Inside the Titan Supercomputer: 299K AMD x86 Cores and 18.6K NVIDIA GPUs
by Anand Lal Shimpi on October 31, 2012 1:28 AM EST- Posted in
- CPUs
- IT Computing
- Cloud Computing
- HPC
- GPUs
- NVIDIA
Applying for Time on Titan
The point of building supercomputers like Titan is to give scientists and researchers access to hardware they wouldn't otherwise have. In order to actually book time on Titan, you have to apply for it through a proposal process.
There's an annual call for proposals, based on which time on Titan will be allocated. The machine is available to anyone who wants to use it, although the problem you're trying to solve needs to be approved by Oak Ridge.

If you want to get time on Titan you write a proposal through a program called Incite. In the proposal you ask to use either Titan or the supercomputer at Argonne National Lab (or both). You also outline the problem you're trying to solve and why it's important. Researchers have to describe their process and algorithms as well as their readiness to use such a monster machine. Any program will run on a simple computer, but to need a supercomputer with hundreds of thousands of cores the requirements are very strict. As a part of the proposal process you'll have to show that you've already run your code on machines that are smaller, but similar in nature (e.g. 1/3 the scale of Titan).
Your proposal would then be reviewed twice - once for computational readiness (can it run on Titan) and once for scientific peer review. The review boards rank all of the proposals received, and based on those rankings time is awarded on the supercomputers.
The number of requests outweighs the available compute time by around 3x. The proposal process is thus highly competitive. The call for proposals goes out once a year in April, with proposals due in by the end of June. Time on the supercomputers is awarded at the end of October with the accounts going live on the first of January. Proposals can be for 1 - 3 years, although the multiyear proposals need to renew each year (proving the time has been useful, sharing results, etc...).
Programs that run on Titan are typically required to run on at least 1/5 of the machine. There are smaller supercomputers available that can be used for less demanding tasks. Given how competitive the proposal process is, ORNL wants to ensure that those using Titan actually have a need for it.
Once time is booked, jobs are scheduled in batch and researchers get their results whenever their turn comes up.
The end user costs for using Titan depend on what you're going to do with the data. If you're a research scientist and will publish your findings, the time is awarded free of charge. All ORNL asks is that you provide quarterly updates and that you credit the lab and the Department of Energy for providing the resource.
If, on the other hand, you're a private company wanting to do proprietary work you have to pay for your time on the machine. On Jaguar the rate was $0.05 per core hour, although with Titan ORNL will be moving to a node-hour billing rate since the addition of GPUs throws a wrench in the whole core-hour billing increment.
Supercomputing Applications
In the gaming space we use additional compute to model more accurate physics and graphics. In supercomputing, the situation isn't very different. Many of ORNL's supercomputing projects model the physically untestable (either for scale or safety reasons). Instead of getting greater accuracy for the impact of an explosion on an enemy, the types of workloads run at ORNL use advances in compute to better model the atmosphere, a nuclear reactor or a decaying star.
I never really had a good idea of specifically what sort of research was done on supercomputers. Luckily I had the opportunity to sit down with Dr. Bronson Messer, an astrophysicist looking forward to spending some time on Titan. Dr. Messer's work focuses specifically on stellar decay, or what happens immediately following a supernova. His work is particularly important as many of the elements we take for granted weren't present in the early universe. Understanding supernova explosions gives us unique insight into where we came from.
For Dr. Messer's studies, there's a lot of CUDA Fortran that's used although the total amount of code that runs on GPUs is pretty small. There may be 20K - 1M lines of code, but in that complex codebase you're only looking at tens of lines of CUDA code for GPU acceleration. There are huge speedups from porting those small segments of code to run on GPUs (much of that code is small because it's contained within a loop that gets pushed out in parallel to GPUs vs. executing serially). Dr. Messer tells me that the actual process of porting his code to CUDA isn't all that difficult, after all there aren't that many lines to worry about, but it's changing all of the data around to make the code more GPU friendly that is time intensive. It's also easy to screw up. Interestingly enough, in making his code more GPU friendly a lot of the changes actually improved CPU performance as well thanks to improved cache locality. Dr. Messer saw a 2x improvement in his CPU code simply by making data structures more GPU friendly.
