Original Link: https://www.anandtech.com/show/1438
Linux and L2 Cache; Sempron vs. Athlon
by Kristopher Kubicki on August 18, 2004 2:29 AM EST- Posted in
- Linux
As AMD rolls out its newest Sempron processor line, many readers are asking us if the reduced cache Socket 754 Sempron 3100+ really compares with already shipping Athlon 64 single channel solutions. Today we take two single channel, 1.8GHz processors with differing L2 cache and compare them in the same Linux benchmarks we have used in the past. The Athlon 64 2800+ and the Sempron 3100+ are nearly identical processors, except for the 256KB cache difference. There is also a $20 delta between the two retail products, so today we decide if the $20 difference between the two processors is worth the sacrafice of level two cache and 64-bit addressing. We have provided benchmarks of another 1.8GHz 32-bit processor from AMD, as well as the Athlon 64 3000+ for reference only.
Update: This article got pushed live prematurely. If you read it before 12PM EST on the 18th, you read an incomplete, unfinished article.
| Performance Test Configuration | |
| Processor(s): | AMD Athlon 64 2800+ (130nm,
1.8GHz, 512KB L2 Cache) |
| RAM: | 2 x 512MB PC-3200 CL2 (400MHz) |
| Memory Timings: | Default |
| Motherboard: | Chaintech ZNF-250 (nForce3,
Socket 754) DFI NFII Infinity (nForce2, Socket 462) |
| Operating System(s): | SuSE 9.1 Professional (32 bit) Linux 2.6.4-52-default |
| Compiler: | linux:~ # gcc -v Reading specs from /usr/lib/gcc-lib/i586-suse-linux/3.3.3/specs Configured with: ../configure --enable-threads=posix --prefix=/usr --with-local-prefix=/usr/local --infodir=/usr/share/info --mandir=/usr/share/man --enable-languages=c,c++,f77,objc,java,ada --disable-checking --libdir=/usr/lib --enable-libgcj --with-gxx-include-dir=/usr/include/g++ --with-slibdir=/lib --with-system-zlib --enable-shared --enable-__cxa_atexit i586-suse-linux Thread model: posix gcc version 3.3.3 (SuSE Linux) |
| Libraries: | linux:~ # /lib/libc.so.6
GNU C Library stable release version 2.3.3 (20040405), by Roland McGrath et al.
Copyright (C) 2004 Free Software Foundation, Inc.
This is free software; see the source for copying conditions.
There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A
PARTICULAR PURPOSE.
Configured for i686-suse-linux.
Compiled by GNU CC version 3.3.3 (SuSE Linux).
Compiled on a Linux 2.6.4 system on 2004-04-05.
Available extensions:
GNU libio by Per Bothner
crypt add-on version 2.1 by Michael Glad and others
linuxthreads-0.10 by Xavier Leroy
GNU Libidn by Simon Josefsson
NoVersion patch for broken glibc 2.0 binaries
BIND-8.2.3-T5B
libthread_db work sponsored by Alpha Processor Inc
NIS(YP)/NIS+ NSS modules 0.19 by Thorsten Kukuk
Thread-local storage support included.
Report bugs using the `glibcbug' script to |
Even though we are using 1GB of memory in a dual channel configuration, the Socket 754 platform will only perform in single channel mode. Fortunately for AMD, since the memory controller is directly on the processor we do not see large latencies going from dual channel to single channel mode. Only the Athlon 64 2800+ can run 64-bit binaries, so for the sake of experiment we will only look at 32-bit binaries today. We have looked at 32-bit versus 64-bit performance in the past, and we will revisit it again in a few weeks, so today we will just focus on 32-bit performance.
Also keep in mind the GCC 3.3.3 included with SuSE 9.1 Pro has many back ported options from the official 3.4.1 tree. Our results with GCC 3.3.3 are much more optimized than the standard GCC 3.3.3.
We ran MySQLd 4.0.20d from 32-bit binaries precompiled by the SuSE team. The two benchmarks below are sql-bench's test-select and test-insert.


It is very likely there are a few different factors at work here that put the Socket 754 marks better than the lowly 1.8GHz Socket 462 Athlon 2200+. For starters, we have no doubt the on-CPU memory controller for the Socket 754 family plays a critical role in hastening selects and inserts. Our whole database is stored in memory, so the largest issue becomes IO from the CPU to the RAM. The nForce3 northbridge is also far superior to the nForce2 used on the Athlon 2200+ platform, which also accounts for some IO gains.
