Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
Sensible Scaling: OoO Atom Remains Dual-Issue
The architectural progression from Apple, ARM and Qualcomm have all been towards wider, out-of-order cores, to varying degrees. With Swift and Krait, Apple and Qualcomm both went wider. From Cortex A8 to A9 ARM went OoO and then from A9 to A15 ARM introduced a significantly wider architecture. Intel bucks the trend a bit by keeping the overall machine width unchanged with Silvermont. This is still a 2-wide architecture.
At the risk of oversimplifying the decision here, Intel had to weigh die area, power consumption as well as the risk of making Atom too good when it made the decision to keep Silvermont’s design width the same as Bonnell. A wider front end would require a wider execution engine, and Intel believed it didn’t need to go that far (yet) in order to deliver really good performance.
Keeping in mind that Intel’s Bonnell core is already faster than ARM’s Cortex A9 and Qualcomm’s Krait 200, if Intel could get significant gains out of Silvermont without going wider - why not? And that’s exactly what’s happened here.
If I had to describe Intel’s design philosophy with Silvermont it would be sensible scaling. We’ve seen this from Apple with Swift, and from Qualcomm with the Krait 200 to Krait 300 transition. Remember the design rule put in place back with the original Atom: for every 2% increase in performance, the Atom architects could at most increase power by 1%. In other words, performance can go up, but performance per watt cannot go down. Silvermont maintains that design philosophy, and I think I have some idea of how.
