Original Link: https://www.anandtech.com/show/2322
AMD's Quad-Core Barcelona: Defending New Territory
by Johan De Gelas on September 10, 2007 12:15 AM EST- Posted in
- IT Computing
Introduction
A "Simulated 2.6GHz" AMD quad-core would beat the best Intel Xeon by 42%, or so we were told back in March at CeBIT. AMD's latest is a device with 463 million transistors designed to run at a clock speed of at least 2.2GHz, possibly 2.8GHz. Scheduled for launch in the middle of 2007, Intel's best Xeons would be once again in the rearview mirror of their AMD competitors. AMD's third generation Opteron sure looked very promising back in early spring 2007.
June, July, and August went by, but still no Barcelona, and when the news started to trickle in that AMD's newest quad-core would only reach 2GHz, AMD's future didn't look so bright anymore. It became even worse as the launch date and details of the newest 45nm Xeons popped up on a public webpage for resellers: November the 11th. New Xeons at clock speed up to 3.16GHz are thus only a few months away. "Not so bright" turned into "grim" - even "dark, really dark".

Luckily, today is the launch of AMD's third generation Opterons. It's only at 2GHz right now, but it's packed with many clever tricks to improve the number of instructions per cycle (IPC). There's also a surprise in store: 2.5GHz samples are already in the AnandTech lab, and they will be available to everyone in the fourth quarter. So there is a chance we still are going to experience an old fashioned breakneck race; a heated battle of epic proportions between AMD and Intel for the top spot in the server market. However, this will only occur if AMD's newest quad-core is able to outperform the Intel alternatives clock for clock by a decent margin. Read on to see whether AMD has been able to pull that one off...
Before we start, here are a few important notes on our testing. We were only given a few days with the newest quad-core before the NDA was finished. As a result our server benchmarking is only a preview, and we'll follow up with more details in the near future. Also, instead of repeating all of AMD's improvements to the core again, we'll simply refer to our previous article about Barcelona's architecture. We'll discuss these architectural improvements further together with the relevant benchmarks.
Finally, for those that are wondering what happens if you pick up a quad-core Opteron server and try to use it as a desktop (or just a hardware editor looking to predict Phenom performance as best as we're able), Anand has put together an AMD Phenom Preview where he does exactly that. Getting the GeForce 8800 GTX into a server chassis took some work, and the focus is on K8 versus Barcelona performance scaling, but the results might give a decent indication of where Phenom X4 will land in a couple months.
AMD's Newest Quad-Core
Before we start talking about benchmarks, here's a short overview of the new models and their pricing in the competitive landscape. AMD is launching both 4/8-way (4S) and 2-way (2S) models of the new quad-core Opterons at speeds ranging from 1.7GHz to 2GHz. To keep things simple, we'll first take a look at the 4S (four socket) market.

AMD uses a different power rating than TDP: "Average CPU Power" or ACP. AMD claims that this power rating is very similar to Intel's TDP: it is the average power draw when the processor runs high utilization workloads. A CPU with a TDP of 95W has an ACP of 75W; one with a TDP of 68W has an ACP of 55W. According to AMD, ACP should be the number we use to compare to Intel's TDP. We'll verify this claim in a later article.
Let's see how the new Opterons compare to Intel's CPUs when it comes to pricing and power:
| Intel 4S Processors | |||||||||
| Core Architecture CPUs | |||||||||
| Quad/ Dualcore | Clock | Codename | L2 | L3 | FSB | Mem bandwidth | TDP | Price | |
| Xeon MP X7350 | Quad | 2.93GHz | Tigerton | 2 x 4MB | - | 266 MHz Quad | 8.5GB/s | 130W | $2301 |
| Xeon MP E7340 | Quad | 2.4GHz | Tigerton | 2 x 4MB | - | 266 MHz Quad | 8.5GB/s | 80W | $1980 |
| Xeon MP E7330 | Quad | 2.4GHz | Tigerton | 2 x 3MB | - | 266 MHz Quad | 8.5GB/s | 80W | $1391 |
| Xeon MP E7320 | Quad | 2.13GHz | Tigerton | 2 x 2MB | - | 266 MHz Quad | 8.5GB/s | 80W | $1,177 |
| Xeon MP E7310 | Quad | 1.6GHz | Tigerton | 2 x 2MB | - | 266 MHz Quad | 8.5GB/s | 80W | $856 |
| Xeon MP L7345 | Quad | 1.86GHz | Tigerton | 2 x 4MB | - | 266 MHz Quad | 8.5GB/s | 50W | $2301 |
| NetBurst Architecture CPUs | |||||||||
| Xeon MP 7140M | Dual | 3.4GHz | Tulsa | 2x 1MB | 16MB | 200 MHz Quad | 6.4GB/s | 150W | $1980 |
| Xeon MP 7130M | Dual | 3.2GHz | Tulsa | 2x 1MB | 8MB | 200 MHz Quad | 6.4GB/s | 150W | $1391 |
| Xeon MP 7120M | Dual | 3GHz | Tulsa | 2x 1MB | 4MB | 200 MHz Quad | 6.4GB/s | 95W | $1117 |
| AMD 4S Processors | |||||||||
| Barcelona Architecture CPUs | |||||||||
| Quad/ Dualcore | Clock | Codename | L2 | L3 | HT | Mem bandwidth | TDP | Price | |
| Opteron 8350 | Quad | 2GHz | Barcelona | 4x 0.5MB | 2MB | 1000 MHz DDR | 10.6GB/s | 95W | $1019 |