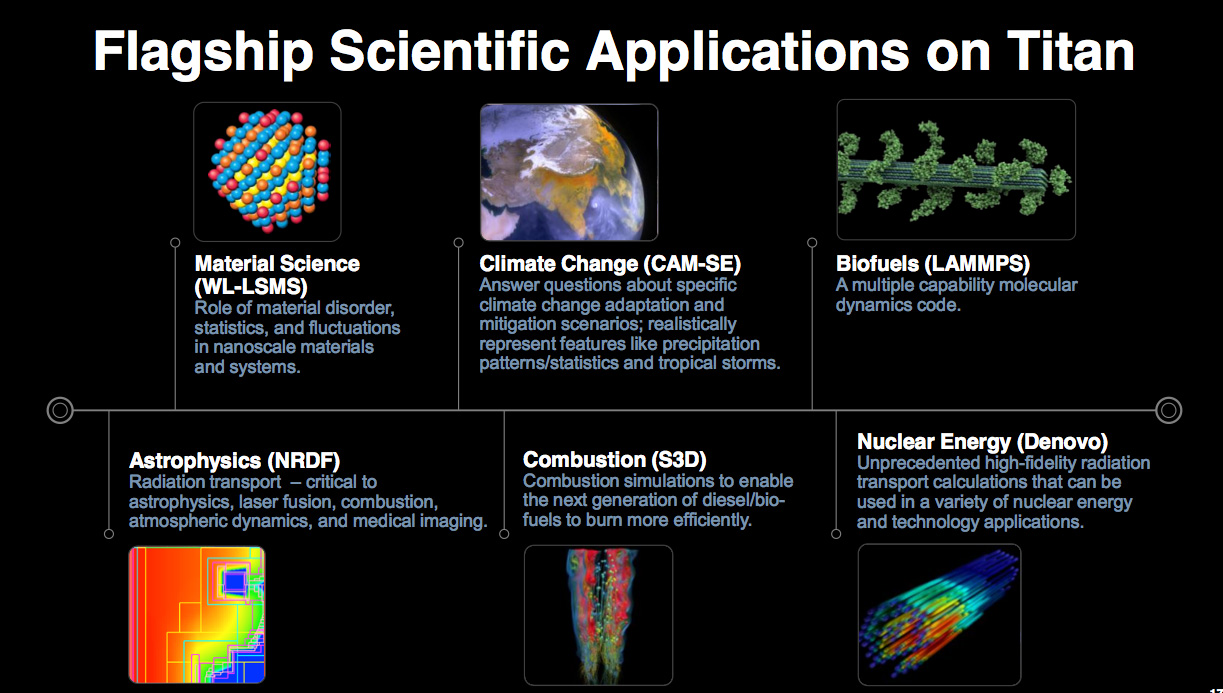
Many of the applications that will run on Titan are similar in nature to Dr. Messer's work. At ORNL what the researchers really care about are covers of Nature and Science. There are researchers focused on how different types of fuels combust at a molecular level. I met another group of folks focused on extracting more efficiency out of nuclear reactors. These are all extremely complex problems that can't easily be experimented on (e.g. hey let's just try not replacing uranium rods for a little while longer and see what happens to our nuclear reactor). Scientists at ORNL and around the world working on Titan are fundamentally looking to model reality, as accurately as possible, so that they can experiment on it. If you think about simulating every quark, atom, molecule in whatever system you're trying to model (e.g. fuel in a combustion engine), there's a ton of data that you have to keep track of. You have to look at how each one of these elementary constituents impacts one another when exposed to whatever is happening in the system at the time. It's these large scale problems that are fundamentally driving supercomputer performance forward, and there's simply no letting up. Even at two orders of magnitude better performance than what Titan can deliver with ~300K CPU cores and 50M+ GPU cores, there's not enough compute power to simulate most of the applications that run on Titan in their entirety. Researchers are still limited by the systems they run on and thus have to limit the scope of their simulations. Maybe they only look at one slice of a star, or one slice of the Earth's atmosphere and work on simulating that fraction of the whole. Go too narrow and you'll lose important understanding of the system as a whole. Go too broad and you'll lose fidelity that helps give you accurate results.
