Original Link: https://www.anandtech.com/show/2183
Barcelona Architecture: AMD on the Counterattack
by Anand Lal Shimpi on March 1, 2007 12:05 AM EST- Posted in
- CPUs
Introduction
Over the past several years, Intel has followed an odd path of microprocessor design. On the heels of the success of the P6 core, Intel set two teams in motion - one to work on the NetBurst architecture that would be the foundation of the Pentium 4, and one to work on a low-cost, low power highly integrated core that would eventually be redesigned into the Pentium M. The team eventually charged with designing the Pentium M took a more evolutionary approach building off of the strengths of the P6 architecture, while the NetBurst team preferred a radical departure from Intel's previously most successful architecture at the time.
We all know how this story ends; as NetBurst evolved, so did the underlying architecture of the Pentium M. Dothan was the first tweak of the Pentium M and it was mostly a clean up job to fix some performance issues with the original core. Higher clock speeds, more cache, and slight increases in IPC were on Dothan's CV.
Intel's Israel Development Center (IDC) then took Dothan and re-architected it to be a native dual core solution, complete with a shared L2 cache, the first of its type for an Intel processor. The Dothan to Yonah progression was far more significant than the move from Banias to Dothan, not just because Yonah was dual core but also because of the many architectural improvements that went into Yonah.
The next step Intel took is one we're all familiar with, and involves the most radical design change of the Pentium M's short lived history; Intel took Yonah and made it wider, deeper, and far more efficient. Out came the Core 2 line of processors and with it, Intel regained the undisputed performance crown it hadn't seen ever since the debut of AMD's Athlon 64.
While many argued that Banias, the first Pentium M core, was merely a modern take on the P6 architecture it's hard to see much in common between today's Core 2 and the 11 year old Pentium Pro. The P6 core was a starting point for a long line of evolution that brought Intel to where it is today.
AMD took a far more conservative approach over the past several years; it all started with the success of the K7 core, effectively a wider, faster, competitor to later versions of Intel's P6 architecture. While one of Intel's teams was busy making radical departures from anything AMD or Intel had done in the past, AMD didn't have the luxury of running two large scale microprocessor projects in tandem. The solution was to take the K7 core and improve on it, rather than taking a risky step in a different direction.
The K8 core was born as an evolution of the K7; with a slightly deeper pipeline, slight architectural improvements and an integrated Northbridge, the K8 was a pretty major evolutionary step for AMD over the K7. In fact, it took the Core 2 Duo to truly outperform the K8 core across the board, although Dothan and Yonah came quite close in certain applications.
AMD had worked on dramatic successors to the K8, rumored to be K9 and K10, but both appeared to be scrapped or at least focus was shifted away from them in favor of a more evolutionary take on the K8 architecture. The main difference here that allowed Intel to catch up to AMD's performance is that while Intel's Pentium 4 team was operating on the usual schedule of a 5-year micro-architecture cycle, the Pentium M team at IDC was updating its architecture every year. Banias, Dothan, Yonah and Merom/Conroe all happened in a period of four years, and during that same time AMD's K8 remained unchanged.
If Intel had continued down the Pentium 4/NetBurst route, sticking to the usual 5-year design cycle would have probably worked just fine for AMD but Intel had the luxury of having two major micro-processor teams working in parallel, one of which had a much better idea. Luckily it would seem that AMD realized it needed to compete with Intel using smaller evolutionary steps every couple of years rather than leaving an architecture relatively untouched for 4 - 5 years and thus the Barcelona project was created. Although it's set to debut around a year after Intel's Core 2 Duo that swiped the performance crown, Barcelona is AMD's best chance at remaining competitive.
Barcelona's window of opportunity is slim, depending mostly on how Intel's transition to 45nm goes. Publicly Intel has stated that its architectural update to Core 2, codenamed Penryn, will begin shipping by the end of 2007. However, current roadmaps show availability at sometime in 2008 with no word on when significant quantities will be available. Should Intel take longer than expected with the move to its 45nm Penryn core, Barcelona's mid-2007 launch on servers and Q3 '07 launch for desktops may come at a relatively quiet time for Intel.