| Opteron 8347 | Quad | 1.9GHz | Barcelona | 4x 0.5MB | 2MB | 1000 MHz DDR | 10.6GB/s | 95W | $768 |
| Opteron 8347 HE | Quad | 1.9GHz | Barcelona | 4x 0.5MB | 2MB | 1000 MHz DDR | 10.6GB/s | 68W | $873 |
| Opteron 8346 HE | Quad | 1.8GHz | Barcelona | 4x 0.5MB | 2MB | 1000 MHz DDR | 10.6GB/s | 68W | $698 |
| K8 Architecture CPUs | |||||||||
| Opteron 8224 SE | Dual | 3.2GHz | Santa Rosa | 2x 1MB | - | 1000 MHz DDR | 10.6GB/s | 119W | $2149 |
| Opteron 8222 | Dual | 3GHz | Santa Rosa | 2x 1MB | - | 1000 MHz DDR | 10.6GB/s | 95W | $1514 |
| Opteron 8220 | Dual | 2.8GHz | Santa Rosa | 2x 1MB | - | 1000 MHz DDR | 10.6GB/s | 95W | $1165 |
| Opteron 8218 | Dual | 2.6GHz | Santa Rosa | 2x 1MB | - | 1000 MHz DDR | 10.6GB/s | 95W | $873 |
| Opteron 8218 HE | Dual | 2.6GHz | Santa Rosa | 2x 1MB | - | 1000 MHz DDR | 10.6GB/s | 68W | $1019 |
First of all, it is worth noting that the old Tulsa Xeons remain very expensive and are not even worth considering as they only offer half the performance of Tigerton. The same can be said about the Opteron 82xx series. These CPUs are clocked a lot higher which is interesting for applications that scale badly and need excellent single threaded performance, but nobody is going to buy a 4S machine for such an application. It will be interesting to see if AMD lowers the prices of these CPUs or not.
Back to Barcelona, it also has to face the newly launched Tigerton (of which we are preparing a review). It seems that AMD's CPUs might conquer the high performance blade market easy: AMD offers 55W (68W TDP) quad-cores for about $700-$900, while Intel wants no less than $2300 for their lower power 4S quad-core. Our first tests indicate that a 1.9GHz Barcelona should outperform a 1.86GHz Tigerton, but more testing is needed. For now, we can only conclude that Intel has priced itself out of the 4S blade market. Then again, pricing doesn't always seem to be the primary concern with blades.
AMD also positions the 2GHz 8350 against the Tigerton 2.13GHz, which should allow them to defend the new found territory: AMD has no less than 56% of the 4S market in the US. Basically, we can conclude that AMD's pricing in the 4S market should be quite competitive.
2-Way Market
The 4S market has some great profit margins, but 75%-80% of the server market is 2S. Below is AMD's pricing for this very popular market.

So how does AMD's pricing compare to Intel's?
| Intel 2S Processors | |||||||||
| Quad Core CPUs | |||||||||
| Quad/ Dualcore | Clock | Codename | L2 | L3 | FSB | Mem bandwidth | TDP | Price | |
| Xeon X5365 | Quad | 3GHz | Clovertown | 2x 4MB | - | 333 MHz Quad | 21GB/s | 120W | $1172 |
| Xeon E5355 | Quad | 2.66GHz | Clovertown | 2x 4MB | - | 333 MHz Quad | 21GB/s | 120W | $744 |
| Xeon E5345 | Quad | 2.33GHz | Clovertown | 2x 4MB | - | 333 MHz Quad | 21GB/s | 80W | $455 |
| Xeon E5335 | Quad | 2GHz | Clovertown | 2x 4MB | - | 333 MHz Quad | 21GB/s | 80W | $316 |
| Xeon E5320 | Quad | 1.86GHz | Clovertown | 2x 4MB | - | 266 MHz Quad | 17GB/s | 80W | $256 |
| Xeon L5335 | Quad | 2GHz | Clovertown | 2x 4MB | - | 333 MHz Quad | 21GB/s | 50W | $380 |
| Xeon L5320 | Quad | 1.86GHz | Clovertown | 2x 4MB | - | 266 MHz Quad | 17GB/s | 50W | $320 |
| Dual Core CPUs | |||||||||
| Xeon DP 5160 | Dual | 3GHz | Woodcrest | 4MB | - | 333 MHz Quad | 21GB/s | 80W | $851 |
| Xeon DP 5150 | Dual | 2.66GHz | Woodcrest | 4MB | - | 333 MHz Quad | 21GB/s | 65W | $690 |
| Xeon DP 5148 | Dual | 2.33GHz | Woodcrest | 4MB | - | 333 MHz Quad | 21GB/s | 40W | $519 |
| AMD 2S Processors | |||||||||
| Quad Core CPUs | |||||||||
| Quad/ Dualcore | Clock | Codename | L2 | L3 | HT | Mem bandwidth | TDP | Price | |
| Opteron 2350 | Quad | 2GHz | Barcelona | 4x 0.5MB | 2MB | 1000 MHz DDR | 10.6GB/s | 95W | $389 |
| Opteron 2347 | Quad | 1.9GHz | Barcelona | 4x 0.5MB | 2MB | 1000 MHz DDR | 10.6GB/s | 95W | $316 |
| Opteron 2347 HE | Quad | 1.9GHz | Barcelona | 4x 0.5MB | 2MB | 1000 MHz DDR | 10.6GB/s | 68W | $377 |
| Opteron 2346 HE | Quad | 1.8GHz | Barcelona | 4x 0.5MB | 2MB | 1000 MHz DDR | 10.6GB/s | 68W | $255 |
| Opteron 2344 HE | Quad | 1.7GHz | Barcelona | 4x 0.5MB | 2MB | 1000 MHz DDR | 10.6GB/s | 68W | $209 |
| Dual Core CPUs | |||||||||
| Opteron 2224 SE | Dual | 3.2GHz | Santa Rosa | 2x 1MB | - | 1000 MHz DDR | 10.6GB/s | 119W | $873 |
| Opteron 2222 | Dual | 3GHz | Santa Rosa | 2x 1MB | - | 1000 MHz DDR | 10.6GB/s | 95W | $698 |
| Opteron 2220 | Dual | 2.8GHz | Santa Rosa | 2x 1MB | - | 1000 MHz DDR | 10.6GB/s | 95W | $523 |
| Opteron 2218 | Dual | 2.6GHz | Santa Rosa | 2x 1MB | - | 1000 MHz DDR | 10.6GB/s | 95W | $377 |
| Opteron 2218 HE | Dual | 2.6GHz | Santa Rosa | 2x 1MB | - | 1000 MHz DDR | 10.6GB/s | 68W | $450 |
AMD positions the 2350 2GHz between the 2.13 and 2.33GHz quad-core Xeon. The 1.9GHz version squarely targets the 2GHz E5335. AMD has no answer to the X5365 and E5355, but currently those CPUs are offered in a higher power consumption band, so this is not the really the end of the world. The 3.2GHz and 3GHz Opterons might still make sense for some hard to scale applications if AMD lowers the prices significantly.
