AMD Comments on GPU Stuttering, Offers Driver Roadmap & Perspective on Benchmarking
by Ryan Smith on March 26, 2013 2:28 AM ESTThe Start: The Rendering Pipeline In Detail
Before we can even discuss the concept of stuttering and other frame timing anomalies, we need to first take a look at a high-level overview of the Windows rendering pipeline. The pipeline isn’t particularly complex, but understanding where various stages of the process are in the hands of Windows, the CPU, the driver, and the video card is necessary to understand where bottlenecks and delays can occur.
At its most fundamental level, rendering a frame is a 3 part process. An application needs to pass data to Windows, Windows needs to manage the process and interface with the drivers, and finally once Windows and driver preparation is complete, a frame can be passed off to the GPU for final rendering and display.
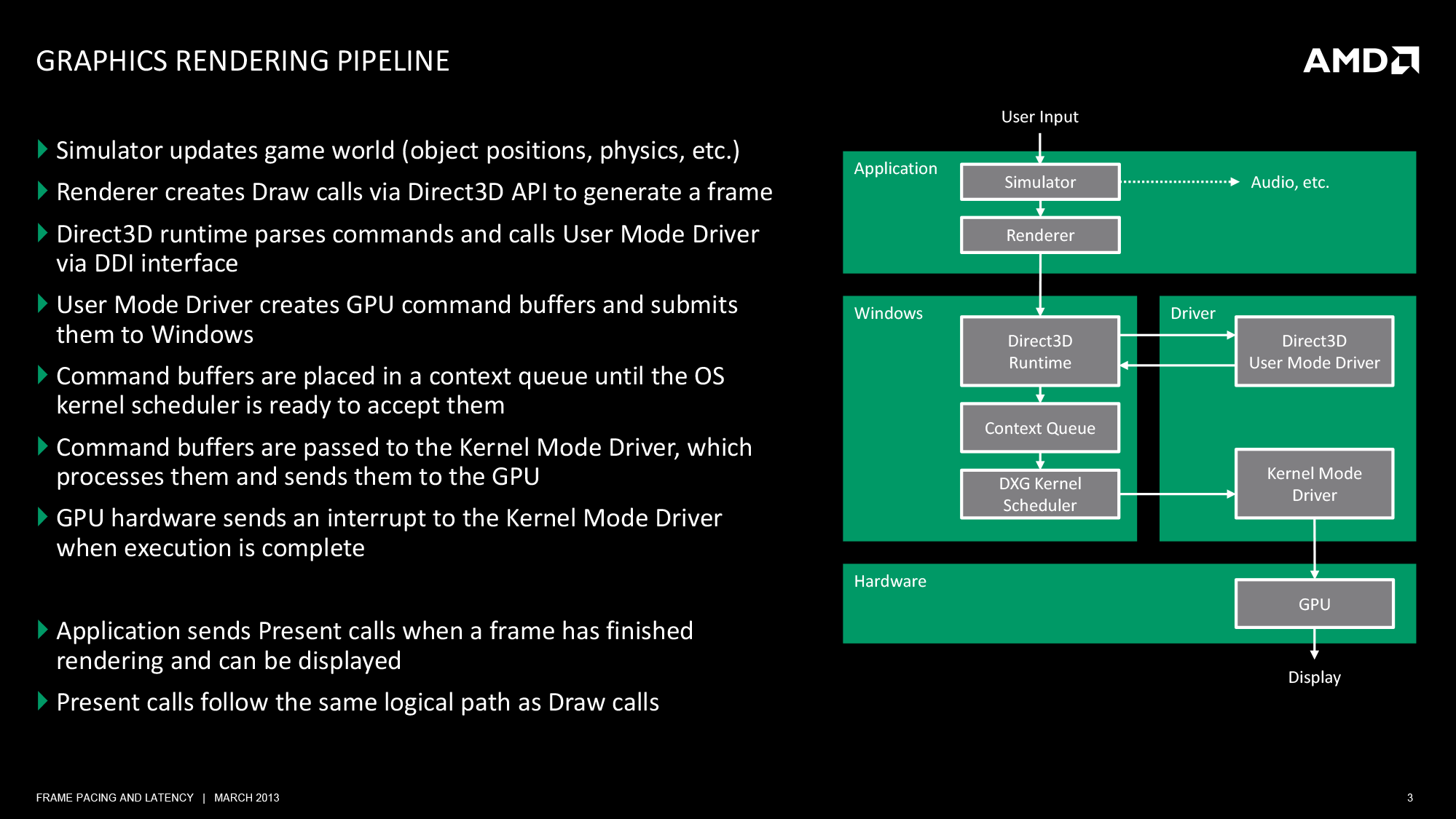
At the top of the chain is the application itself. This is where user input is being handled and where in the context of a game the simulation is being executed. From a technical perspective, it is the application that is the first arbitrator for game smoothness; applications are responsible for adjusting the simulation rate in order to keep the flow of frames smooth. If the application cannot ensure an even rate, then nothing else that follows will really matter.