The Chip
Barcelona is AMD's first quad-core processor, featuring four cores on a single 65nm die. Unlike Intel's quad-core Kentsfield, Barcelona is not made up of two dual core die, which is why AMD calls it a "native" quad core solution. Although there is a technical performance advantage to AMD's approach, we're unsure if it's something that will be visible in real world testing.
Built on AMD's 65nm process, Barcelona is a more complex design than the K8 requiring a total of 11 metal layers compared to 9 for K8 and 8 for Core 2. AMD has required more metal layers at the same process generation than Intel in previous years, so Barcelona is not unique. Additional metal layers make manufacturing a bit more complicated, but there are no significant downsides to the end user.

With four cores and an optional 2MB of L3 cache on-die, Barcelona weighs in at 463 million transistors. At 463 million transistors, Barcelona is 119 million transistors shy of Kentsfield's 582M count. The lower transistor count boils down to a lack of cache; each Barcelona core has a 128KB L1 cache and a 512KB L2 cache, with all four cores sharing a 2MB L3 cache, for a total of 4.5MB of cache on-die. Each of the two die that compose a single Kentsfield have two cores, each core with its own 64KB L1 and a shared 4MB L2. A single Kentsfield chip has a total of 8.25MB of cache on-die, over 80% more than Barcelona, thus explaining the 25.6% increase in transistor count.
However, Barcelona is far more than a quad-core K8 with an L3 cache. We estimate the number of non-cache transistors in a dual-core Athlon 64 X2 to be approximately 94M, and the Barcelona core is around 247M; even doubling the dual-core K8 figure won't get you close to Barcelona. Note that simply doubling the 94M number also isn't an accurate comparison as Barcelona only features a single on-die Northbridge. In essence, there are more than 60M additional transistors (or more than 15M per core) that went into architectural enhancements outside of more cores and cache in Barcelona.
SSE128
| AMD Architecture Comparison | ||
| K8 | Barcelona | |
| SSE Execution Width | 64-bit | 128-bit |
| Instruction Fetch Bandwidth | 16 bytes/cycle | 32 bytes/cycle |
| Data Cache Bandwidth | 2 x 64-bit loads/cycle | 2 x 128-bit loads/cycle |
| L2/Northbridge Bandwidth | 64 bits/cycle | 128 bits/cycle |
| FP Scheduler Depth | 36 Dedicated x 64-bit ops | 36 Dedicated x 128-bit ops |
Many of the "major" changes to Barcelona were driven by one significant change: what AMD is calling SSE128. In the K8 architecture AMD can execute two SSE operations in parallel; however the SSE execution units are only 64-bits wide. For 128-bit SSE operations, the K8 had to handle them as two 64-bit operations. This also means that when a 128-bit SSE instruction is fetched, it is first decoded into two micro-ops (one for each 64-bit half of the instruction), thus taking up an extra decode port for a single instruction.
Barcelona widens the execution units that handle SSE operations from 64-bits to 128-bits, so now 128-bit SSE operations don't have to be broken up into two 64-bit operations. This also means that you get more usable decode bandwidth since 128-bit SSE instructions now map to a single micro-op instead of two. The FP scheduler can now handle these 128-bit SSE operations as well.
It's the increase to SSE execution width that drove a number of other changes within the core. Since you effectively have more decode bandwidth when executing 128-bit SSE instructions AMD discovered a new bottleneck: instruction fetch bandwidth. These 128-bit SSE instructions tend to be quite large, and in order to maximize the number decoded in parallel the Barcelona core can now fetch 32-bytes per cycle, up from 16-bytes in K8. The 32B instruction fetch not only benefits SSE code but also seems to benefit integer code as well. Bigger instructions in general will see a performance boost here.
Now that you can fetch and decode more instructions, you need to be able to get more data to the execution core and thus AMD widened the interface between the L1 data cache and Barcelona's SSE registers. Barcelona can now perform two 128-bit SSE loads per cycle from the L1-D cache compared to two 64-bit loads per cycle in K8. AMD then widened the interface between the L2 cache and the memory controller so that now 128-bits can be transferred per cycle, once again to balance out all of the aforementioned changes.
The culmination of the SSE128 improvements is very similar to some of the changes made in the Yonah to Merom transition. Prior to Conroe/Merom, Yonah could not keep up with AMD's K8 when it came to FP/SSE performance. Almost a year and a half ago we did an article where we compared AMD's K8 to Intel's Yonah running at the same clock speed. While Yonah was able to equal the K8's performance in general applications, professional 3D rendering and games, it could not compete when it came to video encoding.