Words of Thanks
A lot of people gave us assistance with this project, and we would of course like to thank them.
Damon Muzny, AMD US
Brett Jacobs, AMD US
(www.amd.com)
Randy Chang, ASUS
(www.asus.com)
Kelly Sasso, Crucial Technology
Matty Bakkeren, Intel Netherlands
(www.intel.com)
Benchmark configuration
Here is the list of the different configurations. All servers have been flashed to the latest BIOS, and unless we add any specific comments to the contrary, the BIOS are set to default settings.
Opteron 2350 Server: ASUS KFSN4-DRE
Dual Opteron 2350 2GHz
Asus KFSN4DRE BIOS version 1001.02 (8/28/2007) - NVIDIA nForce Pro 2200 chipset
8GB (4x2GB) Crucial Registered DDR2-667 CL5 ECC
NIC: Broadcom BCM5721
Opteron Socket F 1207 Server: Tyan Transport TA26 - 2932
Dual Opteron 2222 3GHz / 2224SE 3.2GHz
Tyan Thunder n3600m (S2932) - NVIDIA nForce Pro 3600 chipset
8GB (4x2GB) Crucial Registered DDR2-667 CL5 ECC
NIC: nForce Pro 3600 integrated MAC with Marvell 88E1121 Gigabit Ethernet PHY
Xeon Server: Intel "Bensley platform" server
2x Xeon 5160 3GHz or 2x Xeon E5345 at 2.33GHz
Intel Server Board S5000PSL - Intel 5000P Chipset
8GB (4x2GB) Crucial Registered FB-DIMM DDR2-667 CL5 ECC
NIC: Dual Intel PRO/1000 Server NIC
BIOS note: Hardware prefetching disabled
Client Configuration: Dual Opteron 850
MSI K8T Master1-FAR
4x512MB Infineon PC2700 Registered, ECC
NIC: Broadcom 5705
Software
SUSE Linux SLES 10 SP1 (Linux 2.6.16.46-smp)
MySQL 5.0.26 as shipped with SUSE SLES 10 SP1
SPECjbb2005
Sun Hotspot Java JVM 1.5.0_08
3DSMax 9
Cinebench 9.5
WinRAR 3.62
ASUS KFSN4-DRE: Split Power Enabled
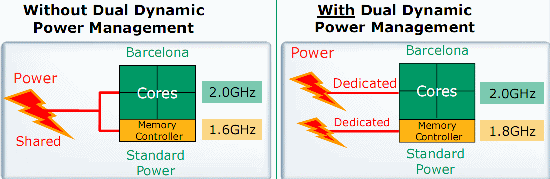
ASUS was the first to send us a board which supports AMD's split power plane. Split power plane or dual dynamic power management means that the memory controller and the core are fed from different power rails. According to AMD, this allows the memory controller to run at 1.8GHz instead of 1.6GHz, and provides a 7% boost in raw memory performance. The new quad-core Opteron processors should work in the older socket-F motherboards with a BIOS Update. These unified plane motherboards will be slightly slower (slightly lower clocked memory controller) and consume a bit more power though.
The ASUS KFSN4-DRE supports no less than 16 DIMMs in total, good for a maximum of 64GB of RAM (but at lower speeds than 667 MHz). To improve performance, ASUS has implemented a "dual link". The two processor sockets are connected by a pair (instead of one) of 16-bit coherent HyperTransport buses. According to ASUS, dual link and split power planes offer not only lower power but up to 14% higher performance. Unfortunately, it has not been disclosed in which application this 14% has been measured.

The SSE EB board is clearly made for a compact 1U server. The one x16 PCI-E slot can be used to plug in a riser card which allows you to use two x8 PCI-E slots. Using the NVIDIA nForce pro 2200, the board is able to provide four SATA ports which can support RAID levels 0,1,10 and 5. Luckily, for those of you thinking of using VMWare ESX on this board, a version with the LSI 1064 SAS controller and four SAS connectors will also be available. ASUS has made an excellent choice by using the Broadcom BCM5721 PCI-E for the Gigabit LAN interfaces.
ASUS left some space for an optional IPMI Module (ASMB3) for Out-of-Band and Remote Server Management. With two 667 MHz DIMMs in each node, the ASUS KFSN4-DRE ran all our benchmarks for many hours. The LINPAC benchmark in particular takes up to eight hours and proves that the board behaved very well in this configuration. We will investigate other DIMM configurations later.
