do this?”]..."
http://download.sap.com/download.epd?context=40E2D...
This is silly. Only desktop home users would consider SAP benchmark of 200-300.000 good. I am talking about SAP benchmarks, close to a million. I am talking about GOOD performance. It is now very clear you have no clue about large servers with high performance.
.
"....The best SAP Tier-2 score for x86 is actually 320880 with an 8 socket Xeon E7-8890 v3. Not bad in comparison as the best score is 6417670 for a 40 socket, 640 core SPARC box. In other words, it takes SPARC 5x the sockets and 4.5x the cores to do 2x the work...."
You are wrong again. The top record is held by a SPARC server, and the record is ~850.000 saps.
download.sap.com/download.epd?context=40E2D9D5E00EEF7C569CD0684C0B9CF192829E2C0C533AA83C6F5D783768476B
As I told you, scalability on business software is very difficult. Add twice the number of cores and get, say 20% increase in performance (when we talk about a very high number of sockets). If scalability was easy, we would see SGI UV2000 benchmarks all over the place: 256-sockets vs 192-sockets vs 128 sockets, etc etc etc. And ScaleMP would also have many SAP entries. The top list would exclusively be x86 architecture, instead of POWER and SPARC. But fact is, we dont see any x86 top SAP benchmarks. There are no where to be found.
Let me ask you again, for the umpteen time: CAN YOU POST ANY GOOD x86 SAP SCORE??? I talk about close to a million saps, not 200-300.000. If you can not post any such x86 scores, then I suggest you just sh-t up and stop FUD. You are getting very tiresome with your ignorance. We have talked about this many times, and still you claim that SGI UV2000 can replace Unix/Mainframe servers - well if they can, show us proof, show us links where they do that! If there are no evidence that x86 can run large databases or large SAP configurations, etc, stop FUD will you?????