There were a number of SSE performance improvements made to Yonah but it wasn't until Intel's Core 2 processors that Intel was really able to outperform AMD in our video encoding tests. Whether the improvements were due to the single cycle SSE throughput introduced in Core 2 or the wider front end or a combination of both remains to be seen. Although it's difficult to compare specs between two very different architectures, encoding performance is a sore spot for AMD today, and it's something that the SSE128 changes can only help.
Core Tune-up
While the most significant sounding improvements were rolled into the SSE128 changes in Barcelona, they are merely the tip of the iceberg. The laundry list of improvements to Barcelona starts with the branch predictor.
In general, the accuracy of a CPU's branch predictor determines how wide and how deep of a design you can make. The average number of instructions before the predictor mispredicts governs how many instructions you can have in flight, which in turn controls how many execution units you can realistically keep fed on a regular basis. The K8's branch predictor was quite good and very well optimized for its architecture, but there were some advancements Intel introduced in the Pentium M and Pentium 4 that AMD could stand to benefit from.
Barcelona adds a 512-entry indirect predictor which, believe it or not, predicts indirect branches. An indirect branch is one where the target of the branch is a location pointed to by an address in memory, in other words, a branch with multiple targets. Instead of branching directly to a label indicated by the branch instruction, an indirect branch sends the CPU to a memory location that contains the location of the instruction that it should branch to.
Intel added an indirect predictor to its Pentium M processor based on the idea that the more you could limit the number of mispredicted branches, the more efficient your processor could be (thus lowering power consumption). The indirect predictor also made its way into Prescott in order to help minimize the performance deficit incurred by further pipelining the NetBurst architecture.
In Prescott, the simple addition of an indirect predictor resulted in over a 12% reduction in mispredicted branches in SPEC CPU2000. While details of how AMD and Intel differ in their predictor algorithms aren't public, we can expect similarly large improvements in areas where indirect branches are common. In the 253.perlbmk test of SPEC CPU2000 the reduction in mispredicted branches with Prescott was significant, reaching almost 55%. With Barcelona, fewer mispredicted branches means higher overall IPC and greater efficiency both from a power and performance standpoint. AMD doesn't have the incredibly deep pipeline to worry about that Intel did with Prescott, but the efficiency improvements should be significant.
The inclusion of an indirect predictor wasn't the only crystal ball improvement in Barcelona; the size of the return stack in the new core is double what it was in K8. In very deep call chains, for example code that calls many subroutines (e.g. recursive functions), the CPU will eventually run out of room to keep track of where it has been. Once it starts losing track of return addresses, it loses the ability to predict branches involved with those addresses. Barcelona helps alleviate the problem by doubling the size of the return stack. These sorts of improvements are generally implemented by profiling the behavior of software commonly used on a manufacturer's CPU, so we asked AMD what software or scenario drove this improvement of Barcelona. AMD wouldn't give us a concrete example of a situation other than to say that the return stack size improvements were made at the request of a "large software vendor".
The final improvement to the K8's branch prediction came through the usual channels - Barcelona now tracks more branches than its predecessor. There's no mystic science to branch prediction; a processor simply looks at branches it has taken and bases its predictions on historical data. The more historical data that is present, the more accurate a branch predictor becomes. When the K8 was designed it was built on a 130nm manufacturing process; with the first incarnation of Barcelona set to debut at 65nm AMD definitely has the die space to track more branch history data.
Sideband Stack Optimizer
Intel's very first Pentium M introduced a feature Intel called its dedicated stack manager. As its name implies, the dedicated stack manager was used to handle all x86 stack operations (i.e. push, pop, call, return). The purpose of the stack manager was to keep those stack operations, which are frequently used with function calls in code, separate from the rest of the x86 instruction stream sent to the CPU. The dedicated stack manager would handle decode and "execution" of these operations so that they wouldn't clog up the processor's decoders and execution units later in the pipeline. Intel essentially "widened" the core by offloading some operations to separate hardware.