"Native Quad-Core"
AMD has told the whole world and their pets that Barcelona is the first true quad-core as opposed to Intel's quad-cores which are twin dual cores. This should result in much better scaling, partly a result of the fact that cores should be able to exchange cache information much quicker.
To quantify the delay that a "snooping" CPU encounters when it tries to get up-to-date data from another CPU's cache, take a look at the numbers below. We have used Cache2cache before; you can find more info here. Cache2Cache measures the propagation time from a store by one processor to a load by the other processor. The results that we publish are approximately twice the propagation time.
| Cache coherency ping-pong (ns) | |||
| Same die, same package | Different die, same package | Different die, different socket | |
| Opteron 2350 | 152 | N/A | 199 |
| Xeon E5345 | 59 | 154 | 225 |
| Xeon DP 5160 | 53 | - | 237 |
| Xeon DP 5060 | 201 | N/A | 265 |
| Xeon 7130 | 111 | N/A | 348 |
| Opteron 880 | 134 | N/A | 169-188 |
AMD's native quad-core needs about 76ns to exchange (L1) cache information. That's not bad, but it's not fantastic either as the shared L2 cache approach of the Xeons allows the dual cores to exchange information via the L2 in about 26-30ns. Once you need to get information from core 0 to core 3, the dual die CPU of Intel still doesn't need much more time (77ns) than the quad-core Opteron (76ns). The complex L1-L2-L3 hierarchy might negate the advantages of being a "native" quad-core somewhat, but we have to study this a bit further as it is quite a complex matter.
Memory Subsystem
AMD has improved the memory subsystem of the newest Opteron significantly: the L1 cache is about the only thing that has not been changed: it's still the same 2-way set associative 64KB L1 cache as in K8, and it can be accessed in three cycles. Like every modern CPU, the new Opteron 2350 is capable of transferring about 16 bytes each cycle.
| Lavalys Everest L1 Bandwidth | |||||
| Read (MB/s) | Write (MB/s) | Copy (MB/s) | Bytes/cycle (Read) | Latency (ns) | |
| Opteron 2350 2 GHz | 32117 | 16082 | 23935 | 16.06 | 1.5 |
| Xeon 5160 3.0 | 47860 | 47746 | 95475 | 15.95 | 1 |
| Xeon E5345 2.33 | 37226 | 37134 | 74268 | 15.96 | 1.3 |
| Opteron 2224 SE | 51127 | 25601 | 44080 | 15.98 | 0.9 |
| Opteron 8218HE 2.6 GHz | 41541 | 20801 | 35815 | 15.98 | 1.1 |
L2 bandwidth has been a weakness in the AMD architectures for ages. Back in the "K7 Thunderbird" days, AMD simply "bolted" the L2 cache onto the core. The result was a relatively narrow 64-bit path from the L2 cache to the L1 cache which could at best deliver about 2.4 to 3 bytes per cycle. The K8 architecture improved this number by 50% and more, but that still wasn't even close to what Intel's L2 caches could deliver per cycle. In the Barcelona architecture, The data paths into the L1 cache have been doubled once again to 256-bits. And it shows:
| Lavalys Everest L2 Bandwidth | |||||||
| Read (MB/s) | Write (MB/s) | Copy (MB/s) | Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | Latency (ns) | |
| Opteron 2350 2 GHz | 14925 | 12170 | 13832 | 7.46 | 6.09 | 6.92 | 1.7 |
| Dual Xeon 5160 3.0 | 22019 | 17751 | 23628 | 7.34 | 5.92 | 7.88 | 5.7 |
| Xeon E5345 2.33 | 17610 | 14878 | 18291 | 7.55 | 6.38 | 7.84 | 6.4 |
| Opteron 2224 SE | 14636 | 12636 | 14630 | 4.57 | 3.95 | 4.57 | 3.8 |
| Opteron 8218HE 2.6 GHz | 11891 | 10266 | 11891 | 4.57 | 3.95 | 4.57 | 4.6 |
| Lavalys Everest L2 Comparisons | |||
| Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | |
| Barcelona versus Santa Rosa | 63% | 54% | 51% |
| Barcelona versus Core | -1% | -5% | -12% |
| Santa Rosa versus Core | -39% | -38% | -42% |
Barcelona, aka Opteron 23xx, is capable of delivering no less than 50%-60% more bandwidth to its L1 cache than K8. We also measure a latency of 15 cycles, which puts the AMD L2 cache in the same league as the Intel Core caches.
The memory controllers of the third generation of Opterons have also been vastly improved:
- Deeper buffers. The low latency integrated memory controller was already one of the strongest points of the Opteron, but the amount of bandwidth it could extract out of DDR2 was mediocre. Only at higher frequencies is the Opteron able to gain a bit of extra performance from fast DDR2-667 DIMMs (compared to DDR-400). This has been remedied in 3rd generation Opteron thanks to deeper request and response buffers.
- Write buffer. When Socket 939 and dual channel memory support was introduced, we found that the number of cycles that bus turnaround takes had a substantial impact on the performance of the Athlon 64. Indeed with a half duplex bus to the memory it takes some time to switch between writing and reading. When you fill up all the DIMM slots in a socket 939 system, the bus turnaround has to be set to two cycles instead of one. This results in up to a 9% performance hit, depending on how memory intensive your application is. So the way to get the best performance is to use one DIMM per channel and keep the bus turnaround at one cycle. However, even better than trying to keep bus turnaround as low as possible is to avoid bus turnarounds. A 16 entry write buffer in the memory controller allows Barcelona to group writes together and then burst the writes sequentially.
