High-End x86: The Nehalem EX Xeon 7500 and Dell R810
by Johan De Gelas on April 12, 2010 6:00 PM EST- Posted in
- IT Computing
- Intel
- Nehalem EX
Reliability Features
Intel claims no less than 20 new RAS features for the new Xeon, most of them borrowed from the Itanium. Some of the RAS features are for the most paranoid of IT professionals. Let's face it, who has experienced a server crash that was caused by a bad CPU? For each CPU failure there must be a million failures caused by buggy software. So we are not too concerned if a competing CPU lacks "hot physical CPU board" swapping, and it is reasonable to think that most IT professionals—even those with mission critical applications—will agree. The most paranoid people usually have the highest budgets, as the mission critical applications they manage could cost them their job if they go down. Not to mention that the company they work for might lose millions of dollars. So those people tend to favor a very long list of reliability features.

All ironic remarks about paranoid people aside, most of these RAS features make a lot of sense even for the "down to earth" people, the rest of us. Memory does fail a lot more than CPUs. According to Google research, 8% of the DIMMs see one correctable error per year, and 0.22% have uncorrectable errors. These machines can have up to half a Terabyte (!) of RAM, and with 32 to 64 DIMMs an uncorrectable error is conceivable. So it is no surprise that most of the RAS features try to cope with failing DRAM chips. Also as the number of VMs that you consolidate on one machine increases, the risk of a bad VM bringing the complete host machine down increases.
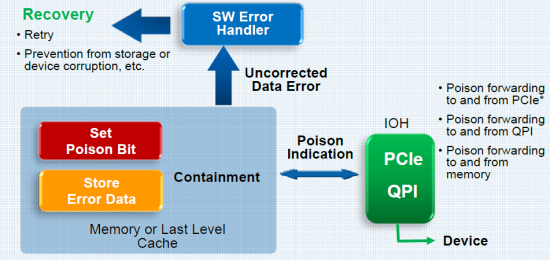
The idea behind the Machine Check Architecture is that errors in memory and L3 cache are detected before they are actually "used" by the running software. A firmware based memory scrubber constantly checks ("patrols") for unrecoverable errors, errors that ECC cannot correct. Those errors will make the (ESX) hypervisor create a purple screen—which is in most cases much worse than the famous blue screen—to make sure your data does not get corrupted.
With MCA in hardware and support in both firmware and the hypervisor, data errors are transmitted to the hypervisor's error handler before they cause havoc. The memory location is placed in quarantine (poisoned data containment) and the CPU will not use that address again. The software handler can then retry to get the data, and as a result the hypervisor keeps running. This "recover" mechanism can of course only work if the error is created by the occasional glitch and not by bad hardware.
So the basic idea behind these increased reliability features is that the more memory you have, the higher the chances that an occasional glitch occurs and thus the more features like demand and patrol scrubbing and recovery from single DRAM device failure are handy. You will need something better than simple ECC. The same is true for QPI. As the number of Nehalem EX CPUs and the speed of QPI links increases, the chances for bad addresses or bad data increases as well.








23 Comments
View All Comments
dastruch - Monday, April 12, 2010 - link
Thanks AnandTech! I've been waiting for an year for this very moment and if only those 25nm Lyndonville SSDs were here too.. :)thunng8 - Monday, April 12, 2010 - link
For reference, IBM just released their octal chip Power7 3.8Ghz result for the SAP 2 tier benchmark. The result is 202180 saps for approx 2.32x faster than the Octal chipNehalem-EXJammrock - Monday, April 12, 2010 - link
The article cover on the front page mentions 1 TB maximum on the R810 and then 512 GB on page one. The R910 is the 1TB version, the R810 is "only" 512GB. You can also do a single processor in the R810. Though why you would drop the cash on an R810 and a single proc I don't know.vol7ron - Tuesday, April 13, 2010 - link
I wish I could afford something like this!I'm also curious how good it would be at gaming :) I know in many cases these server setups under-perform high end gaming machines, but I'd settle :) Still, something like this would be nice for my side business.
whatever1951 - Tuesday, April 13, 2010 - link
None of the Nehalem-EX numbers are accurate, because Nehalem-EX kernel optimization isn't in Windows 2008 Enterprise. There are only 3 commercial OSes right now that have Nehalem-EX optimization: Windows Server R2 with SQL Server 2008 R2, RHEL 5.5, SLES 11, and soon to be released CentOS 5.5 based on RHEL 5.5. Windows 2008 R1 has trouble scaling to 64 threads, and SQL Server 2008 R1 absolutely hates Nehalem-EX. You are cutting Nehalem-EX benchmarks short by 20% or so by using Windows 2008 R1.The problem isn't as severe for Magny cours, because the OS sees 4 or 8 sockets of 6 cores each via the enumerator, thus treats it with the same optimization as an 8 socket 8400 series CPU.
So, please rerun all the benchmarks.
JohanAnandtech - Tuesday, April 13, 2010 - link
It is a small mistake in our table. We have been using R2 for months now. We do use Windows 2008 R2 Enterprise.whatever1951 - Tuesday, April 13, 2010 - link
Ok. Change the table to reflect Windows Server 2008 R2 and SQL Server 2008 R2 information please.Any explanation for such poor memory bandwidth? Damn, those SMBs must really slow things down or there must be a software error.
whatever1951 - Tuesday, April 13, 2010 - link
It is hard to imagine 4 channels of DDR3-1066 to be 1/3 slower than even the westmere-eps. Can you remove half of the memory dimms to make sure that it isn't Dell's flex memory technology that's slowing things down intentionally to push sales toward R910?whatever1951 - Tuesday, April 13, 2010 - link
As far as I know, when you only populate two sockets on the R810, the Dell R810 flex memory technology routes the 16 dimms that used to be connected to the 2 empty sockets over to the 2 center CPUs, there could be significant memory bandwidth penalties induced by that.whatever1951 - Tuesday, April 13, 2010 - link
"This should add a little bit of latency, but more importantly it means that in a four-CPU configuration, the R810 uses only one memory controller per CPU. The same is true for the M910, the blade server version. The result is that the quad-CPU configuration has only half the bandwidth of a server like the Dell R910 which gives each CPU two memory controllers."Sorry, should have read a little slower. Damn, Dell cut half the memory channels from the R810!!!! That's a retarded design, no wonder the memory bandwidth is so low!!!!!