Westmere-EP to Sandy Bridge-EP: The Scientist Potential Upgrade
by Ian Cutress on March 4, 2013 9:30 AM EST- Posted in
- CPUs
- Xeon
- Westmere-EP
- Sandy Bridge-EP
Brownian Motion
Part of my regular motherboard review testing is to tackle the Brownian motion of particles. This considers one of two physical scenarios - either gas in a vacuum or a dissolved substance in a fluid, where those particles that are free to move can do so. These particles can collide with the medium they are in, each other or the boundaries – in general the system can bypass all these by using the diffusion coefficient (average speed of a particle in a medium). However, the simulation should be probing at least one of them – with the first two situations requiring greater computational complexity than dealing with interactions on a surface.
The movement of these particles is the main computational element of this type of simulation – dealing with either free motion (mean free path in a random direction) or directed motion (applied force on top of free motion). Motion should start with a method to calculate which direction the particle is to travel in, and then any applied force simulated on top – the initial method is at the whim of random number generators and the choice of algorithm. In my original article I go through several methods of generating random motion described in the literature, as well as choosing an appropriate random number generator (too many published methods use basic C++ generators that repeat themselves after a few thousand calls). For simulating, we have various methods:
- If the simulation has a fixed number of time steps, calculate the random numbers before the simulation and use memory calls in the movement algorithm
- Calculate the random numbers on the fly during the algorithm if the time steps for each particle can vary (i.e. no need to track a particle after it collides with a surface)
In our Brownian motion benchmark (3D Particle Movement), we test the six different algorithms used in the literature for random direction movement in both single thread and multithreaded mode. The simulation generates a number of particles, each with its own thread. The thread iterates the particle through a fixed number of steps, and discards the particle. When all the threads have finished, the simulation checks the time to see if 10 seconds have passed - if the 10 seconds are not up, it goes through another loop. Results are then expressed in the form of million particle movements per second for each algorithm, and the total score is the sum of all the algorithms.
This benchmark is wholly memory independent – by generating random numbers on the fly, each thread can keep the position of the particle and the random number values in local cache.
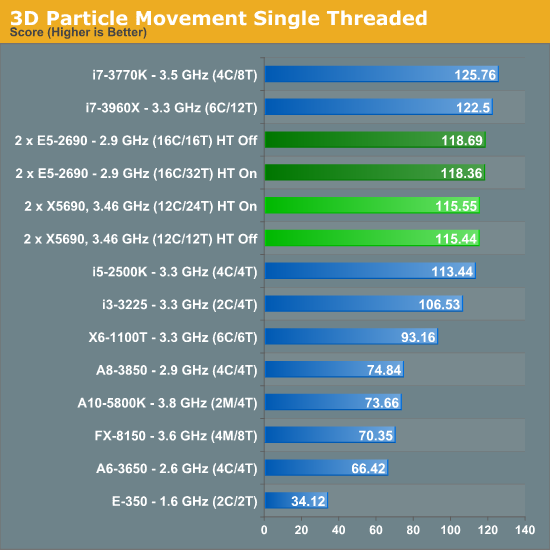
The difference in architectures is most plain to see in our single thread test – both the X5690 and E5-2690 will be applying maximum turbo (3.73 GHz and 3.8 GHz respectively) to similar clocks, meaning the IPC improvements of Sandy Bridge-E give it a 2.5% increase overall despite a mild (1.8%) clock increase.
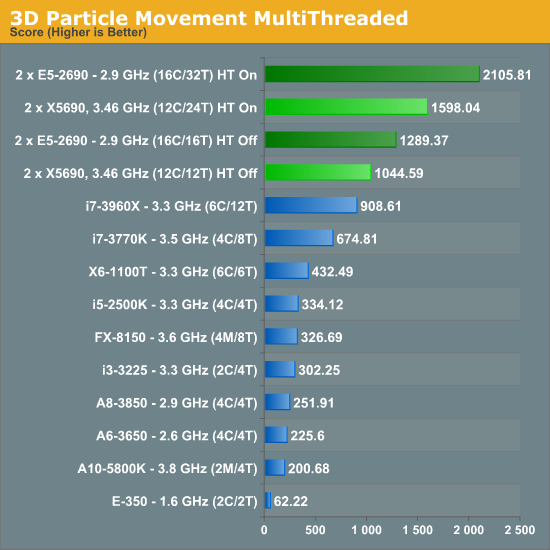
The advantages of more cores for this sort of simulation are plain to see, with the E5-2690 (despite a clock speed difference at full load of 2.9 GHz compared to 3.46 GHz) giving a 32% better result than the X5690.