- More flexible. Each controller supports independent 64-bit accesses. (Dual core Opteron: a single 128-bit access across both controllers)
- DRAM prefetchers. The DRAM prefetcher works to request data from memory before it's needed when it sees that the memory is being accessed in regular patterns. It can go forward or backward in the memory.
- Better "open page" management. By keeping the right rows ready on the DRAM, the memory controller only has to pick out the right columns (CAS) to get the necessary data instead of searching for the right row, copying the row, and then picking out the right column. This saves a lot of latency (e.g. RAS to CAS), and can also save some power.
- Split power planes. Feeding the memory controller and the core from different power rails is not a direct improvement to the memory subsystem, but it does allow the memory controller to be clocked higher than the CPU core.
Okay, let's see if we can make all those promises of better memory performance materialize. We first tested with Lavalys Everest 4.0.11.
| Lavalys Everest Memory BW | |||||||
| Read (MB/s) | Write (MB/s) | Copy (MB/s) | Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | Latency (ns) | |
| Opteron 2350 2 GHz | 5895 | 4463 | 6614 | 2.95 | 2.23 | 3.31 | 76 |
| Dual Xeon 5160 3.0 | 3656 | 2771 | 3800 | 1.22 | 0.92 | 1.27 | 112.2 |
| Xeon E5345 2.33 | 3578 | 2793 | 3665 | 1.53 | 1.2 | 1.57 | 114.9 |
| Opteron 2224 SE | 7466 | 6980 | 6863 | 2.33 | 2.18 | 2.14 | 58.9 |
| Opteron 8218HE 2.6 GHz | 6944 | 6186 | 5895 | 2.67 | 2.38 | 2.27 | 64 |
| Lavalys Everest Memory BW Comparison | ||||
| Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | Latency (ns) | |
| Barcelona versus Santa Rosa | 26% | 2% | 54% | 29% |
| Barcelona versus Core | 92% | 86% | 111% | -34% |
| Santa Rosa versus Core | 74% | 99% | 44% | -44% |
The deeper buffers and more flexible 2x64-bit accesses have increased the read bandwidth, but the write buffer might have negated the effect of those a bit. That is not a problem, as very few applications will be solely writing for a long period of time. Notice that per cycle, the improved copy bandwidth is 54% and is the biggest gain. This is most likely the result of the copy action resulting in an interleaving of writes and reads, allowing the split memory access design to come into play.
With much higher L2 cache and memory bandwidth combined with low latency access, the memory subsystem of the 3rd generation of Opterons is probably the best you can find on the market. Now let's try to find out if this superior memory subsystem offers some real world benefits.
64-bit Linux Java Performance: SPECjbb2005
SPECjbb needs good integer performance and an excellent memory subsystem, especially if you test with several instances as we do. So what integer improvements could help Barcelona here?
Fetching 32 bytes instead of 16 bytes (Intel Core, AMD previous Opterons) makes decoding a bit faster as the average decoding bandwidth increases, but will only help performance when the CPU is able to calculate many instructions per cycle, which is not the case in a lot of applications, including SPECjbb (IPC of 0.2 - 0.5). It might help with some branch intensive code however (unaligned branch targets).
The biggest improvement for integer code and especially code that accesses the memory a lot is the fact that finally AMD has an architecture that can reorder loads ahead of a load and in some cases a store. This feature has been lacking in the AMD family, while it has been present in the Intel CPUs since the Pentium Pro. It makes the newest AMD quad CPUs more "out of order" than previous CPUs; Intel's Core architecture is still a lot more flexible in this, but the AMD Barcelona should like the SPECjbb benchmark quite a bit: it has more memory bandwidth than the Core CPUs have available, and the gap in OOO integer processing with Core has been reduced quite a bit.
SPECjbb2005 from SPEC (Standard Performance Evaluation Corporation) evaluates the performance of server side Java by emulating a three-tier client/server system with emphasis on the middle tier. Instead of testing with a separate possibly disk intensive database system, SPECjbb uses tables of objects, implemented by Java Collections. A longer description can be found here.
Again, it is not our objective to show the best possible scores. Very few people will take the time to fully tune the JVM and take the risk that some of the ultra aggressive optimizations backfire. So we tested with some decent but rather generic tuning that we could use on all systems. The JVM is Sun's version 1.5.0_08, which allows us to compare scores with previous results as we have had only a few days to test the newly arrived systems.
We tested SPECjbb2005 with four application instances. Using NUMActl, a clever utility written by Andi Kleen, we were able to bind each Java application to a separate node. We didn't bind instances to CPUs on the Intel platforms (though it is possible with taskset) as it gives lower performance. The parameters in bold show the actual JVM optimizations.
On the Opteron we used:
numactl --cpunodebind=$node --membind=$node -- java -cp jbb.jar:check.jar -Xms2g -Xmx2g -Xmn1g -Xss128K -XX:+AggressiveOpts -XX:+UseParallelOldGC -XX:+UseParallelGC spec.jbb.JBBmain -propfile SPECjbb.props -id $xjava -classpath jbb.jar:check.jar -Xms2g -Xmx2g -Xmn1g -Xss128K -XX:+AggressiveOpts -XX:+UseParallelOldGC -XX:+UseParallelGC spec.jbb.JBBmain -propfile SPECjbb.props -id $x
The newest Opteron does well, and performs like a 2.4GHz Clovertown. Note that it cannot outperform the old four socket (but more expensive) 880 Opteron as this platform has even more bandwidth available and runs at an almost 20% higher clock speed. Still, we can conclude that the improved memory subsystem does pay off in SPECjbb. That's a good sign for the majority of server applications, but what about the HPC world?
