Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
Sensible Scaling: OoO Atom Remains Dual-Issue
The architectural progression from Apple, ARM and Qualcomm have all been towards wider, out-of-order cores, to varying degrees. With Swift and Krait, Apple and Qualcomm both went wider. From Cortex A8 to A9 ARM went OoO and then from A9 to A15 ARM introduced a significantly wider architecture. Intel bucks the trend a bit by keeping the overall machine width unchanged with Silvermont. This is still a 2-wide architecture.
At the risk of oversimplifying the decision here, Intel had to weigh die area, power consumption as well as the risk of making Atom too good when it made the decision to keep Silvermont’s design width the same as Bonnell. A wider front end would require a wider execution engine, and Intel believed it didn’t need to go that far (yet) in order to deliver really good performance.
Keeping in mind that Intel’s Bonnell core is already faster than ARM’s Cortex A9 and Qualcomm’s Krait 200, if Intel could get significant gains out of Silvermont without going wider - why not? And that’s exactly what’s happened here.
If I had to describe Intel’s design philosophy with Silvermont it would be sensible scaling. We’ve seen this from Apple with Swift, and from Qualcomm with the Krait 200 to Krait 300 transition. Remember the design rule put in place back with the original Atom: for every 2% increase in performance, the Atom architects could at most increase power by 1%. In other words, performance can go up, but performance per watt cannot go down. Silvermont maintains that design philosophy, and I think I have some idea of how.
Previous versions of Atom used Hyper Threading to get good utilization of execution resources. Hyper Threading had a power penalty associated with it, but the performance uplift was enough to justify it. At 22nm, Intel had enough die area (thanks to transistor scaling) to just add in more cores rather than rely on HT for better threaded performance so Hyper Threading was out. The power savings Intel got from getting rid of Hyper Threading were then allocated to making Silvermont an out-of-order design, which in turn helped drive up efficient use of the execution resources without HT. It turns out that at 22nm the die area Intel would’ve spent on enabling HT was roughly the same as Silvermont’s re-order buffer and OoO logic, so there wasn’t even an area penalty for the move.
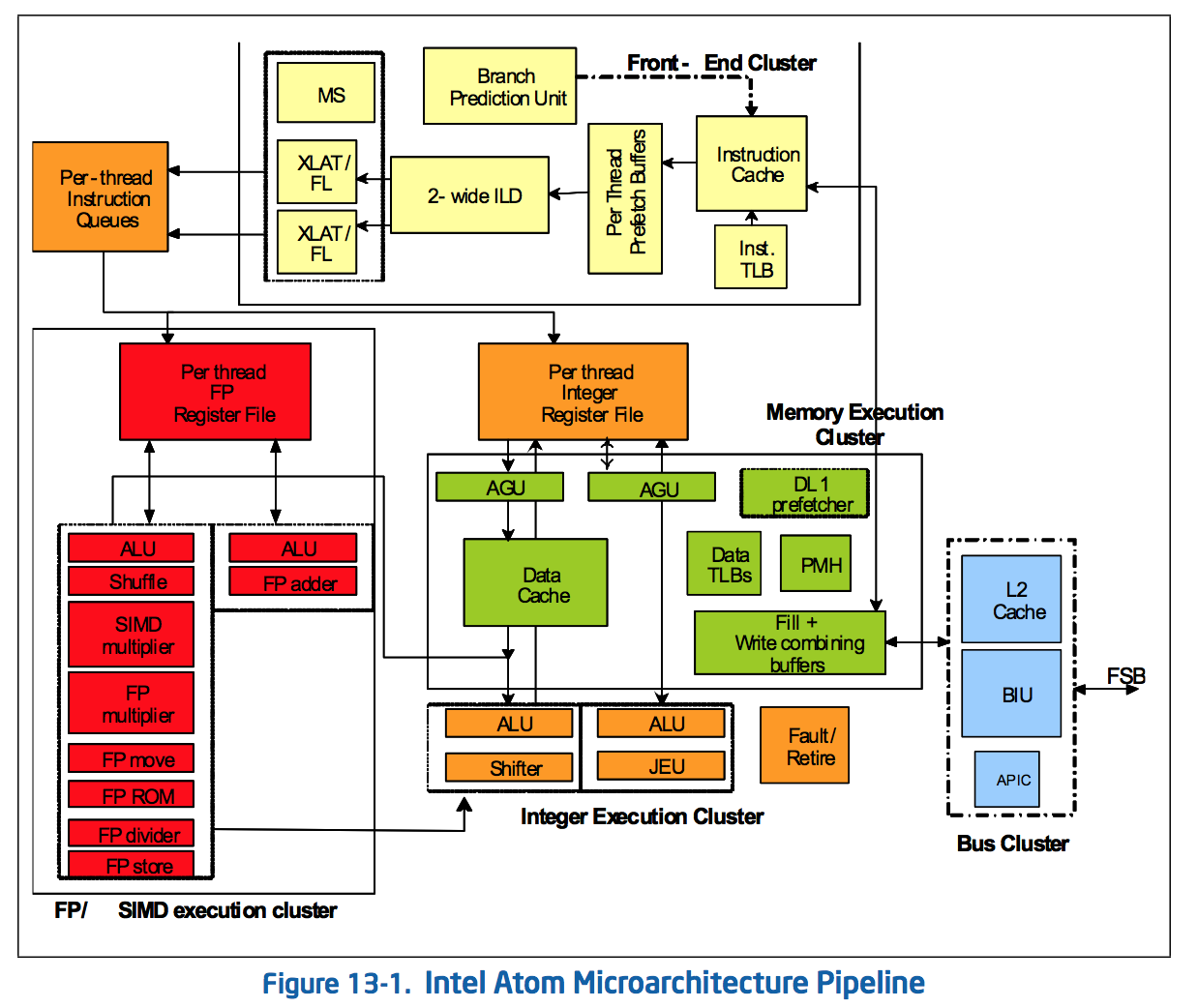
The Original Atom microarchitecture
Remaining a 2-wide architecture is a bit misleading as the combination of the x86 ISA and treating many x86 ops as single operations down the pipe made Atom physically wider than its block diagram would otherwise lead you to believe. Remember that with the first