Previous versions of Atom used Hyper Threading to get good utilization of execution resources. Hyper Threading had a power penalty associated with it, but the performance uplift was enough to justify it. At 22nm, Intel had enough die area (thanks to transistor scaling) to just add in more cores rather than rely on HT for better threaded performance so Hyper Threading was out. The power savings Intel got from getting rid of Hyper Threading were then allocated to making Silvermont an out-of-order design, which in turn helped drive up efficient use of the execution resources without HT. It turns out that at 22nm the die area Intel would’ve spent on enabling HT was roughly the same as Silvermont’s re-order buffer and OoO logic, so there wasn’t even an area penalty for the move.
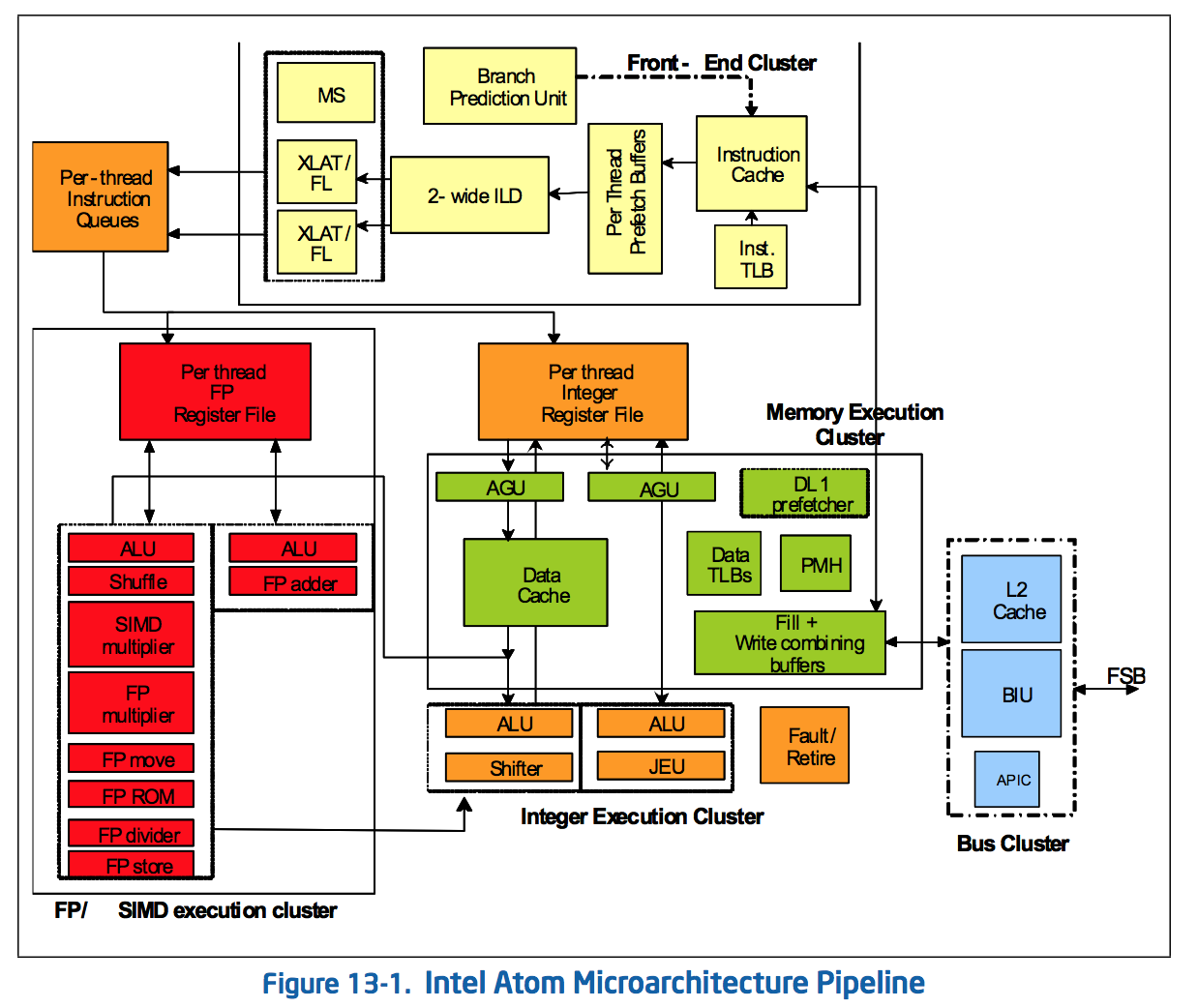
The Original Atom microarchitecture
Remaining a 2-wide architecture is a bit misleading as the combination of the x86 ISA and treating many x86 ops as single operations down the pipe made Atom physically wider than its block diagram would otherwise lead you to believe. Remember that with the first version of Atom, Intel enabled the treatment of load-op-store and load-op-execute instructions as single operations post decode. Instead of these instruction combinations decoding into multiple micro-ops, they are handled like single operations throughout the entire pipeline. This continues to be true in Silvermont, so the advantage remains (it also helps explain why Intel’s 2-wide architecture can deliver comparable IPC to ARM’s 3-wide Cortex A15).
While Silvermont still only has two x86 decoders at the front end of the pipeline, the decoders are more capable. While many x86 instructions will decode directly into a single micro-op, some more complex instructions require microcode assist and can’t go through the simple decode paths. With Silvermont, Intel beefed up the simple decoders to be able to handle more (not all) microcoded instructions.
