Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
The Silvermont Module and Caches
Like AMD’s Bobcat and Jaguar designs, Silvermont is modular. The default Silvermont building block is a two-core/two-thread design. Each core is equally capable and there’s no shared execution hardware. Silvermont supports up to 8-core configurations by placing multiple modules in an SoC.
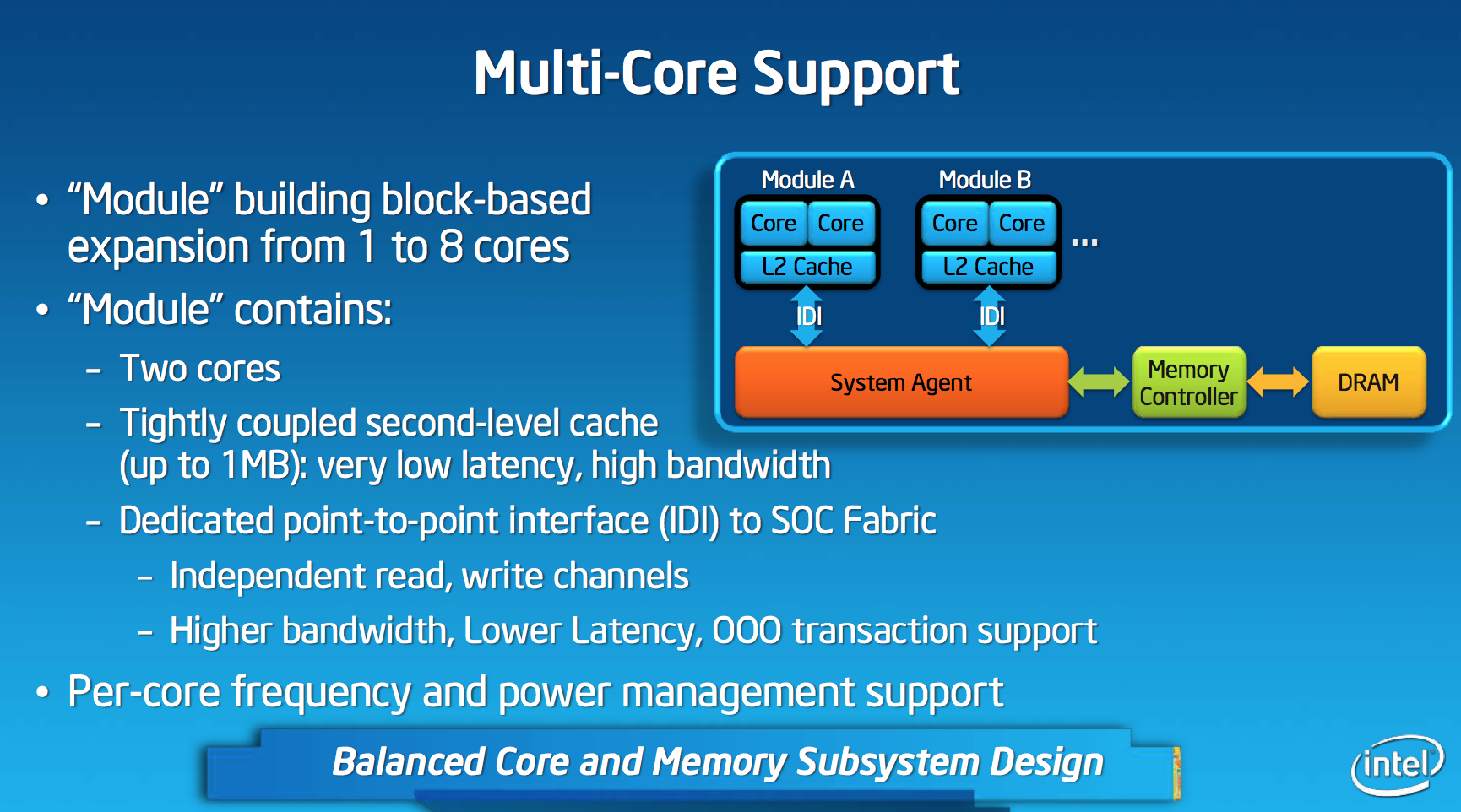
Each module features a shared 1MB L2 cache, a 2x increase over the core:cache ratio of existing Atom based processors. Despite the larger L2, access latency is reduced by 2 clocks. The default module size gives you clear indication as to where Intel saw Silvermont being most useful. At the time of its inception, I doubt Intel anticipated such a quick shift to quad-core smartphones otherwise it might’ve considered a larger default module size.
L1 cache sizes/latencies haven’t changed. Each Silvermont core features a 32KB L1 data cache and 24KB L1 instruction cache.
Silvermont Supports Independent Core Frequencies: Vindication for Qualcomm?
In all Intel Core based microprocessors, all cores are tied to the same frequency - those that aren’t in use are simply shut off (power gated) to save power. Qualcomm’s multi-core architecture has always supported independent frequency planes for all CPUs in the SoC, something that Intel has always insisted was a bad idea. In a strange turn of events, Intel joins Qualcomm in offering the ability to run each core in a Silvermont module at its own independent frequency. You could have one Silvermont core running at 2.4GHz and another one running at 1.2GHz. Unlike Qualcomm’s implementation, Silvermont’s independent frequency planes are optional. In a split frequency case, the shared L2 cache always runs at the higher of the two frequencies. Intel believes the flexibility might be useful in some low cost Silvermont implementations where the OS actively uses core pinning to keep threads parked on specific cores. I doubt we’ll see this on most tablet or smartphone implementations of the design.