version of Atom, Intel enabled the treatment of load-op-store and load-op-execute instructions as single operations post decode. Instead of these instruction combinations decoding into multiple micro-ops, they are handled like single operations throughout the entire pipeline. This continues to be true in Silvermont, so the advantage remains (it also helps explain why Intel’s 2-wide architecture can deliver comparable IPC to ARM’s 3-wide Cortex A15).
While Silvermont still only has two x86 decoders at the front end of the pipeline, the decoders are more capable. While many x86 instructions will decode directly into a single micro-op, some more complex instructions require microcode assist and can’t go through the simple decode paths. With Silvermont, Intel beefed up the simple decoders to be able to handle more (not all) microcoded instructions.
Silvermont includes a loop stream buffer that can be used to clock gate fetch and decode logic in the event that the processor detects it’s executing the same instructions in a loop.
Execution
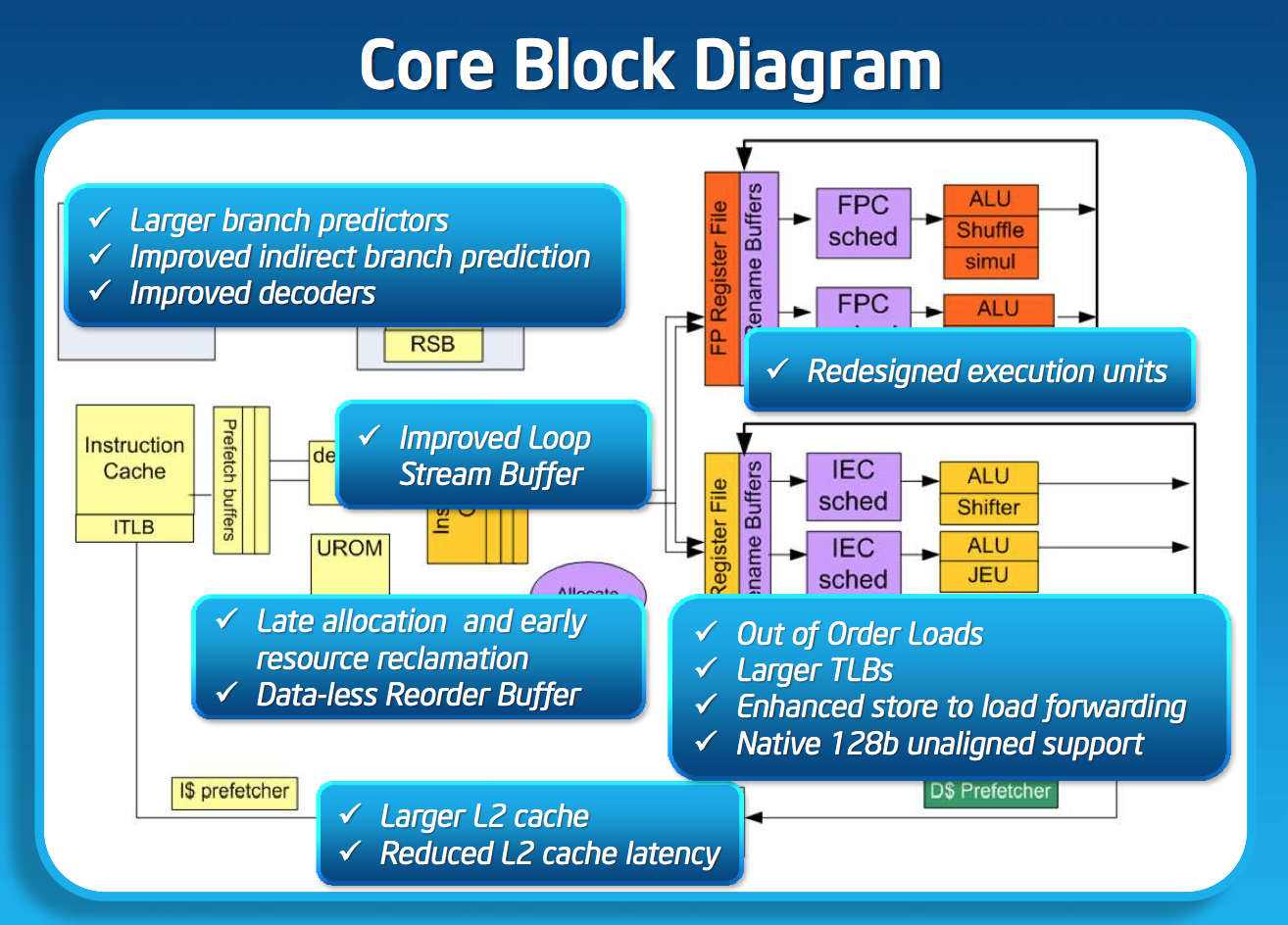
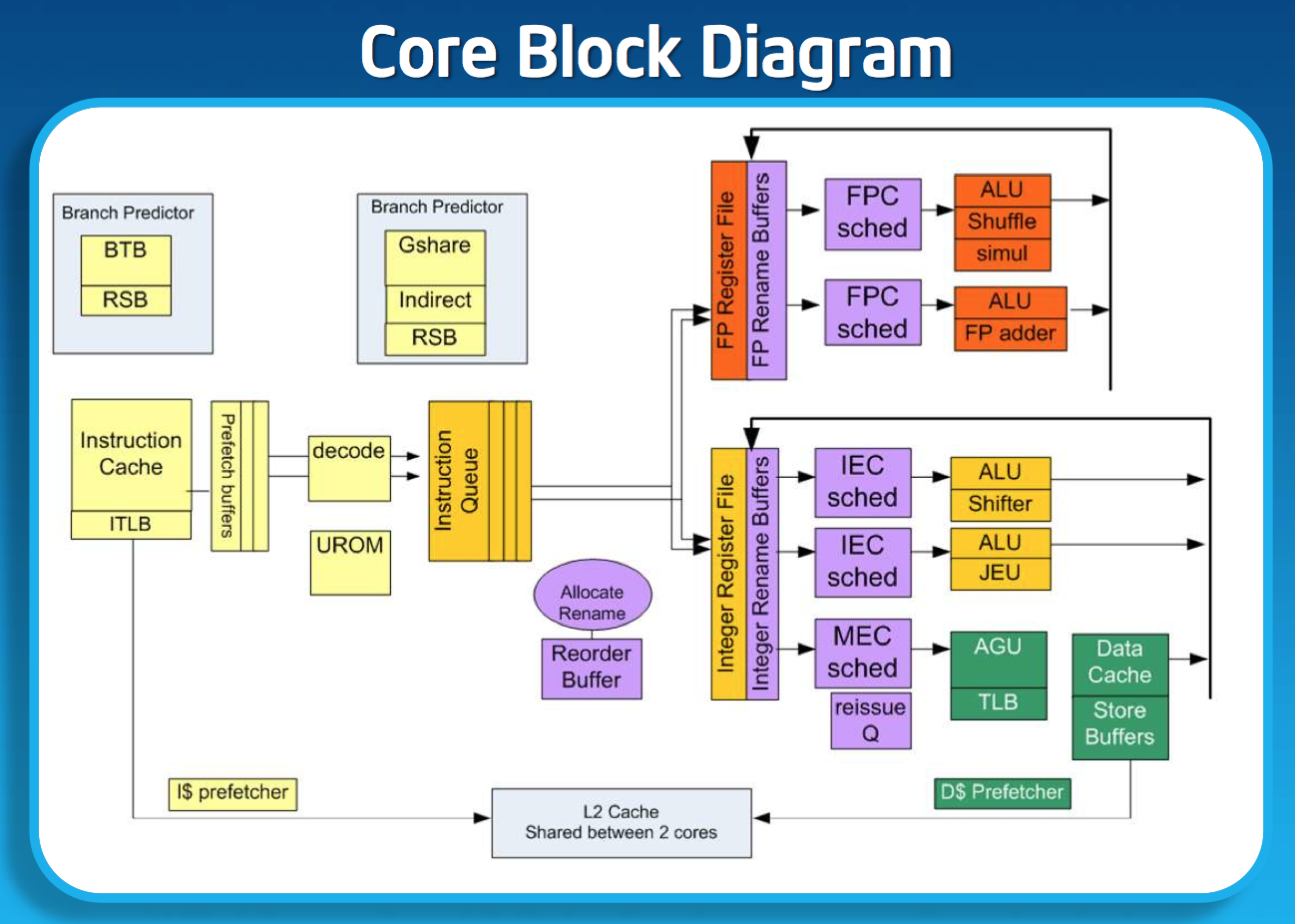
Silvermont’s execution core looks similar to Bonnell before it, but obviously now the design supports out-of-order execution. Silvermont’s execution units have been redesigned to be lower latency. Some FP operations are now quicker, as well as integer multiplies.