64-bit Linux HPC Performance: LINPACK
There is one kind of code where Core really ate the AMD CPUs for breakfast. It was close to embarrassing: floating point intensive code that makes heavy use of vector SIMD, also called packed SSE (and SSE2/SSE3) runs up to two times as fast on a Xeon 5160 (3GHz) than on Opteron 2222 (3GHz) . This is also one of the (but probably not the main) reason why AMD was also falling a bit behind in the gaming area.
AMD has really gone a long way to improve the performance of 128-bit packed SSE instructions:
- Instruction fetch has been doubled to 32 bytes
- 128-bit SSE computations now decode into a single micro-op (two in K8)
- The load unit can load two 128-bit numbers from the L1 cache each cycle
- FP Reservation stations are still 36 entry, but they're now 128-bits wide instead of 64-bits
- All three FPU executions units were widened to 128-bit (64-bit before)
- The L2 cache has double the bandwidth to cope with this
Meet LINPACK, a benchmark application based on the LINPACK TPP code, which has become the industry standard benchmark for HPC. It solves large systems of linear equations by using a high performance matrix kernel. We used Intel's version of LINPACK, which uses the highly optimized Intel Math Kernel Library. The Intel MKL is quite popular and in an Intel dominated world, AMD's CPUs have to be able to run Intel optimized code well.
We used a workload of square matrices of sizes 5000 to 30000 by steps of 5000, and we ran four (dual dual-core) or eight threads (dual quad-core). As the system was equipped with 8GB of RAM, the large matrixes all ran in memory. LINPAC is expressed in GFLOPs (Giga/Billions of Floating Operations Per Second). We'll start with the quad-core scores (one quad or two duals).
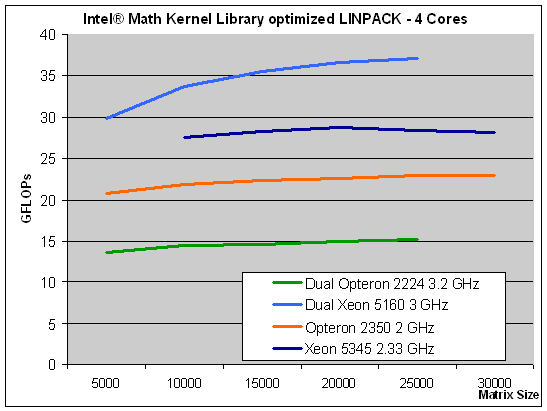
Yes, this code is very Intel friendly but it does exist in the real world, and it is remarkably interesting. Look at what Barcelona is doing: it is outperforming a 60% higher clocked Opteron 2224 SE. That means that clock for clock, the third generation Opteron is no less than 142% faster. That is a massive improvement!
Thanks to meticulous tuning for the Intel's cores, the Xeon is still winning the benchmark. A 17% higher clocked Xeon 5345 is about 25-26% faster than Barcelona, but the days where this kind of code resulted in embarrassing defeats for AMD are over. We are very curious how a LINPACK compiled with AMD's math kernel libraries and other compilers would do, but the late arrival didn't allow us to do much recompiling.
Now let's take a look at the eight thread results. We kept the Xeon 5160 (four threads) in this graph, so you can easily compare the results with the previous graph.
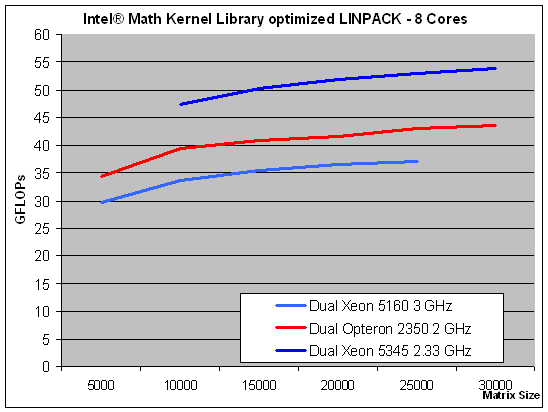
Normally you would expect that this kind of code with huge matrices has to access the memory a lot, but masterly optimization together with hardware prefetching ensures most of the data is already in the cache. The quad-core Xeon wins again, but the victory is a bit smaller: the advantage is 20%-23%. Let us see if Intel can still keep the lead when we look at a benchmark which is very SSE intensive and which is optimized for Intel CPUs, but this time it's developed by a third party.
Software Rendering: zVisuel (32-bit Windows)
This benchmark is the zVisuel Kribi 3D test, which is exclusive to AnandTech.com and which simulates the assembly of an exclusive mechanical watch. The complete model is very detailed with around 300,000 polygons and a lot of texture, bump, and reflection maps. More than 1000 frames are rendered and the average FPS (frames per second) is reported. All this is rendered on the "Kribi 3D" engine, an ultra-powerful real-time software rendering 3D engine. That all this happens at reasonable speeds is a result of the fact that the newest AMD and Intel architectures contain four cores and can perform up to eight 32-bit FP operations per clock cycle and per core. The people of zVisuel told us that - in reality - the current Core architecture can sustain six FP operations in well optimized loops.