n-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions.
n-Body simulation is a large field of calculation with many different computational methods optimized for speed, memory usage or bus transfer – this is on top of the different algorithms that can be used to represent such a scenario. Typically one might expect the running time of a simulation be O(n^2) as each particle in the simulation has to interact gravitationally with every other particle, but some computational methods can be used to reduce this as the effect of gravity is inversely proportional to the square of the distance, and thus only the localized area needs to be known. Other complex solutions deal with general relativity. I am neither an expert in gravity simulations or relativity, but the solution used today is the full O(n^2) solution.
Part of the available code online for C++ AMP revolves around n-body simulations, as the basis of an n-body simulation maps nicely to parallel processors such as multi-CPU platforms and GPUs. For this review, I was able to strip out the code from the n-body example provided and run some numbers. Many thanks to Boby George and Jonathan Emmett from Microsoft for their help.
The code provided detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. We run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.

As the n-body example deals with GFLOPs as a result, the numbers were only ever going to be in favor of the E5-2690s, with a 37% increase over the X5690s. Core count, IPC and memory speed play a role with large O(n2) simulations like these. Oddly enough, while HT Off was preferable on the E5-2690s, HT On gives a better result for X5690s.








44 Comments
View All Comments
alpha754293 - Tuesday, March 5, 2013 - link
Sorry, I'm back. Where was I? oh yes...Unless that you were purely running single-threaded, single process jobs (or maybe even lightly multithreaded, single process jobs) - I would think that to say that it is favouring a single-CPU system might be a little bit misleading.
Even with single-socket systems, if it's got multiple cores, then you can parallelize amongst those as well.
Some commercial programs too favour 2^n cores as well, which would make quite a difference between having 8- or 16-cores vs. 6 or 12 (because some programs won't even run properly if it isn't 2^n).
Also it was interesting to see that you didn't run the implicit 3D grid solver benchmark.
Actually, MPI might not has as much to do with memory than you might think. Considering that the world's top supercomputers haven't maxed out the memory capacity per socket, I doubt that. It IS, however, much better at the actual parallelization of the task than OpenMP.
"‘Is moving from Westmere-EP to Sandy Bridge-EP a reasonable upgrade’, in the majority of our scenarios it probably is not"
It really depends. If you're writing your own code (which is what you're doing), and you have a lot of control over it, then that MIGHT be a true statement. (And it also depends on the state of your code too. If you're almost always in a permanent alpha phase (because you keep adding new capability and modules to it), then chances are, you might not even get around to parallelizing it (because you want to make sure that the base solver is robust first before you add the additional complexity of parallelization on top of that).
But if, say, suppose that you're doing research on crash and crash safety; and you're using a commercial code - some of those would just favour more cores period (see Johan's latest benchmark on the Opteron for details).
And as to whether or not you can run it on a GPU; the problem with that is that you have to make sure that every system in your working/research group has the same capable GPU hardware; otherwise, those that don't can't even run it, and those that have lesser-capable GPUs - might not get the benefits of using a GPU as much as you think, if at all.