TSCP
You may recall from our Opteron 150 comparison that optimization flags heavily influenced performance in the benchmark. We wanted to run this test in a similar fashion to the way we did John The Ripper with three seperate configurations for compilation. Below you can see which flags we used for each "configuration" when compiling. The march flag used for the Sempron 3100+ was "k8"; using the "athlon" flag actually degraded performance.
- Configuration 1.) -O2
- Configuration 2.) -O3
- Configuration 3.) -O2 -march
- Configuration 4.) -O3 -march
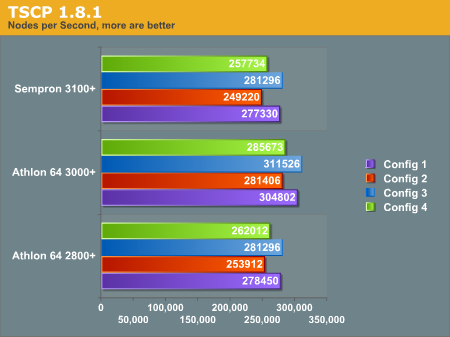
You may notice we did not include the Athlon XP processor in this portion of the benchmark. There are some optimizations somewhere in the program that gave us unusual results with GCC 3.3.3; we are looking into this problem.
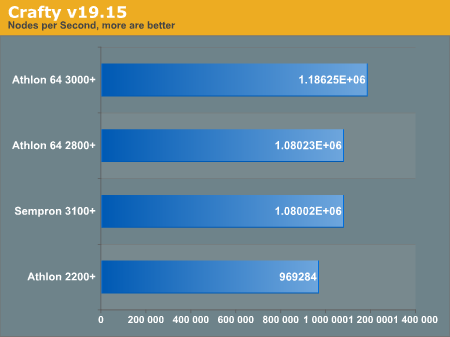
Crafty
Crafty v19.15 was included to keep our TSCP benchmarks sane. We used the standard "make linux" target. The benchmark was generated by running the "bench" command inside the program.
Mental Ray
Mental Ray 3.3.1 is still a 32-bit program, so even though we have tested it on 64-bit platforms in the past, it has and will continue to exist as a 32-bit program for our analysis.
We ran Mental Ray from the command line with the same benchmark file we have been using in the past.
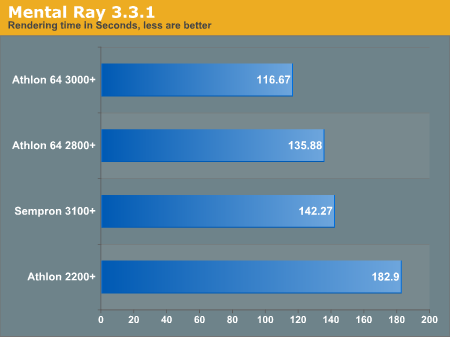
Mental Ray appears to be less L2 cache intensive than many of our other benchmarks. Although there is a scalable difference between the Athlon 64 2800+ and the Sempron 3100+, we see much faster times when we increase the clock and the cache, as seen on the Athlon 64 3000+.
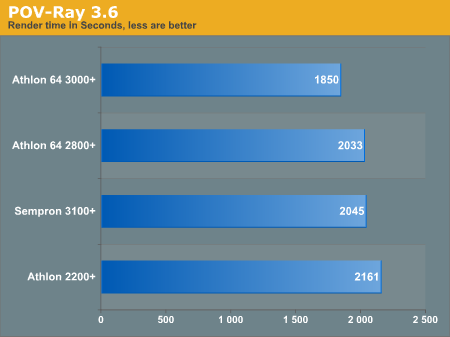
POV-Ray
We have had some discrepancies with POV-Ray 3.50c in the past, so from now on we are sticking to self compiled 3.6 binaries while running the official benchmark.ini. The program was compiled using the standard ./configure and make, with no induced optimizations.
Opstone
Blue Sail Software's Opstone benchmarks were used in this portion of the review. We will use the Athlon XP 32-bit precompiled optimized binaries of the Scalar Product (SP) and Sparce Scalar Product (SSP) benchmark. Unfortunately, this means the Athlon 64 does not receive the benifit of SSE2 in this benchmark. The SP benchmark is explained by the author:
"The 'SP' benchmark calculates the scalar product (dot product) of 2 vectors ranging in size from 16 elements to 1048576 elements for both single and double-precision floats. Although the Gflops/sec. for every vector length is recorded (in the resulting output log file), the average of all these values is reported. This benchmark is indicative of the performance of many raw floating-point data processing apps (movie format conversion, MP3 extraction, etc.)"