Loads can execute out of order. Don’t be fooled by the block diagram, Silvermont can issue one load and one store in parallel.








174 Comments
View All Comments
Spunjji - Wednesday, May 8, 2013 - link
+1chubbypanda - Monday, May 6, 2013 - link
The article is about yet to be relased platform. Obviously you could get better information if you work for Intel or its OEM partners. If you don't, Anand's writing is as good as they get.Thrill92 - Tuesday, May 7, 2013 - link
But what's your point?raptorious - Monday, May 6, 2013 - link
It seems like every subsequent Anandtech article about Intel that I read sounds more and more like an Intel Marketing slide deck. I think I'd believe that the absolute performance of Silvermont is better than Cortex A15, but I'm very skeptical that the perf/watt will actually be better at the TDP that we care about for a tablet. I have a very hard time believing that a 2-wide OoO architecture will get better IPC than a 3-wide one. In order to achieve better performance, you'd have to very aggressively scale frequency, and as we all know, perf/watt usually decreases as you scale frequency up (C*V^2*F). It MIGHT be better perf/watt in a phone, simply because with a 2-wide architecture, you can scale dynamic power much lower, but of course, then you can't make the ridiculous claims of 1.6x performance.JarredWalton - Monday, May 6, 2013 - link
FWIW, Intel is willing to provide these detailed slide decks long in advance of the launch of their hardware. The other SoC vendors are far less willing to share information. If Apple, Qualcomm, or some other vendor put together a nice slide deck, I can guarantee we'd be writing about it.B - Monday, May 6, 2013 - link
@JarredWalton, I completely agree with your assessment. I have listened to every Anandtech Podcast and repeatedly hear Anand and Brian Klug lament the lack of transparency with the other SOC vendors. Those two go through great lengths to get any meaningful information on the roadmaps of Apple, Qualcomm, et al. The bottom line is that currently Intel is accustomed to sharing more information than its peers in the mobile industry and I suspect your readership wants to know what's coming long before the product is released, and this will always include a speculative component.beginner99 - Monday, May 6, 2013 - link
The intel slides basically say intel will have 8x better performance/watt. Now if you don't believe them, just half the numbers and you are at 4x, which is still huge...I believe it.Medfield uses a basically 5 year old design on an older process!!! than current ARM offerings and is competitive in performance/watt (it's actually better already). The only thing is how efficient the GPU will be and even more important how expensive the whole SOC will be. So even if the performance and power data is correct, not guarantee it will succeed.
I do see why some don't like the article but I think Anand is just enthusiastic and lets be honest, AMD has no delivered anything to be enthusiastic about in years and has a history of misinformation on slides What intel disclosed on slides was usually more or less true in the past so they have more credit than AMD.
raptorious - Monday, May 6, 2013 - link
Showing 8x perf/watt or even 4x perf/watt from generation to generation might be possible by milking numbers, but across the board that is laughably impossible. You're talking about defying the laws of physics. This architecture isn't radically different from A15 or other designs, and the process improvements of 22 nm over 32 nm don't just magically give you 4x perf/watt. If you want to live in Intel's fairy tale land, go ahead.JDG1980 - Monday, May 6, 2013 - link
Intel has far better fabs than anyone else. That alone gives them a huge advantage. The reason they've been doing so poorly up until now is that (as the article mentions) they've basically been stagnating with an Atom design dating back to 2004. Now that they've updated to a modern design, they should be able to beat their competitors decisively on the hardware side. Whether that will lead to design wins or not, who can say... they're pretty late to this particular game. But they can give it a good shot.t.s. - Tuesday, May 7, 2013 - link
Yeah, right. Same with AMD. After they 'upgrade' their architecture from star to bulldozer, they automagically have a huge advantage. Remember, changing architecture doesn't necessary a good thing. Moreover for the 1st time you do the change.