(My GTX 660 OC's double precision performance is actually slightly SLOWER than the double precision performance of my 3930K OC'd to 4.5 GHz.)
alpha754293 - Tuesday, March 5, 2013 - link
Also, as far as I know/can remember - not everything can make use of AVX - both in terms of programs and also in terms of fundamental math operations.And I would suspect that you might also have slight performance variations if you were to recompile on the Sandy Bridge vs. on the Westmere-EP platforms (rather than sharing the binaries between the two - unless you purposely don't make it target specific).
wingless - Monday, March 4, 2013 - link
Somebody on my folding team is building this setup with dual Titans as a folding/gaming rig. The ultimate in computation, gaming, and space heating!yougotkicked - Monday, March 4, 2013 - link
I just wanted to say I found this analysis rather interesting. I'm a undergrad CS major, but I work in the IT office for the chemical engineering and material science dept. at a research university, so this breakdown of the relationship between simulations and hardware was really fascinating for me.Just to give some perspective on the pricing of an OEM-built system using E5-26XX parts, one of the research groups I work with recently bought a dual E5-2687W system from HP with 128 gigs of ram, liquid cooling, and a mid-range workstation GPU; The whole system came in at over $10,000. admittedly this includes a ~$1000 monitor and 4 hard drives, but this is probably at least a 30% margin over the cost of hardware, so the 10% margin used in the article may be on the conservative side.
P.S. we didn't suggest that system to the researchers, they bought it on their own.
colonelpepper - Monday, March 4, 2013 - link
HP & Dell systems are much more expensive than the same system built by a "system integrator" <-- I believe that's what they're calledI've read in other forums that system integrators building you a custom system add about 10% to the price tag.
yougotkicked - Monday, March 4, 2013 - link
That sounds reasonable, my only gripe would be that many researchers would not seek out a system integrator and just turn to a big name like HP. Had they sought the advice of the IT office I would have suggested we build it in-house for no markup at all.Kevin G - Monday, March 4, 2013 - link
Dell and HP's workstation lines carry a much higher premium than what you'd get DIY. The difference is in their warranties. Since dual socket workstations are effectively using low end servers in a tower chassis and they'll offer warranties very similar to what you can get for a 24/7/365 running server. While I'm not a big fan of Dell's hardware, I will say that they do follow through on their warranties. I've seen them get a replacement hard drive to my facility in under 4 hours as that is the level of support I was paying for. It wasn't cheap but it was worth it considering the business need.With the scientific slant, such warranties may turn out to be overkill as is going with OEM's. You'd still want to have the necessary data protections in place like ECC memory, redundant storage and a good backup policy while the simulation is running. However, what is the worst case that could happen when something does go wrong with the basic protections in place? Generally it is simply running the simulation again. Time is money and there are often some deadlines to meet. So if the simulation can't realistically be run again or it'd cost to much to run again, then going with an OEM that'll help achieve greater uptime is worth it.
As for the price of some of these components individually, I'm about to drop ~$1000 USD on a 128 GB memory upgrade. OEM's like Dell and HP get such parts far cheaper than DIY users due to bulk purchasing power. It is far higher than 10% margin for them in terms of raw hardware costs.
IanCutress - Tuesday, March 5, 2013 - link
The dual E5520 systems from Dell (with 4GB RAM because research department limited us to XP 32-bit) I used for research, with basic storage and a monitor each, ran up to £2k per order back in 2009. After a month of waiting to be delivered (after tons of initial hassle with the department IT guy), it turns out the systems arrived shortly after ordering and our IT guy had decided to hide them in a different building on campus and 'forgot to tell us'. The monitors were in a building the other side of campus. Fun fun fun! Needless to say, we were all rather annoyed. But looking back, I should have just asked for a single powerful Xeon workstation.yougotkicked - Tuesday, March 5, 2013 - link
Yikes, sounds like your IT guy needs to get his act together. We'd never get away with that kind of stuff here.My university has a few super-computing clusters available for researchers running truly large simulations, but because of that many groups choose not to buy systems powerful enough to run their mid-sized simulations and the clusters are usually booked a while in advance. The HP system was purchased primarily because the group was sick of waiting for their simulations to get a turn on the supercomputers.
If only there were a folding@home style client that researchers could easily program for, we could turn our computer labs into compute clusters at night.
colonelpepper - Monday, March 4, 2013 - link
This would be a very poor time to spend thousands of dollars on a high-end 2600 CPUs!The Xeon 2600 series is getting a refresh soon, better to wait and get more CPU for your buck... unless you're dying to spend big $$ now that is:
http://2.bp.blogspot.com/-zhrS1C8wbk0/UHj_HxsrMTI/...
that link is to the largest image I could find of Intel's Xeon Roadmap that was leaked late last year