With Barcelona, AMD is introducing a similar technology it is calling a Sideband Stack Optimizer. Stack instructions no longer go through the 3-way decoder and stack operations no longer go through the integer execution units, effectively widening Barcelona at minimal cost. The Sideband Stack Optimizer, like Intel's dedicated stack manager, features its own adder that handles all stack operations. It's a small tweak that can help overall performance, and it's simply one that made sense for AMD to implement.
Faster Loads
When looking at the performance of the Athlon 64 and Intel's Core 2 processors, it's easy to understand why Intel has a strong performance advantage in applications that make heavy use of SSE. But what about applications like gaming and business apps that should greatly benefit from AMD's on-die memory controller? Is the Core 2's larger L2 cache and aggressive prefetchers all that it needs to overcome AMD's on-die memory controller?
One major aspect of Intel's Core micro-architecture advantage is its ability to allow load instructions to bypass previous load and store instructions. On average, about 1/3 of all instructions in a program end up being loads, thus if you can improve load performance you can generally impact overall application performance pretty significantly. With Intel's Core micro-architecture, it's possible for loads to be re-ordered to ensure that instructions dependent on those loads get the data they need without waiting for costly memory accesses.
Core also allowed for loads to be moved ahead of stores, which was previously not allowed due to the possibility that an earlier store could invalidate the data that was just loaded. Intel figured that the possibility of a store writing over a load ends up being very small, on the order of 1 - 2%, therefore with a reasonably accurate predictor you could correctly guess when re-ordering a load ahead of a store was possible. Intel's Core 2 based processors feature prediction logic to guess whether a store and a load share the same memory address; if the predictor determines that they won't, then it allows the load to be re-ordered ahead of the store. In the small chance that the predictor is incorrect however, the load has to be redone at the cost of a pipeline flush (similar to what happens if the processor mispredicts a branch).
AMD's K8 architecture had no equivalent scheme for allowing the out of order execution of loads ahead of other loads and stores, so even without an on-die memory controller Intel was able to execute some memory operations faster than AMD. Barcelona fixes this problem through an almost identical scheme to what Intel implemented in its Core 2 processors.
Barcelona can now re-order loads ahead of other loads, just like Core 2 can. It can also execute loads ahead of other stores, assuming that the processor knows that the two don't share the same memory address. While Intel uses a predictor to determine whether or not the store aliases with the load, AMD takes a more conservative approach. Barcelona waits until the store address is calculated before determining whether or not the load can be processed ahead of it. By doing it this way, Barcelona is never wrong and there's no chance of a mispredict penalty. AMD's designers looked at using a predictor like Intel did but found that it offered no performance improvement on its architecture. AMD can generate up to three store addresses per clock as it has three AGUs (Address Generation Units) compared to Intel's one for stores, so it would make sense that AMD has a bit more execution power to calculate a store address before moving a load ahead of it.
The out of order load execution improvements to Barcelona should prove to be even more effective than they were in Core 2 given that AMD previously couldn't do any reordering of loads before the Int/FP schedulers whereas Core Duo could do a limited amount of re-ordering.
Even More Tweaks
Translation Lookaside Buffers, TLBs for short, are used to cache what virtual addresses map to physical memory locations in a system. TLB hit rates are usually quite high but as programs get larger and more robust with their memory footprint, microprocessor designers generally have to tinker with TLB sizes to accommodate. With K8 AMD increased the size of its TLBs over K7, and with Barcelona AMD is repeating the process once more.
Barcelona's TLBs are slightly larger than K8's, but they now include support for 1G pages which are useful for database applications and virtualized workloads. AMD also introduced a 128 entry 2M L2 TLB with Barcelona, once again to help cope with newer programs using larger page sizes. The TLB improvements to Barcelona won't make any sort of tangible impact on desktop applications, but enterprise performance should improve in server applications with large memory footprints.
When Intel introduced its second Pentium M, codenamed Dothan, one of the enhancements made was a lower integer divide latency. Although details at the time are slim, AMD has indicated that it has moved to reduce integer divide latency in Barcelona as well. We're not sure if the changes implemented are similar in any way to what Intel did with Dothan, but don't expect the performance improvement to be vastly noticeable in real world applications. It's one of those tweaks that will add up to overall more efficient execution but not one that's going to give you double digit performance gains across the board.