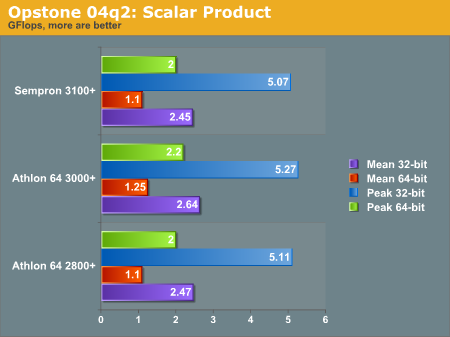
The integer intensity scalar product benchmark is relatively unscathed by the difference in L2 cache, with the exception of a slightly higher sustained mean GFlops.
Below is the SSP benchmark, as explained by the author:
"The 'ssp' benchmark also calculates the scalar product of 2 vectors, except that these vectors are sparsely populated (only the non-zero value elements are stored) ranging from a 'loading factor' (non-zero/zero elements) of 0.000001 to 0.01 for both single and double-precision floats. Since the data is not contiguous in memory, the performance is much lower than regular 'sp' and is measured in Mflops/sec. There is not much difference in performance between different loading factors as this benchmark really challenges the ability of the processor to perform short bursts of calculations coupled with lots of conditional testing. It is this reason that the P4 with its longer pipeline does not generally perform as well as the Athlon64. This benchmark is indicative of the performance of many 3D games as the processing is similar (short bursts of calculations with numerous conditional testing)"
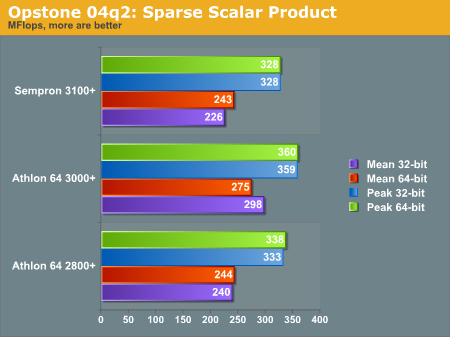
Floating point operation scales much better than integer processing if we are to trust Opstone. All three processors scale in the same order of their price range, although the AMD PR rating obviously does not hold on this benchmark.
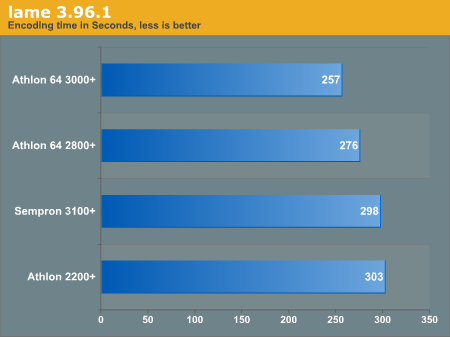
lame
We compiled lame 3.96.1 without any optimizations. We used the command below on a 700mb .wav file.
# lame sample.wav -b 192 -m s -h - >/dev/null
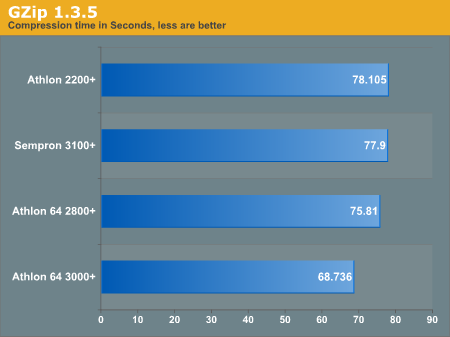
GZip
We used the SuSE 9.1 Pro i686 RPM for this portion of the analysis. The 700MB test file from the lame benchmark above was compressed and then timed using the command below.
# time gzip -c sample.wav > /dev/null
MEncoder
We compiled 1.0pre5 from source without any optimizations. The command we ran is below:
# time mencoder sample.mpg -nosound -ovc lavc vcodec=mpeg4:vpass=2 -o sample.avi
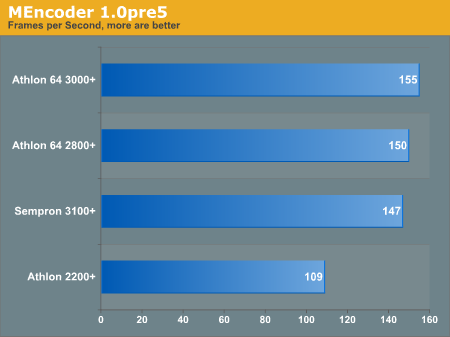
Generally, in all these benchmarks we only notice an increase of performance on the 2800+ from the 3100+ of a few percent, if that.
