Original Link: https://www.anandtech.com/show/1685
The Quest for More Processing Power, Part Three: "Multi core of Intel and AMD compared"
by Johan De Gelas on May 18, 2005 3:15 PM EST- Posted in
- CPUs
Introduction
The Pentium-D dual core Pentium 4 and Opteron 875 dual core are launched. At the end of 2007, a quad core Whitefield CPU will be launched by Intel, and a quad core “K9” of AMD will make a stand against Whitefield. The multi core train has picked up speed and is unstoppable. But what will be the challenges ahead? What are the architectural advantages of the current cores? What will set the different architectures apart? Read on in this third part of The Quest for More Processing Power series.In case you missed it, in our first article, we explained that dynamic power, power leakage, the memory wall and wire delay have forced CPU designers to rethink the methods that they use to achieve higher performance CPUs.
In Part 2, Tim Sweeney, the leading developer behind the Unreal 3 engine, explained the challenges of multi-threaded development of the next generation of games.
The multi-core future...
In the past 15 years, architectural improvements have made sure that the Pentium 4 issues and retires about 6 times more integer instructions each clock cycle than an Intel 486 could on average. At the same time, the die size would have been 15 times bigger if there were no advancements in silicon process technology, and even those aggressive advancements could not avoid the fact that the Pentium 4 needs almost 20 times as much power.Clock speed increased from 33 MHz to 3800 MHz, so it is clear that clock speed, not extracting more ILP (Instruction Level Parallelism), has been the main reason why a Pentium 4 performs so much better than an i486.
However, the next generation of CPUs will be based on a completely different philosophy. The Xeon MP Version 2007, alias Whitefield, will have 4 cores, and run at speeds at around 2.6 GHz. At that speed, there are reports that it would consume less than 90 Watt. Intel will use its P-m “know-how” to keep the power dissipation so low. Each core is not really a P-m, but it is clear that the pipeline will be shorter than the one of Willamette, the first implementation of the Pentium 4’s Netburst architecture.
AMD’s K9 seems to be a slightly different beast. Andreas Stiller of C’t reported that this Quad core CPU monster would have a TDP of 140 Watt, and run at about 3 GHz.
So, it seems that clock speed will no longer drive performance, but higher IPC and more cores will.
Dual core Opteron versus Pentium-D and Dempsey
There is no doubt that the Dual core Opteron architecture is more advanced and elegant than the Pentium-D and even future Netburst based dual cores such as Dempsey (Xeon). The Pentium-D Dual core is more a way of packaging than an actual architecture: two cores cut out the wafer together, and communicate via an external FSB.With two different L1 and L2-caches, and two CPUs working on the same variables, you risk that one of the CPUs is working on an outdated cached value. You need to make sure that if variable A is cached on both CPUs, and CPU 1 changes the value of variable A, then CPU 2 knows about it. This happens with a protocol called MESI on the Intel CPUs and MOESI on the AMD CPUs. The discussion of these “cache coherency protocols” is outside the scope of this article, but you understand that the more variables that are shared between the two CPUs, the more communication that will happen between the caches of the different CPUs.
In the case of the Pentium-D, the caches talk to each other (to keep cache consistency) via a shared 800 MHz bus, just like two single core SMP Xeons. Not only is 800 MHz relatively slow compared to the CPU (3200 MHz), but exchanging information via a bus also increases latency and lowers bandwidth. Latency is increased as the bus may not always be free - one of the CPUs might be using it to transfer data to or from the memory. This half duplex bus can only transmit signals of one device (CPU 1, CPU 2, chipset) at a given moment. Bandwidth is decreased as the cache coherency exchanges need a small amount of time on the bus too.
Enter the elegant dual core Opteron architecture. Each core in the Dual Opteron/Athlon 64 X2 puts its request on the System Request Queue (SRQ).