In another attempt to effectively "widen" Barcelona without committing a significant amount of transistors to doing so, AMD took a couple of instructions that were microcoded and turned them into fastpath decode instructions. A microcoded instruction takes significantly longer to decode than an instruction able to go through one of the core's fastpath decoders. CALL and RET-Imm instructions are now fastpath, which is a part of Barcelona's sideband stack optimization enhancements. MOVs from SSE registers to integer registers are now fastpath as well.
While on the topic of instructions, AMD also introduced a few new extensions to its ISA with Barcelona. There are two new bit manipulation instructions: LZCNT and POPCNT. Leading Zero Count (LZCNT) counts the number of leading zeros in an op, while Pop Count counts the leading 1s in an op. Both of these instructions are targeted at cryptography applications.
AMD also introduced four new SSE extensions: EXTRQ/INSERTQ, MOVNTSD/MOVNTSS. The first two extensions are mask and shift operations combined into a single instruction, while the latter two are scalar streaming stores (streaming stores that can be done on scalar operands). We may see some of these same instructions included in Penryn and other future Intel processors.
A Faster Memory Controller
When AMD integrated a memory controller on-die, we knew that every time we saw a new AMD processor, we'd get a slightly enhanced memory controller. In Barcelona, the tweaks are significant and should provide for a tangible improvement in memory performance.
One strength of Intel's FB-DIMM architecture used in Xeon servers is that you can execute read and write requests to the AMB simultaneously. With standard DDR2 memory, you can do one or the other, and there's a penalty for switching between the two types of operations. If you have a fairly random mixture of reads and writes you can waste a lot of time switching between the two rather than performing all of your reads sequentially then switching over to writes. The K8's memory controller made some allowances for preferring reads over writes since they take less time, but in Barcelona the memory controller is far more intelligent.
Now, instead of executing writes as soon as they show up, writes are stored in a buffer and once the buffer reaches a preset threshold the controller bursts the writes sequentially. What this avoids is the costly read/write switch penalty, helping improve bandwidth efficiency and reduce latency.
The K8 core (Socket-940/939/AM2) featured a single memory controller that was 128-bits wide, but in Barcelona AMD has split up the DRAM controller into two separate 64-bit controllers. Each controller can be operated independently and thus you get some improvements in efficiency, especially when dealing with quad core implementations where the individual cores working on independent threads all have their own memory access patterns.
Barcelona's Northbridge is also set up to handle higher bandwidth than before. Deeper buffers are present, allowing for higher bandwidth utilization, and the Northbridge itself is ready for use with future memory technologies (e.g. DDR3). We'd expect one or two revisions past Barcelona will be when AMD switches memory technologies, but the new core will initially debut with DDR2 support.
New Prefetcher
Prefetching is done in many areas of the system and by many different components. When NVIDIA introduced its nForce2 chipset, it stressed the ability of its intelligent prefetcher to make use of a very wide, at the time, 128-bit memory bus. More recently, when Intel introduced its Core 2 processor family it stressed the importance of its three prefetchers per core in drastically reducing perceived memory latency.
AMD's K8 core had two prefetchers per core - one instruction and one data. The Barcelona core still retains the same number of prefetchers, but improves on them. The biggest change is that the data prefetcher now brings data directly into the L1 data cache, as opposed to the L2 cache in the K8. AMD looked at the accuracy of its core prefetchers and realized that they were doing quite well, so it only made sense to prefetch into a low latency L1 and avoid polluting the L2 cache. AMD has also increased the flexibility of its L1 instruction cache prefetcher to handle two outstanding requests to any address.
At first glance it looks like Intel's prefetchers in Core 2 are greater, at least in quantity, than what AMD has planned even for Barcelona. Remember that Intel's Core 2 processor features two data and one instruction prefetcher per core, plus an additional two L2 cache prefetchers, all of which are well managed as to not eat into "demand" bandwidth. At the same time, we must keep in mind that Intel needs these prefetchers to help mask its longer trip to main memory. From a CPU perspective, the advantage here is for Intel, but as a platform the true winner is tough to determine.