The 3D model of the benchmark in the middle of its assembly
Can the newest AMD architecture sustain the same amount of massive FP power? Eric Bron provided us with a benchmark which is based on real world use by a well know zVisuel client. The first benchmark does not use antialiasing
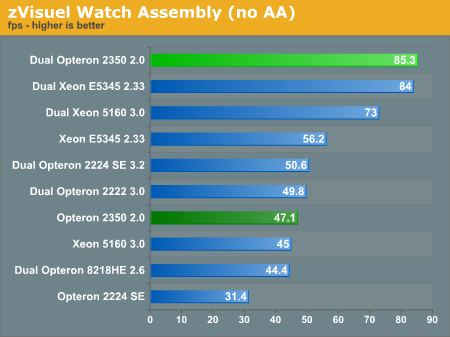
The tables are turning: while the newest AMD quad-core had to let the faster clocked Intel quad-core Xeon go in the LINPACK tests, it takes a small but still measurable lead in zVisuel. Notice that the Intel CPU has the advantage when it comes to raw processing power: it is about 19% faster in a single CPU configuration. Once you add a second CPU in both systems, that 19% lead is turned into a 3% advantage for AMD. Also note that a 2GHz Quad Opteron 2350 is about as fast as a dual 3GHz Opteron 2222 DC.
Be aware though that you need the Enterprise edition of Windows 2003 to see this kind of performance. The 32-bit Windows 2003 standard does not support NUMA and the bandwidth hungry AMD quad-core does not like that at all. Performance was up to 14% (!) lower, showing only 73 fps instead of 85 fps.
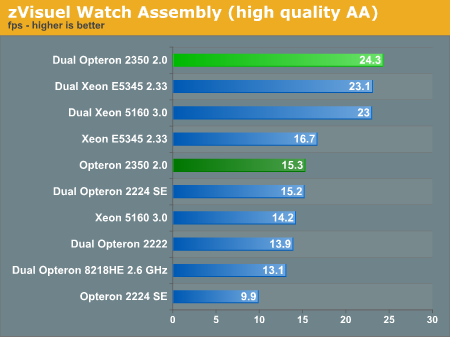
We performed the same benchmark, but with antialiasing applied. AA makes the application a bit more memory intensive. The AMD quad-core extends its lead from 3% to 5%, and a single 2GHz quad-core is now capable of even outperforming a 3.2GHz dual Opteron SE 2224.
The LINPACK and zVisuel benchmarks make it clear that Intel and AMD have about the same raw FP processing power (clock for clock), but that the Barcelona core has the upper hand when the application has to access the memory a lot.
3ds Max 9 (32-bit Windows)
We tested with the 32-bit version of 3ds Max version 9, which has been improved to work better with multi-core systems but which is not as aggressively tuned for SSE as LINPACK and zVisuel. We used the "architecture" scene, which has been a favorite benchmarking scene for years. All tests were done with 3ds Max's default scanline renderer, SSE is enabled, and we rendered at HD 720p (1280x720) resolution. We measured the time it takes to render ten frames from 20 to 29. All results are reported in seconds, lower being better.

As this test has been our standard test for a while, we added results from previous tests. This time, Intel is firmly in the lead: most of the test runs well in the cache of each CPU. AMD did make a progress though. A Dual 3GHz Opteron 2222 is capable of generating about 29 frames per hour. As this benchmark scales well with clock speed, we may assume that a potential 3GHz Barcelona will be able to spit out ~35 frames per hour. In other words, the new quad-core is about 20% more efficient than the previous dual-core generation, core per core, clock per clock. This is also shown by the score of the quad Opteron 880 (2.4GHz). But it is not enough to beat the Intel armada: even a 2GHz Xeon will probably slightly beat the current 2GHz Opteron 2350.
MySQL
To get an idea what a typical SLES 10 user will experience, we simply used the MySQL version which is supported by the latest SLES 10 SP1, i.e. MySQL 5.0.26. The testing configuration was identical to our 3.2GHz Opteron review.
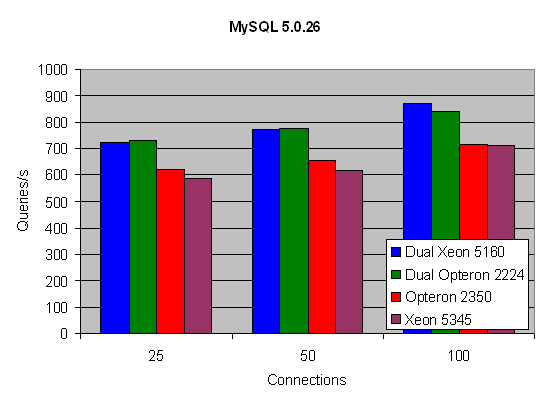
Forgive us for this quick test, as we had only a few days to test Barcelona before the NDA. You'll see other versions of MySQL pop up in later reviews. The first results seem to indicate that AMD's newest quad-core is capable of keeping up with slightly faster quad-core Xeons, but the results are not yet conclusive.
WinRAR 3.62
Many servers and workstations have to compress a lot of data. WinRAR is one of the most popular compression applications and now features a multi-threaded benchmark. Compression algorithms work on large streams of data, so fast memory access is important.
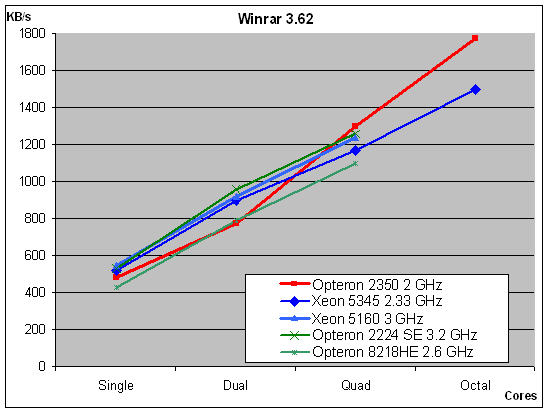
The "dual-core score" has been obtained by setting the affinity of WinRAR to only two adjacent cores. This might lower the score a bit, but it is the best we were able to do right now Looking at the curves, the real dual performance is probably about 10% higher in reality. Even then, it is clear that once again the AMD quad-core scales better than the other CPUs. It also beats a 3.2GHz Opteron 2224, which is quite impressive. The picture gets clearer as you compare the gains from extra cores in percentages.
| WinRAR Scaling | |||
| Core | Dual vs Single | Quad vs Dual | Octal vs Quad |
| Opteron 2350 2 GHz | 59% | 68% | 36% |
| Xeon 5345 2.3 GHz | 73% | 30% | 28% |
| Xeon 5160 3 GHz | 68% | 34% | N/A |
| Opteron 2224 SE 3.2 GHz | 81% | 32% | N/A |
| Opteron 8218HE 2.6 GHz | 85% | 40% | N/A |
While the quad versus dual percentage increase of the Barcelona core is somewhat exaggerated, it is pretty obvious that Barcelona scales better.