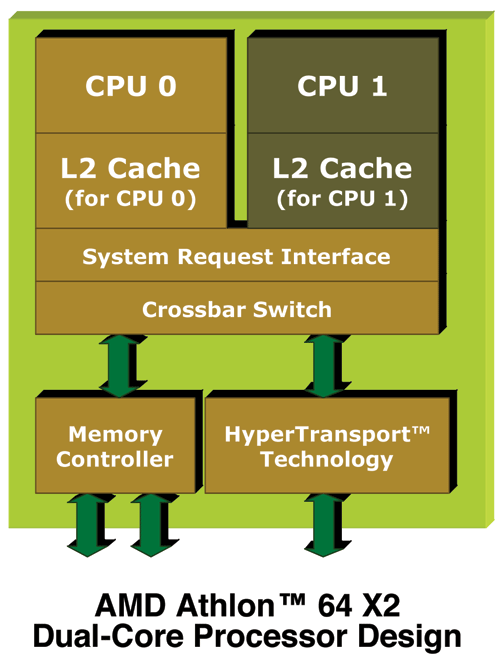
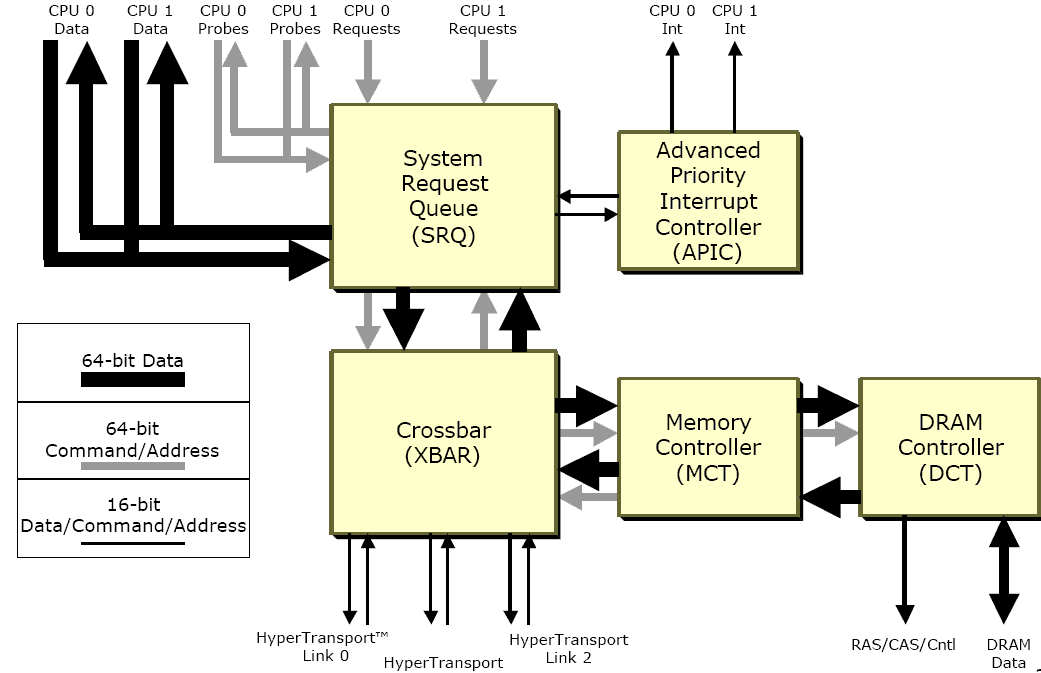
Click to enlarge.
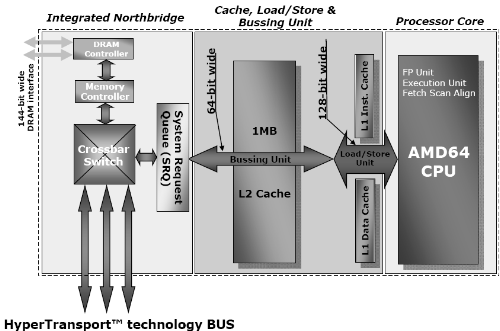
Measuring the Dual core
Michael S. started this extremely interesting thread at the Ace’s hardware Technical forum. The result was a little program coded by Michael S. himself, which could measure the latency of cache-to-cache data transfer between two cores or CPUs. In his own words: “it is a tool for comparison of the relative merits of different dual-cores.”Cache2Cache measures the propagation time from a store by one processor to a load by the other processor. The results that we publish are approximately twice the propagation time. For those interested, the source code is available here.