Each Barcelona core gets its own set of data and instruction prefetchers, but the major improvement is that there's a new prefetcher in town - a DRAM prefetcher. Residing within the memory controller where AMD previously never had any such logic, the new DRAM prefetcher takes a look at overall memory requests and attempts to pull data it thinks will be used in the future. As this prefetcher has to contend with the needs of four separate cores, it really helps the entire chip improve performance and can do a good job of spotting trends that would positively impact all cores. The DRAM prefetcher doesn't pull data into the CPU's L2 or L3 caches either; instead it features its own buffer to avoid polluting the caches. The buffer is approximately 20 - 30 cache lines in size and happens to be the same buffer that is used for Barcelona's write bursting we mentioned on the previous page.
Getting Spendy with Transistors - L3 cache
AMD lost the cache race to Intel long ago, but that's more of a result of manufacturing capacity than anything else. AMD knew it could not compete with Intel's ability to churn out more transistors on smaller processes faster, so it did the next best thing and integrated a memory controller. With the K8's on-die memory controller, AMD reduced the need for larger caches, which is why even current Athlon 64 X2s only have a 512KB L2 cache per core - a figure that Intel introduced back in 2002 with its Northwood core.
These days two Core 2 cores share up to 4MB of L2 cache, while the fastest offerings from AMD weigh in at half that. The gap will continue to widen with Barcelona, as each of its four cores will only have a 512KB L2 cache. While a quad-core Barcelona chip will have 2MB of total L2 cache for all four cores, a quad-core Kentsfield currently has 8MB of L2 cache for all four cores. By the end of this year, Intel's Penryn is expected to have 12MB of L2 cache for all of its cores.
In order to keep die sizes manageable, AMD constructed its quad-core Barcelona out of four cores each with a 128KB L1 and 512KB L2, much like most mainstream K8 based products today. However, the era of multithreaded applications demands that multi-core CPUs should have some common pool of high speed memory to keep them running at peak efficiency.
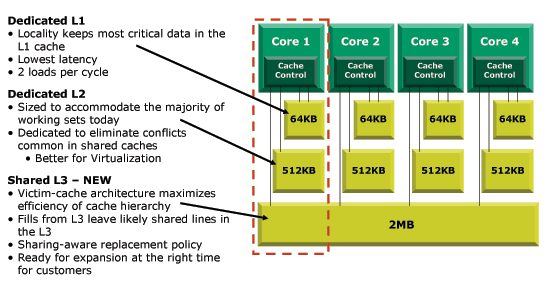
With four cores sharing a single die, AMD didn't want to complicate its design by introducing a large unified L2 cache. Instead, it took the K8 cache hierarchy and added a third level of cache to the mix - shared among all four cores. At 65nm, a quad-core Barcelona will have a 2MB L3 cache that is shared by all four cores.
The hierarchy in Barcelona works like this: the L2 caches are filled with victims from the L1 cache. When a cache gets full, data that was not recently used is evicted to make room for new data that the cache controller determines is good to keep in the cache. In a victim cache structure, the evicted data is placed in a storage area known as a victim cache instead of being removed from cache all together. If the data should become useful again, the cache controller simply has to fetch it from the victim cache rather than much slower main memory; victims from Barcelona's L1 are kicked out to the L2 cache.
The new L3 cache, acts as a victim for the L2 cache. So when the small L2 cache fills up, evicted data is sent to the larger L3 cache where it is kept until space is needed. The algorithms that govern the L3 cache's operation are designed to accommodate data that is likely to be needed by multiple cores. If the CPU fetches a bit of code, a copy is left in the L3 cache since the code is likely to be shared among the four cores. Pure data load requests however go through a separate process. The cache controller looks at history and if the data has been shared before, a copy will be left in the L3 cache; otherwise it will be invalidated.
Associativity hasn't been changed for the L1 and L2 caches; they are still 2-way and 16-way set associative, respectively. However, the new L3 cache is 32-way set associative. It has been designed to increase the hit rate of a relatively small cache compared to its competition.
AMD Virtualization Improvements
The performance-related improvement to Barcelona comes in the way of speeding up virtualized address translation. In a virtualized software stack where you have multiple guest OSes running on a hypervisor there's a new form of memory address translation that must be dealt with: guest OS to hypervisor address translation, as each guest OS has its own independent memory management. According to AMD, currently this new layer of address translation is handled in software through a technique called shadow paging. What Barcelona offers is a hardware accelerated alternative to shadow paging, which AMD is calling Nested Paging.