The reality of course is that this is harder than it sounds. It is not an insurmountable problem, but PCs are devices with a wide spectrum of performance and capabilities. A dual-core processor with an iGPU performs very different from a hex-core processor with a small army of GPUs, and an application needs to be able to accommodate this so that the simulation operates as evenly as possible in both CPU and GPU-bottlenecked scenarios.
Ultimately any timing model is going to be reactive, adjusting itself in response to prior events and how long previous frames took to render. Though another option is to shortcut this process entirely and operate at a fixed (or capped) simulation rate, either basing a game around 30Hz/60Hz operation, or decoupling rendering from the simulation entirely. Anyone who has uncapped id Software’s Rage for example will find that the game simply does not behave correctly without its 60Hz cap.
Static or dynamic, once a simulation has a suitable timing model in place we can then begin to look further down the chain, which is where we first encounter Direct3D, Windows’ primary 3D rendering API. Direct3D is nothing short of an enormous, complex structure of API calls and features. We tend to reduce it to version numbers and marque features for the sanity of ourselves and our readers – as we will here – but it goes without saying that Direct3D takes years to master; and for a GPU manufacturer it’s made all the more complex by the simultaneous existence of the modern iteration of Direct3D (DX10+), and the classic iteration that is DX9 and its predecessors.
For the purpose of the rendering pipeline Direct3D has a few different jobs. First and foremost, it is collecting draw calls from the application, combining them, and processing them for further work. Once a complete frame’s worth of draw calls has been collected, Direct3D passes its processed work over to the first component of the video card driver stack, the User Mode Driver (UMD).
It’s the UMD that is primarily responsible for taking the output of Direct3D and turning it into work batches the GPU can handle. These work batches, command buffers (aka Display Lists), are collections of instructions and data suitable for processing by the target GPU. Among other things, the UMD is responsible for shader compilation and assigning rendering elements to the correct (and best) surface formats for the GPU.

A logical view of single command buffer; from Microsoft's Direct3D documentation
When the UMD’s work is complete, it passes its command buffer back over to Direct3D. Direct3D in turn passes that command buffer to the context queue, our first real bottleneck. We’ll get back to why this is a bottleneck in a bit, but briefly, the context queue is responsible for queuing the individual command buffers in order to smooth out the rendering process. Queuing command buffers at this stage increases frame rendering latency, but by providing a buffer of buffers it allows the rendering pipeline to absorb any variances in rendering time or simulation time to more smoothly render frames.
The context queue has also gone by other names over the years, such as the flip queue and the pre-rendered frames queue. This is the source of the 3 frame render-ahead limit in Windows that is sometimes exposed in games and drivers, as Windows will by default queue up to 3 frames in this manner. This can be controlled by application developers, but most will leave it at 3 so long as a game is smoothly moving along.