We disabled Hyper Threading on all Pentium 4 (except the first one) and Xeons, to make sure that we measure from one physical core to another.
| CPU configuration | Hyper Transport speed | Bus speed | Cache2Cache |
| Pentium 4 3.6 GHz with Hyperthreading | N/A | 800 MHz | 21 ns |
| Dual Opteron 2.4 GHz | 800 MHz | N/A | 159 ns |
| Dual Opteron 2.4 GHz (iwill) | 1000 MHz | N/A | 150 ns |
| Dual core Opteron 2.2 GHz to other Dual Core | 1000 MHz | N/A | 164 ns |
| One Dualcore Opteron 2.2 GHz (875) | 2200 MHz* | N/A | 107 ns |
| Quad Opteron 848 2.2 GHz (CPU0 to CPU2) | 800 MHz | N/A | 240 ns |
| XeonDP (Prestonia) 2.8GHz | N/A | 400 MHz | 297 ns |
| Dual Xeon 3.06 (Gallatin) | N/A | 533 MHz | 219 ns |
| Dual Xeon 3.2 GHz (Nocona) | N/A | 800 MHz | 242 ns |
| Pentium-D (dual core) | N/A | 800 MHz | 240 ns |
| Dual Xeon 3.6 GHz (Nocona) | N/A | 800 MHz | 244 ns |
The Pentium-D (3.2 GHz) has no cache-to-cache latency advantage whatsoever over similar dual Xeon (Nocona 3.2 GHz) configurations. The Dual Opteron exchanges information no less than 60% faster than a similar Dual Xeon or Pentium-D. In case of the dual Opteron, cache coherency transfers are done via Hypertransport and the 1 GHz Hypertransport connection delivers 6% lower latency than the 800 MHz one.
Dual Core Opterons perform cache-to-cache transfer via the SRQ and it shows. The latency is another 40% lower than the Dual Opteron with the fastest Hypertransport connection, and more than twice as fast as the Pentium-D!
From the data available, we can also calculate the latency of the Hypertransport channel between two (single core) Opterons. In case of an 800 MHz link, you get (159 – 107 ns)/2 or about 26 ns. A 1000 MHz link takes about (150-107 ns)/2 or about 21.5 ns. Typically, a local memory access from the Opteron to its closest or local memory banks takes about 50-60 ns. Therefore, a remote memory access (CPU 1 goes to the local memory of CPU 2) should take roughly 80 ns (20 ns + 60 ns).
We have measured between 100 and 120 ns for a Xeon system, so it seems that the Opteron in a dual configuration is capable of accessing remote memory quicker than the Xeon can via the shared bus.
Back to our main focus: the dual core Opteron cache-to-cache latency is vastly superior compared to any dual core netburst CPU. Can this huge advantage – when measured with a micro bench – translate into a performance boost in a real world application?
And in the Real world?
Before I wrote this article, Anand told me that he was already testing with a lot of applications to see if the superior dual core architecture of the Opteron/Athlon 64 x2 could make performance scale better from one single core to a dual core CPU in a real world application. So far, he found out that multithreaded 3D rendering and video encoding applications don’t show any scaling advantages for the Opteron. I couldn’t find any either when testing read performance on database servers (DB2, MySQL MyISAM). But as you will see further, that is not a surprise and it doesn’t mean that there is no performance benefit whatsoever.The problem is that most of the current multi-threaded software, especially on the desktop, are developed with the objective of minimizing messaging between threads and synchronization between caches. You could say that only the “easy to thread” part of most current programs are divided in many threads.
Although we have a lot of testing to do, we can be pretty sure that there are applications out there that do benefit from very fast cache-to-cache transfers.
OLTP (On-Line Transaction Processing) applications might be one type of software to benefit significantly. A good example of an OLTP application is a bank account database application. Imagine two clients sending two different updates of a bank account. One transaction wants to add your salary to the current balance in your bank account, while the other transaction wants to decrease it with the purchase that you just made.