From FSB to IDI
Atom and all of its derivatives have a nasty secret: they never really got any latency benefits from integrating a memory controller on die. The first implementation of Atom was a 3-chip solution, with the memory controller contained within the North Bridge. The CPU talked to the North Bridge via a low power Front Side Bus implementation. This setup should sound familiar to anyone who remembers Intel architectures from the late 90s up to the mid 2000s. In pursuit of integration, Intel eventually brought the memory controller and graphics onto a single die. Historically, bringing the memory controller onto the same die as the CPU came with a nice reduction in access latency - unfortunately Atom never enjoyed this. The reasoning? Atom never ditched the FSB interface.
Even though Atom integrated a memory controller, the design logically looked like it did before. Integration only saved Intel space and power, it never granted it any performance. I suspect Intel did this to keep costs down. I noticed the problem years ago but completely forgot about it since it’s been so long. Thankfully, with Silvermont the FSB interface is completely gone.
Silvermont instead integrates the same in-die interconnect (IDI) that is used in the big Core based processors. Intel’s IDI is a lightweight point to point interface that’s far lower overhead than the old FSB architecture. The move to IDI and the changes to the system fabric are enough to improve single threaded performance by low double digits. The gains are even bigger in heavily threaded scenarios.
Another benefit of moving away from a very old FSB to IDI is increased flexibility in how Silvermont can clock up/down. Previously there were fixed FSB:CPU ratios that had to be maintained at all times, which meant the FSB had to be lowered significantly when the CPU was running at very low frequencies. In Silvermont, the IDI and CPU frequencies are largely decoupled - enabling good bandwidth out of the cores even at low frequency levels.
The System Agent
Silvermont gains an updated system agent (read: North Bridge) that’s much better at allowing access to main memory. In all previous generation Atom architectures, virtually all memory accesses had to happen in-order (Clover Trail had some minor OoO improvements here). Silvermont’s system agent now allows reordering of memory requests coming in from all consumers/producers (e.g. CPU cores, GPU, etc...) to optimize for performance and quality of service (e.g. ensuring graphics demands on memory can regularly pre-empt CPU requests when necessary).








174 Comments
View All Comments
Ortanon - Monday, May 6, 2013 - link
This.jamesb2147 - Monday, May 6, 2013 - link
That's not an excuse for subjective fluff. Don't get me wrong, I particularly liked the Bulldozer performance reviews and analysis. The reason I liked them was the hard data used to develop ideas about possible use-case scenarios for the CPU's. This article is full of "IT'S GONNA BE AWESUMMMMMM!!!!!1!!!" and not so much nuanced, objective reporting on actual news. It has plenty of analysis, but without concrete evidence, it reads like one of those all-too-familiar forum rants from HardForum or the like, full of people with too much time and not enough to do.If Anandtech is evolving into one of those news outlets that has to keep writing articles to keep people engaged, then I'm not interested. And it's not just my loss, it's the readership's.
wsw1982 - Tuesday, May 7, 2013 - link
if the clover trail+ already has similar performance as the best ARM offer, and the silvermont is said to be 2 times better than clover trail+. What should be the most logic sentiment in your opinion?phoenix_rizzen - Tuesday, May 7, 2013 - link
Well, you're comparing some future Intel SoC that no one has been allowed to actually touch/test (using only Intel's internal "benchmarking") against currently available ARM SoCs. Who knows what the performance will be like for ARM SoCs in 8-12 months, when these Intel SoCs are actually, physically able to be benchmarked.Cautious optimism is warranted. Not flat-out "OMG, THIS IS THE BESTEST EVAR!" fluff like this article spouts.
Spunjji - Wednesday, May 8, 2013 - link
Restrained optimism and a desire for further evidence. I can only assume Anand has already seen more than us, as his attitude is somewhat more positive than that. If he hasn't, well, I have expressed the opinion before that I find he treats Intel press releases rather lightly.cjb110 - Tuesday, May 7, 2013 - link
tbh that's an OTT response, AnandTech have done a piece based on the info they have and their previous experience. Everything mentioned is reasoned out in a logical progression. You might not always agree with the reasoning but its most certainly isn't 'fluff'. There will be a data based analysis later, as always.Krysto - Monday, May 6, 2013 - link
But not entirely unbiased. Making a detailed analysis and being biased aren't mutually exclusive.Krysto - Monday, May 6, 2013 - link
See asymco.com (apple fanboi doing "indepth analysis" about Android and other competitors.. Guess what? They usually favor Apple).Homeles - Monday, May 6, 2013 - link
I doubt there's a single human being on the face of the planet that is unbiased. What's your point?Thrill92 - Tuesday, May 7, 2013 - link
Oh no, your going to have to do some critical thinking about the data and conclusions in media. What ever will you do?