Given infinite time you'll be able to run anything regardless of hardware, but for researchers (who happen to be human) time isn't infinite. Having faster hardware can help shorten run times to more manageable amounts. For example, reducing a 6 month runtime (which isn't unheard of for many of these projects) to something that can execute to completion in a single month can have a dramatic impact on productivity. Dr. Messer put it best when told me that keeping human beings engaged for a month is a much different proposition than keeping human beings engaged for half a year.
There are other types of applications that will run on Titan without the need for enormous runtimes, instead they need lots of repetitions. Doing hurricane simulation is one of those types of problems. ORNL was in between generations of supercomputers at one point and donated some compute time to the National Tornado Center in Oklahoma during that transition. During the time they had access to the ORNL supercomputer, their forecasts improved tremendously.

ORNL also has a neat visualization room where you can plot, in 3D, the output from work you've run on Titan. The problem with running workloads on a supercomputer is the output can be terabytes of data - which tends to be difficult to analyze in a spreadsheet. Through 3D visualization you're able to get a better idea of general trends. It's similar to the motivation behind us making lots of bar charts in our reviews vs. just publishing a giant spreadsheet, but on a much, much, much larger scale.
The image above is actually showing some data run on Titan simulating a pressurized water nuclear reactor. The video below explains a bit more about the data and what it means.








130 Comments
View All Comments
Strunf - Wednesday, October 31, 2012 - link
He's probably not telling the whole thing, there's no way you could reduce the wire thickness by 20 or more by just increasing the voltage to 480V.A5 - Wednesday, October 31, 2012 - link
Uh, yes you can. Higher voltage = less current for the same power, which means you can use a thinner cable.Kevin G - Wednesday, October 31, 2012 - link
There is likely a reduction in size of the insulating layer due to lower amperage as well.relztes - Wednesday, October 31, 2012 - link
Voltage is 2.3 times higher, so current is 2.3 times lower for the same power. A wire 2.3x thinner (5.3x less cross sectional area) will give the same power loss. Insulation thickness would be slightly higher because it's based on voltage not current.HighTech4US - Wednesday, October 31, 2012 - link
If you double the Voltage you halve the Current for the same amount of Power.Power Loss (in the cables) is calculated as I squared times R. Since I is 1/2 at 480 Volts the Power Loss is 1/4 (1/2 squared) as much.
HighTech4US - Wednesday, October 31, 2012 - link
> The comment about the thickness requirement of the cables for 480V compared to 208V in the first power delivery video is staggering. I'm surprised there's such a difference.V = Voltage
I = Current
R = Resistance
P = Power
P = V times I
So if you double the Voltage you halve the Current for the same amount of Power.
Power Loss (in the cables) is calculated as I squared times R. Since I is 1/2 at 480 Volts the Power Loss is 1/4 (1/2 squared) as much.
So they determined a fixed power loss in the cables and reduced the size (which increased the resistance) of the cables so that the thinner cables (at 480 volts) had the same loss as the thicker cables (at 208 volts).
Jaybus - Tuesday, February 19, 2013 - link
A 480 Vrms circuit draws less than half the current of a 208 Vrms circuit at the same power level. So the resistance of the wire can be more than double. Resistance of the wire is the resistivity of the copper material times the length divided by the cross-sectional area. .This means the radius is less than half, or the diameter of the wire for 480 V can be less than a quarter of the diameter of the wire for 208 V.ishbuggy - Wednesday, October 31, 2012 - link
This is an awesome article Anand! I would love to see more super-computing like this, and maybe some in-depth discussion of how super-computing works and differs from traditional computing architectures. Thanks for the great article though!truman5 - Wednesday, October 31, 2012 - link
+1I just registered as a user just to say how awesome this article is!
itnAAnti - Friday, November 9, 2012 - link
+1I also just registered just to say that this is a great article! One of the best I have seen on Anandtech, keep up the awesome work. Perhaps you can look into the Parallella Adapteva project next!