The machine on which the OLTP application is running is a dual CPU system. Both CPU have the current balance of your account in their caches, and each CPU gets to perform one of the described transactions. It is pretty clear that the first transaction has to finish before the new one starts; otherwise, the second result (current balance – purchase) will simply overwrite the first calculation (current balance + salary). So, the row that contains the current balance of your bank account must be locked by the first CPU, and read out. The second CPU must now know that it cannot use that variable anymore (CPU 1 tells CPU 2 to flush that cacheline or mark it as invalid) because it is about to change. A calculation is performed and written back to the memory. New value is communicated to CPU 2, and the row is unlocked if everything is OK. The second CPU now performs the second calculation, based on the updated balance. This example is simplified, but notice that the CPU must talk quite a bit to each other.
A database application where this frequent locking, reading, writing, and unlocking will most likely show the superior cache-to-cache transfer latency of the Opteron…if it is not bottlenecked by the speed of memory and/or the storage system.
Basically, we could say that the databases that lock on the table level (MySQL MyISAM) will not show any performance advantage. Table level locking is fast, and produces little overhead as long as you do not update (write) the values in your database often. If you write a lot to your database, the database will be terribly slow. These kinds of databases will not care about the dual core architecture.
However, database engines (DB2, Oracle, MySQL Innodb) with a much finer locking grain (row level) produce a lot more overhead, but will perform better when many writes are mixed with reads. These types of database engines will be much more sensitive to the dual core architecture. Again, that will be the case if the storage or memory system is not the bottleneck and the CPU is.
Another example might be a scanline renderer (each line of pixels to render is sent to a different CPU) where the render time per line is very short. This would mean that a lot of time is spent keeping track of which CPU has to be given which line and so on, and this requires a lot of synchronization between the two caches.
Some HPC applications where threads perform calculations on shared data might also show significantly better scaling on the dual core Opteron.
In general, the more time that a program spends in synchronisation and passing messages, and the shorter the computation time on each CPU, the worse that the multi threaded program scales on SMP configurations. However, those applications are exactly the ones where the dual core Opteron is going to show scaling advantages compared to the Pentium-D and Xeons.
We’ll report back with some real world benchmarks.
SMT Dead?
Simultaneous Multi Threading has been receiving quite a bit of criticism over the past months. Rumours about the demise of Hyper Threading were started, and Fred Weber of AMD even called it "a misuse of resources".The reason why SMT was no longer considered "cool" was because of the very mediocre performance increase that the Pentium 4 gained from Hyper Threading. In fact, we are still encountering applications where Hyperthreading decreases performance.
Anand reported in his "AMD's Athlon 64 X2 4800+ & 4200+ Dual Core Performance Preview":
"The other thing we continue to see is that dual core with Hyper Threading in these multitasking environments is very much the double-edged sword. There are some situations where having both Hyper Threading and dual core gives Intel a huge performance boost, but there are others where the exact opposite is true. As it currently stands, we're not sure how much of a future Hyper Threading will have in future Intel architectures - but it's definitely not a sure win."One of the upcoming AnandTech projects, a Database server comparison on SUSE Linux 9 SP1 (Kernel 2.6.x), is showing similar results - Hyper Threading decreases database read performance by 1% to 6% in many cases.
Why Hyperthreading fails to impress...
The current form of SMT [1] in the Pentium 4 is quite mediocre, but SMT is not going to disappear. The Netburst architecture is simply not well suited for SMT, and Intel implemented Hyper Threading with the goal of minimizing the die area cost. Only a few small structures were replicated - the die area cost was less than 5% of the total die area of the Pentium 4 (Northwood).The whole idea behind SMT is to execute two (or more) threads at the same time, on the same processor. Normally, a CPU will execute one thread, switch context (save the contents of the registers and CPU state in the cache), and then load the registers for another thread and execute it. The main objective is that a second thread would use the execution units that one thread cannot use at the moment, and vice versa. This implies a wide issue superscalar CPU; in other words, a CPU that is capable of executing many instructions in parallel.
And the Pentium 4 is hardly a wide issue superscalar CPU. It has only 4 execution ports: one Load, one store and two for executing either FP or integer instructions. In the best case, you are using the double-pumped ALU attached to these two ports, and you can achieve a burst of 6 instructions in one clock cycle: 4 additions on the 2 double-pumped ALUs, a load and a store. But the chances that you find 4 independent additions are relatively small.