Silvermont includes a loop stream buffer that can be used to clock gate fetch and decode logic in the event that the processor detects it’s executing the same instructions in a loop.
Execution
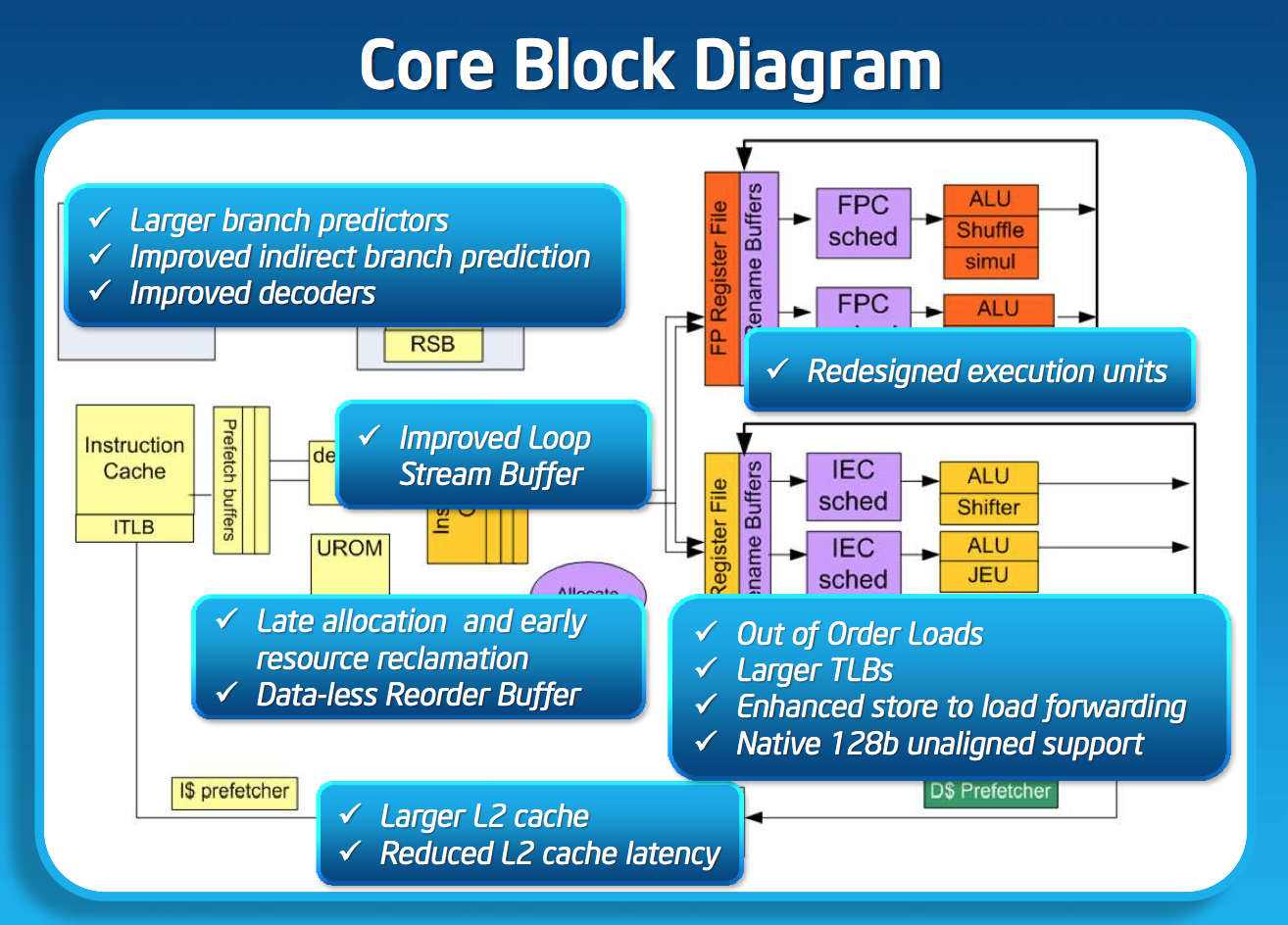
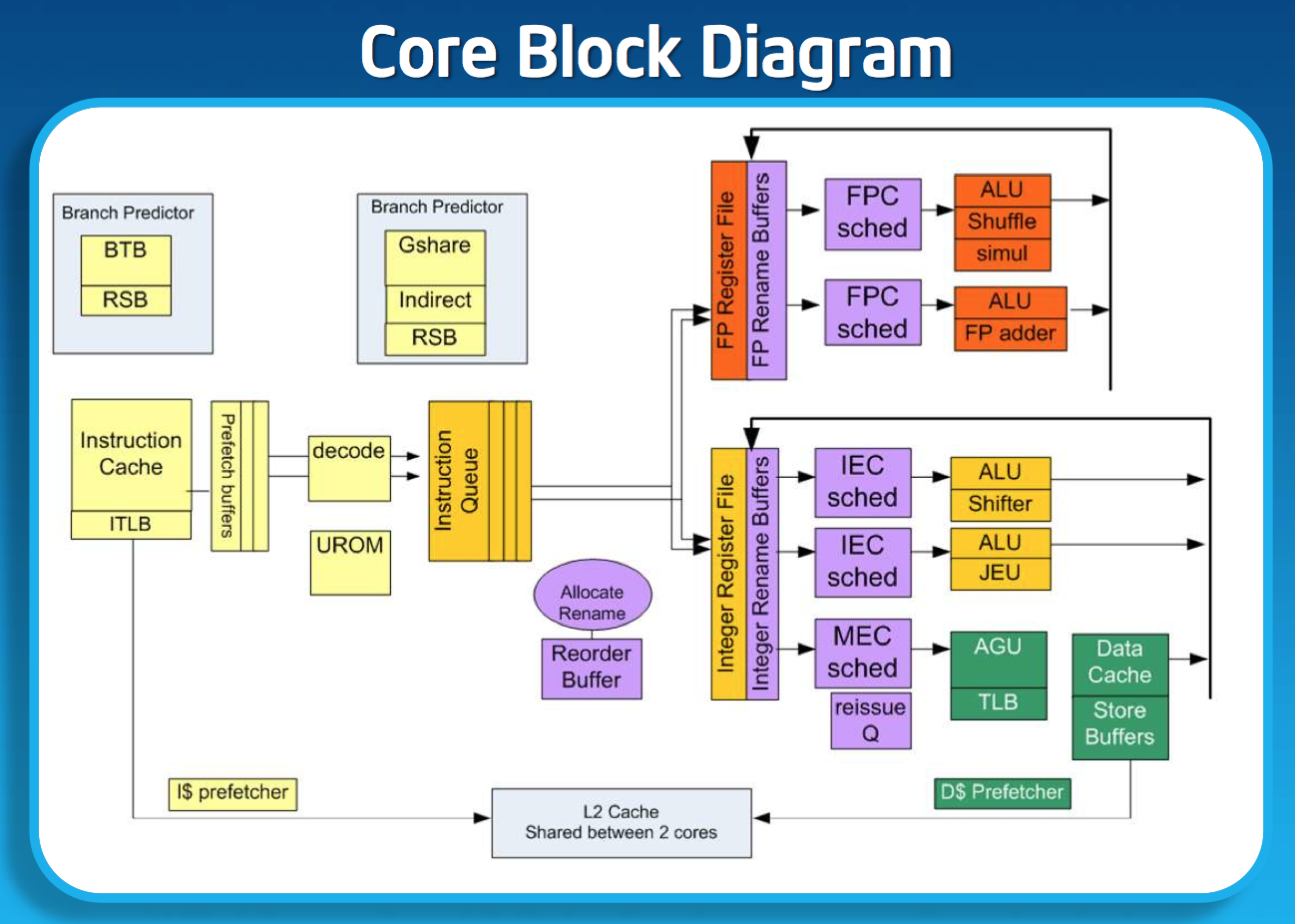
Silvermont’s execution core looks similar to Bonnell before it, but obviously now the design supports out-of-order execution. Silvermont’s execution units have been redesigned to be lower latency. Some FP operations are now quicker, as well as integer multiplies.
Loads can execute out of order. Don’t be fooled by the block diagram, Silvermont can issue one load and one store in parallel.








174 Comments
View All Comments
Homeles - Monday, May 6, 2013 - link
Yay confirmation bias!R0H1T - Tuesday, May 7, 2013 - link
Nay, you fanboi(Intel's) much ?powerarmour - Monday, May 6, 2013 - link
Have to agree, starting to get tired of these almost Intel PR based previews. No mention to how poor Intel's graphics drivers have consistently been over many many years.Homeles - Monday, May 6, 2013 - link
"You can't make the ridiculous claims of 1.6x performance."Sure you can. It was already a close race between a 5 year old architecture and a brand new one. The floodgates have opened -- this is 5 years of pent up performance gains from the largest R&D spender in the industry, on top of being on a significantly superior process for mobile devices.
Wilco1 - Monday, May 6, 2013 - link
Absolute performance of Silvermont cannot be higher than A15 or Bobcat, it's just 2-way OoO, has a single-issue in-order memory pipeline (no speculative execution of memory operations or dual issue of load-store like A15/Bobcat) and fairly small buffers in general. All in all it is more like A9 than A15 or Bobcat/Jaguar.althaz - Monday, May 6, 2013 - link