John The Ripper
We used John the Ripper (JTR) 1.6.37 as a loose benchmark of encryption/hashing. The 1.6 "stable" branch for JTR is actually very dated, so we used the much more updated 1.6.37 tree instead. There are fewer hand coded ASM routines in the 1.6.37 release which allows us to better directly compare our processors.
Just like the chess benchmarks from before, we used four different configurations to compile JTR. The first configuration is identical to "make linux-x86-any-elf" target.
- Configuration 1.) -O2
- Configuration 2.) -O3
- Configuration 3.) -O2 -march
- Configuration 4.) -O3 -march
Obviously, we used the athlon arch flag for the Athlon XP processor and k8 for the Athlon 64.
![John The Ripper 1.6.37 - DES [24/32 4K]](https://images.anandtech.com/graphs/linux and l2 cache sempron vs _081704110838/3577.png)
![John The Ripper 1.6.37 - Blowfish (x32) [32/64]](https://images.anandtech.com/graphs/linux and l2 cache sempron vs _081704110838/3578.png)
![John The Ripper 1.6.37 - MD5 [32/64 X2]](https://images.anandtech.com/graphs/linux and l2 cache sempron vs _081704110838/3579.png)
It is likely that JTR uses some optimized ASM code for the Athlon XP, which is why we see such good marks for a two year old CPU.
OpenSSL
The most comprehensive OpenSSL "speed" benchmarks can be downloaded as separate text files (Athlon 2200+, Athlon 64 3000+, Sempron 3100+) but we also provided some graphical mappings below.
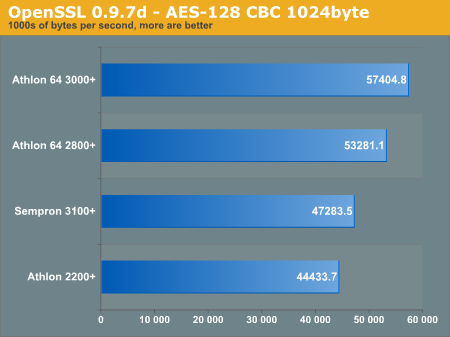
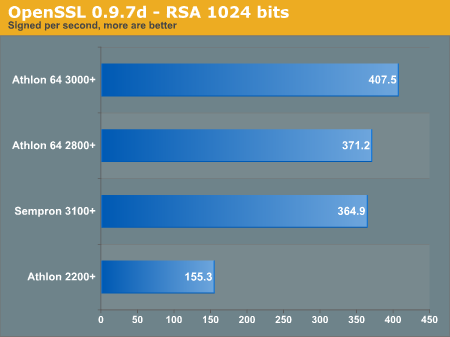
The AES speed test scales very well across AMD's budget computing line, and we really see the additional L2 cache increasing thoroughput. However, we go down one graph to see that signing RSA keys had very little performance increase with the 512KB L2 cache.
Conclusions
The first conclusion we came to without even really running any benchmarks. Primarily, the lack of 64-bit addressing on the Sempron 3100+ probably makes a bit of sense; the A64 2800+ and the Sempron 3100+ are both budget oriented processors - it is very unlikely anyone will utilize more than 4GB of memory on either processor. The real payoff of the Athlon 64 processors (the onboard memory controller) is found on both the Sempron and Athlon 64.
We also noted in our analysis that the Sempron 3100+ scored very similar performance marks to the Athlon 64 2800+; and it should. Both processors utilize 1.8GHz clock speeds and 130nm production, but the Sempron 3100+ only runs on half the L2 cache of the 2800+. Again, the only major functional differences we noticed between the two processors was the lack of 64-bit operation (with a few exceptions). That being said, at least on Linux, we cannot vouche for AMD's PR rating since the Athlon 64 3000+ lead the Sempron 3100+ in every single benchmark. AMD states the PR rating only compares the Sempron to the Celeron product line, but since Intel dropped the GHz rating on the Celeron chips months ago, that seems like a moot point.
On a cost analysis, the Sempron 3100+ packs a lot of punch for $130. We lose 64-bit addressing and the additional cache for $20 when compared to an Athlon 64 2800+, but as we saw in our benchmarks the cache only provided significant advantages on database and encoding applications - not something most people generally use a budget CPU for anyway. If you're looking to limit yourself to 32-bit computing on the Linux desktop, the Sempron 3100+ cannot keep up with an Athlon 64 3000+ or even a 2800+. However, the 10% cost savings between the 2800+ and the 3100+ is much better than the 2 to 5% decrease in performance we saw between the two processors.