The trace cache is only capable of delivering 6 micro-ops every two cycles. Those 6 micro-ops are on average about 4 x86 instructions. So, in reality, the Pentium 4 will rarely be able to sustain more than 2 x86 instructions per clock cycle. That is fine for a single threaded CPU. We measured with Intel's Vtune that, for example, an FP intensive program such as Povray is running at an IPC of 0.8-0.9, while Database applications (integer intensive) runs at IPC ranging from 0.3 to 0.5. So, an IPC of 2 is more than enough...for a single threaded CPU, that is!
While Intel's engineers designed the Hyper Threading on the Pentium 4, they made sure that one stalled logical processor would not make the other logical processor stop too. Cache misses and handling branch mispredictions might cause the first logical CPU to fill up buffering queues so that the second logical CPU has no room to run.
Therefore, some buffers and queues are effectively cut in half when you run two threads. Below, you can see how some buffers are shared dynamically between two threads and some are simply cut in two.
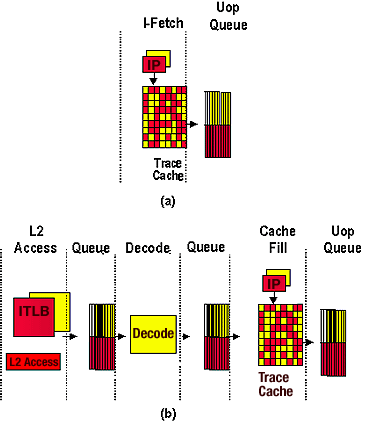
...and why SMT can be impressive!
If you want to know what is going to happen in the future, it is always a good idea to look at the big iron. After all, many of the techniques that are now popular in low budget x86 CPUs originated from there: SIMD (Cray-1, ILLIAC IV), 64 bit (MIPS R4000) and CMP (IBM Power 4) are just a few examples.
This SMT makes much more effective use of processor resources than multi-core. If only one thread is running, and there is a lot of instruction level parallelism, it has all the execution resources to its disposal and the CPU acts as a massive parallel superscalar CPU. If two or more threads are running, they can make optimum use of the available execution slots. For each percentage that the die size increases, SMT gives you more than one percentage of performance back. In contrast, a second core doubles the die size, but rarely improves performance with more than 70%. SMT can be a superb feature to boost the performance of a multi-core CPU without increasing the die size too much.
Bringing it all together...
Intel and AMD are playing different trump cards while getting their next generation of quad core designs ready for the server market. It is clear, however, that clock speed will only increase slowly, and will no longer be the most important performance indicator.Intel can leverage their experience with the power saving features of the P-m to design quad core CPUs with remarkably low TDP. SMT might well be one of Intel’s most important weapons to enable relatively high IPC per core. The fact that the current implementation called Hyperthreading offers only mediocre performance improvements is not a reason to believe that SMT will not have a bright future. SMT added to a high IPC core might even give Intel the edge in the server market. The shared L2-cache in the next generation multi-core CPUs (Merom, Conroe, Woodcrest, Whitefield) should also eliminate Intel’s high cache to cache latency.
AMD’s current dual core architecture is vastly superior to Intel’s. The more than twice as fast cache-to-cache communication does not pay off in all multithreaded applications, but it should give AMD a scaling advantage in OLTP and some rendering and HPC applications. It will be very easy for AMD to make communications between the cores even faster, by attaching a shared L2-cache to the SRQ. AMD can also leverage their knowledge and experiences with the on die northbridge to lower the latency and increase the bandwidth of the memory subsystem.
I like to express my thanks to the following people who helped to make this article possible:
- Michael S.
- Matty Bakkeren, Trevor E. Lawless, Markus Weingartner and Christian Staudinger (Intel)
- Anand Lal Shimpi
- Chris Rijk (Ace’s hardware)
- David Van Dromme (Iwill Benelux Helpdesk)
- Ruben Demuynck (Technical University Kortrijk)
References
[1] Hyper-Threading Technology Architecture and Microarchitecturehttp://www.intel.com/technology/itj/2002/volume06issue01/art01_hyper/p01_abstract.htm