Supposedly up to 75% of the hypervisor's time can be spent dealing with shadow pages, which AMD eliminates by teaching the hardware about both guest and host page tables. The translated addresses are cached in Barcelona's new larger TLBs to further improve performance. AMD indicates that Barcelona's support for Nested Paging requires very little to implement; simply setting a mode bit should suffice, making the change easy for software vendors to implement.
Power Management
The most recent aspect of Barcelona's design that AMD revealed is how it handles power management. Although all four cores still operate on the same power plane (same voltage), Barcelona's Northbridge now runs on a separate power plane. Barcelona's core and Northbridge voltages can vary between 0.8V - 1.4V independently of one another.
In a conventional platform architecture, the Northbridge and the CPU are already on separate power planes given that the Northbridge is external to the CPU. The benefit of this arrangement is that the two chips can power down independently of one another, so when the memory controller has little to do, it can power down until needed. With AMD's K8, this wasn't true as the Northbridge and CPU core(s) were on the same power plane. In Barcelona, they are separated to improve power efficiency.
The individual cores still share the same reference voltage, but each core has its own PLL so that they can run at different clock speeds depending on load. While voltages of all four cores have to be equal, clock speed and thus current draw can be reduced depending on load - which will amount to power savings under normal usage conditions. The implications on the desktop are particularly interesting since it's rare that most desktop workloads will keep all cores pegged at 100% utilization.
Barcelona supports up to 5 independent p-states for each core, varying only in clock speed. The p-states are completely hardware controlled, so you will not need a driver to enable support for the power management features. AMD also increased the amount of clock gating done on Barcelona compared to K8 at both the block level and logic level. AMD wouldn't give us any more detail than this, but given how long it's been since the K8's introduction we'd expect that there's a lot that can be done.
The performance efficiency enhancements to Barcelona, coupled with updated power management, further clock gating and 65nm process allow AMD's first quad core part to operate within the same thermal envelope as current Opterons.
Final Words
When Intel launched its first Core 2 based microprocessors, the performance improvement was beyond revolutionary. It was the biggest single performance improvement we had seen from a new microprocessor in several years at that point. A large part of Core 2's success was its architecture, but you cannot ignore that it couldn't have come at a better time for Intel.
All Conroe, Merom and Woodcrest had to do was outperform Intel's aging and misguided NetBurst based Pentium 4 processors. Doing so proved quite easy for AMD, which had been doing just that pretty much since the 2000 launch of the processors. With no competition from within Intel, AMD wasn't really doing that much better. While the K8 was a strong architecture, it was getting old. Without any serious performance enhancing architectural updates since its introduction back in 2003, AMD left Intel with a stationary target to aim for. With each successive iteration of the Pentium M architecture, Intel came closer and closer to developing its own Athlon 64 killer, eventually culminating in the release of such a product - the Core 2 Duo.
It wasn't some mystical force of microprocessor design prowess that allowed Intel to pull ahead last year; it was a good architecture and excellent timing. Ironically enough, it was the same two elements that orchestrated much of the success of AMD's K7 and K8 architectures; they were both good designs released at times when the competition was at its worst.
In terms of actual product releases, the first incarnation of AMD's new architecture will be found in the next-generation Opteron due out at the middle of this year. AMD will initially launch at speeds ranging from 2.1GHz to 2.3GHz, but by the end of this year you can expect higher clock speeds. On the desktop, AMD's Agena core will be a Barcelona equivalent shipping at between 2.7 - 2.9GHz. Kuma will be a dual-core variant of Agena shipping in the 2.0 - 2.9GHz range.
Barcelona will be a success for AMD; the long awaited architectural update to K8 should yield significant performance improvements, especially in current areas of weakness for the K8 (e.g. video encoding). Our review of the Athlon 64 X2 6000+ showed that with aggressive pricing, AMD could come close to offering something competitive to Intel. At current prices, we suspect that Barcelona would be enough to close the gap between AMD and Intel. Chances are that we won't see bargain basement prices on AMD's new cores, but we'd expect that AMD would have to maintain a competitive market.
The real catch here is what happens after Barcelona; as we mentioned before, Intel's current successes were born out of steady but regular evolution of a good starting architecture. With yearly updates to the Pentium M, Intel achieved a snowball effect that proved difficult to stop. It would seem that a similar approach by AMD would be necessary to avoid sticky situations like the one it finds itself in today.