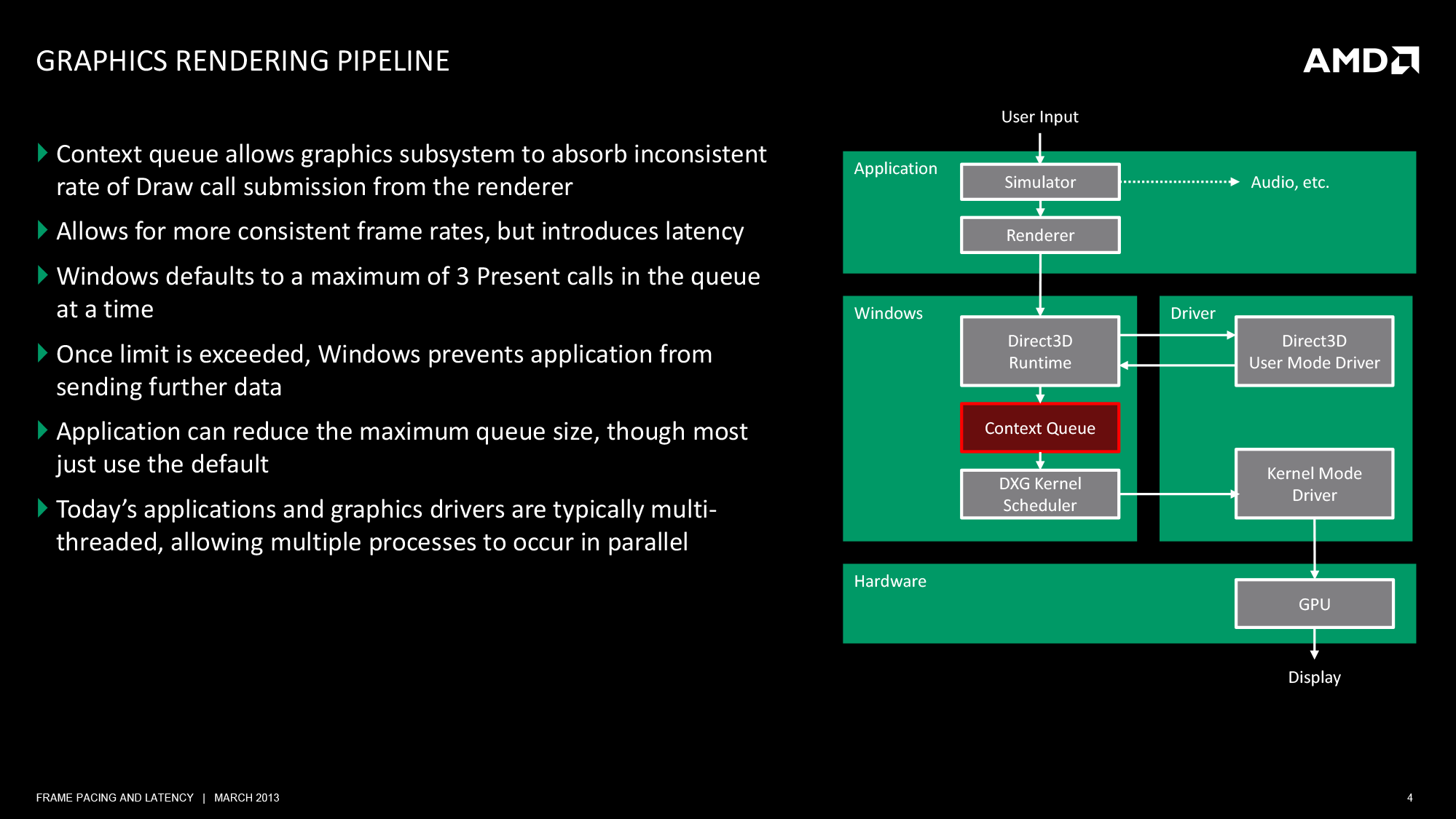
Beyond the context queue we have Windows’ GPU scheduler, which is what regulates the popping of command buffers off of the context queue to be fed to the kernel mode GPU driver (KMD). Beyond this point the rest of the pipeline is rather simple, with the KMD taking the command buffer and feeding it to the GPU, all the while the KMD and GPU work together to manage the operation of the GPU. When a frame is finally completed, the GPU generates an interrupt to inform the KMD and OS about the completion.