Except that it certainly can (dependent on a lot of other factors)...That said, I suspect it will only be faster at the same power level, not at the same frequency.
beginner99 - Tuesday, May 7, 2013 - link
That's covered in the article but I must admit I don't fully understand it. Anyway Anand writes about macro-op fusion and clearly states that because of this the 2-wide is misleading when directly comparing to ARM. My interpretation being that ARM doesn't have this and if your 2-wide CPU is running macro-ops with 2 instructions in them it's actually like 4-wide (but I guess this naive viewpoint of mine is completely wrong.Wilco1 - Tuesday, May 7, 2013 - link
No, macro-ops don't make your CPU magically wider. For example Silvermont cannot actually execute 2 load+op instructions every cycle, and cannot even execute 1 read-modify-write every cycle...Also note that most ARM CPUs do have similar capabilities, for example Cortex-A9 can execute 2 shifts and 2 ALU instructions every cycle, and loads and stores can have base update for free. So Anand is quite wrong claiming this is an advantage to Atom.
As I mentioned, the big bottleneck of Silvermont is it's single load/store unit. Typical code contains many loads and stores, and Cortex-A15 can execute these twice as fast as Silvermont.
Jaybus - Wednesday, May 8, 2013 - link
It can, however, execute 1 load and 1 store simultaneously, and that is its saving grace. That fits very well with code being executed in OoO fashion and why I doubt very much A15 is twice as fast executing typical code.Wilco1 - Thursday, May 9, 2013 - link
No Silvermont can only execute 1 load or 1 store per cycle. A15 won't be twice as fast on typical code, but it will beat Silvermont on memory intensive code due to its single memory pipeline bottleneck.