Fritz Chess Benchmark
Our last benchmark is a chess benchmark which scales very well with both cores and clock speed.
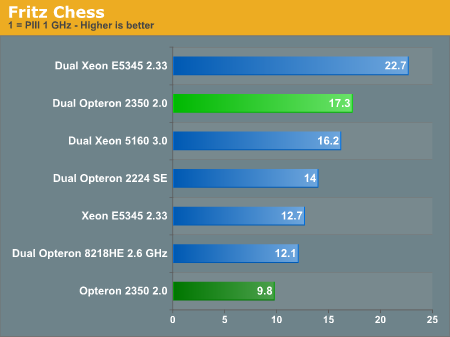
Chess programs are branch intensive integer applications, and although the Opteron 2350 is a bit better (clock for clock) than the previous generation of Opterons, it is the Xeon "Clovertown" that comes out on top. The quad-core Xeon is 30% faster.
Power
AMD has made numerous improvements compared to the K8 core:
- The FPU unit can be turned off when not needed
- Clock gating is implemented much better
- Each core can run at its own frequency (but the voltage is the highest needed by either core)
- Power for the core and memory controller are split
We measured power consumption using two identically configured Colfax systems running Windows 2003 SP1 64-bit. The server configuration is listed below:
| AMD | Intel | |
| Motherboard | Supermicro H8DMU+ | Supermicro X7DBE+ |
| BIOS Revision | DMU8157v3.ROM | R1.3C |
| CPU | 2 x Opteron 2350 (2.0GHz) | 2 x Xeon 5345 (2.3GHz) |
| Memory | 8GB (8 x 1GB DDR2-667) | 8GB (8 x 1GB FBDIMM-667) |
| Hard Disk | 1 x Seagate Barracuda ES (400GB) | 1 x Seagate Barracuda ES (400GB) |
| Power Supply | 700W Redundant | 700W Redundant |
| OS | Windows Server 2003 SP1, 64-bit | Windows Server 2003 SP1, 64-bit |
At idle, the Opteron 2350 platform uses significantly less power than the Xeon setup, a decrease of about 44%. While Intel will be able to drop its power consumption with the move to 45nm, the impact won't be great enough to close this gap. The problem here is that Intel must use FB-DIMMs which consume significantly more power than AMD's registered DDR2, short of switching memory technologies there's nothing Intel can do.
| CPU | Idle | Load (Cinebench R10 XCPU) | Performance per Watt (Cinebench Score/Watts) |
| Dual Opteron 2350 | 188W | 299.9W | 41.9 |
| Dual Xeon 5345 | 257W | 347.3W | 47.4 |
Under load, the two are closer in power consumption with the Xeon only using 16% more total system power. Looking at performance per watt, Intel is actually ahead thanks to superior performance under the Cinebench R10 benchmark.
Conclusion
It's close to a nightmare to try to review a server CPU in a few days, but we hope we have at least provided you with an idea what AMD's newest quad-core is capable of. We'll summarize our preliminary results with this small table.
| The Opteron 2350 (2 GHz) vs. Xeon "Clovertown" | |
| General applications | Opteron 2350 (2GHz) equates to Xeon clock speed of: |
| WinRAR 3.62 | 2.7 GHz |
| Fritz Chess engine | 1.8 GHz |
| HPC applications | |
| Intel optimized Linpack | 1.9 GHz |
| 3D Applications | |
| 3DS Max 9 | 2 GHz |
| zVisuel 3D Kribi Engine | 2.33 - 2.4 GHz |
| zVisuel 3D Kribi Engine (AA) | 2.4 GHz |
| Server applications | |
| Specjbb | 2.4 GHz |
| MySQL | 2.33 GHz |
Considering that AMD prices this Opteron 2350 under the Xeon 5345, AMD has an attractive price/performance offering for most applications. The only exception is a chess engine and highly optimized Intel binaries. Although our testing is not finished yet, there is very little doubt that AMD's newest chip is very energy efficient. Add to that the fact that the AMD platform is not burdened with the extra power consumption of FB-DIMMs, and it is clear that the third generation of Opterons will lead in the performance/watt area for a few months. When you are looking for the highest performance however, Intel has still a solid advantage with it's 3 GHz Xeon x5365
The future looks very interesting with the 45nm Xeon Harpertown and a 2.5GHz AMD quad-core in the next quarter. AMD hasn't clearly hit a homerun this time, but at least they're playing in the same ballpark.
Again, if you're curious about how quad-core Opteron functions in more of a desktop capacity - as a preview of things to come with the launch of Phenom - don't miss our AMD Phenom Preview article. We tossed in a GeForce 8800 GTX and ran some gaming and general computing performance numbers. It's still a socket 1207 server motherboard, but we limited the comparison to Santa Rosa versus Barcelona Opteron performance in order to focus on the CPU and not on potential platform differences.