At the end of this process we have a rendered frame sitting in the GPU’s back-buffer, but the frame itself is not displayed automatically. At the end of a batch of command buffers – effectively making the beginning and ends of frames – is the Direct3D Present() call. Present is the command that is responsible for telling the GPU to flip the back buffer to the front and to present the rendered frame to the user. Only once the Present call executes does a frame get displayed. The Present call, though not a command buffer object, still follows the same rendering path as the command buffers, including queuing up in the Context Queue.








103 Comments
View All Comments
eezip - Tuesday, March 26, 2013 - link
First one! Wow, I'm lame. Thanks Ryan - keep 'em coming!B3an - Tuesday, March 26, 2013 - link
Yes very lame. You should sit down and think what you're doing with your life and what kind of sad person you are.xaml - Tuesday, March 26, 2013 - link
It reads as if you didn't, so why do you point a finger.stickmansam - Tuesday, March 26, 2013 - link
I agree with the double blinding idea. Techreport had some videos on the skyrim stuttering and I showed it my bro with the card names covered and he actually preferred the AMD card. Personally I though both of them were playable since the 240fps video exaggerated any stuttering issues. If you can't tell the difference in a 60hz or 120hz video/monitor there is no difference.It would be nice if someone would develop an tool to measure the frames as they are being displayed, like as they are actually being viewed.
krumme - Tuesday, March 26, 2013 - link
The benefit of blindtest is twofold:It removes all the complexity involved in testing, and get to the point where it matters.
Secondly we get an oppinion as to what the benefits of the game have, going to higher quality settings.
Anand for much good, have the same staff, and we will get to know Ryan preferences in just a few rounds of testing.
Then he can have a nice assistant changing the cards for him :)
DanNeely - Tuesday, March 26, 2013 - link
While not blind, HardOCP's maximum playable settings testing is done to capture this. They report min/avg/max/graphed FPS; but at whatever combination of settings gave the most eye candy while still being fast and smooth enough to be enjoyable. At times this has resulted in observations that "while the raw FPS numbers imply that turning on X should be doable the gameplay results indicated otherwise" (generally due to stuttering problems).Havor - Tuesday, March 26, 2013 - link
I always liked HardOCP's maximum playable settings approach.But now i think that Ryan Shrout from PC Perspective is doing the best testing there is, by actually capturing all the frames with a capture card.
So no testing @ the start as FRAPS dose or some ware in the middle, no realworld frame output, better then that you cant do.
http://www.pcper.com/reviews/Graphics-Cards/Frame-...
http://www.pcper.com/reviews/Graphics-Cards/Frame-...
http://www.pcper.com/reviews/Graphics-Cards/Frame-...
Its a real interesting read, and i hope they will start doing testing real soon, as hard numbers are hard to come by, as there is still no perfect way of testing frame times.
Sabresiberian - Tuesday, March 26, 2013 - link
"Playable" and "optimal" are different things; for the most part no one is suggesting the games and cards that have more problems with stuttering are "unplayable".And, some people don't notice what bugs the fire out of others. Stuttering is one of those things. I think this has a lot to do with the fact that these problems have existed for quite awhile and people just got used to them, so kind of automatically ignore them.
So, I agree, if you don't notice it then it's not important. But if you do, then it is. :) I noticed this phenomenon years ago, and am very excited to see numbers that people can show quantifying the situation so that it can be discussed on more than a seat-of-the-pants level.
Soulwager - Tuesday, March 26, 2013 - link
The problem with double blinding is that some people notice more than others. If you're used to high end equipment on a 120hz monitor, you'll notice a hell of a lot more problems than dude off the street that normally plays on his laptop.medi01 - Wednesday, March 27, 2013 - link
Last time I've checked on toms, AMD's GPUs were better in this regard.Looks like yet another article to "compensate" for 7790.