The NVIDIA GeForce GTX 980 Review: Maxwell Mark 2
by Ryan Smith on September 18, 2014 10:30 PM ESTMaxwell 2’s New Features: Direct3D 11.3 & VXGI
When NVIDIA introduced the Maxwell 1 architecture and the GM107 based GTX 750 series, one of the unexpected aspects of their decision was to release these parts as members of the existing 700 series rather than a newer series to communicate a difference in features. However as it turned out there really wasn’t a feature difference between it and Kepler; other than a newer NVENC block, Maxwell 1 was for all intents and purposes an optimized Kepler architecture. It was the same features built upon the efficiency improvements of the Maxwell architecture.
With that in mind, along with the hardware/architectural changes we’ve listed earlier, the other big factor that sets Maxwell 2 apart from Maxwell 1 is its feature set. In that respect Maxwell 2 is almost a half-generational update on its own, as it implements a number of new features that were not present in Maxwell 1. This means Maxwell 2 is bringing some new features that we need to cover, but it also means that the GM204 based GTX 900 series is feature differentiated from the GTX 600/700 series in a way that the earlier GTX 750 series was not.
Direct3D 11.3
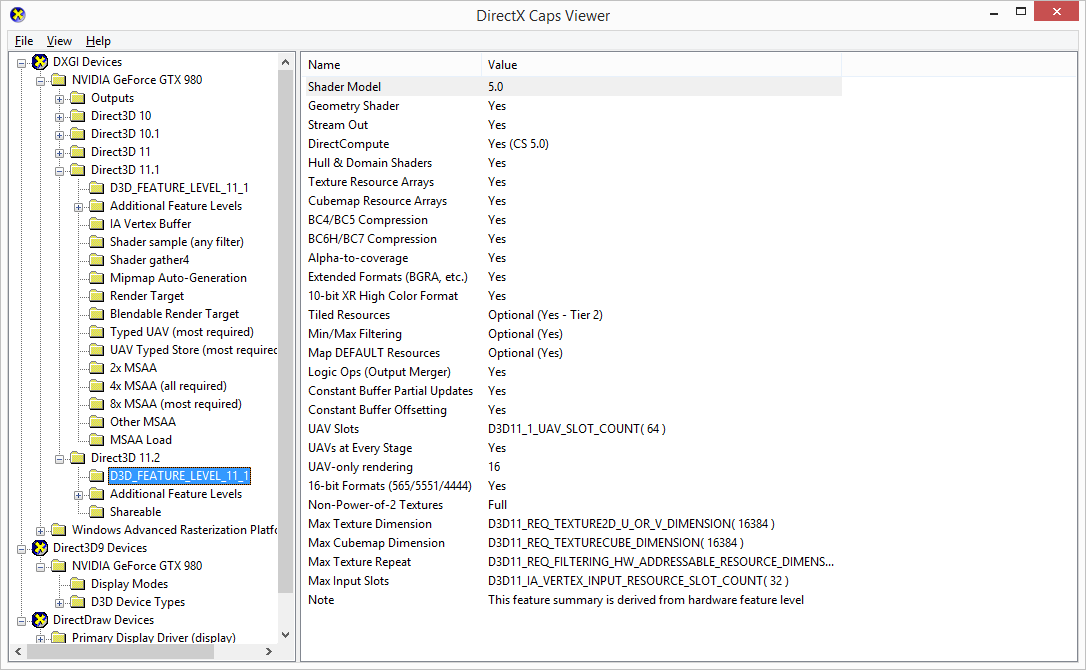
First and foremost among Maxwell 2’s new features is the inclusion of full Direct3D 11.2/11.3 compatibility. Kepler and Maxwell 1 before it were officially feature level 11_0, but they contained an almost complete set of FL 11_1 features, allowing most of these features to be accessed through cap bits. With Maxwell 2 however, NVIDIA has finally implemented the remaining features required for FL11_1 compatibility and beyond, updating their architecture to support the 16x raster coverage sampling required for Target Independent Rasterization and UAVOnlyRenderingForcedSampleCount.
This extended feature set also extends to Direct3D 11.2, which although it doesn’t have an official feature level of its own, does introduce some new (and otherwise optional) features that are accessed via cap bits. Key among these, Maxwell 2 will support the more advanced Tier 2 tiled resources, otherwise known as sparse textures or partially resident textures. Tier 2 was introduced into the specification to differentiate the more capable AMD implementation of this feature from NVIDIA’s hardware, and now as of Maxwell 2 NVIDIA can support the more advanced functionality required for Tier 2.
Finally, Maxwell will also support the features being introduced in Direct3D 11.3 (and made available to D3D 12), which was announced alongside Maxwell at NVIDIA’s editors’ day event. We have a separate article covering Direct3D 11.3, so we won’t completely retread that ground here, but we will cover the highlights.
The forthcoming Direct3D 11.3 features, which will form the basis (but not entirety) of what’s expected to be feature level 11_3, are Rasterizer Ordered Views, Typed UAV Load, Volume Tiled Resources, and Conservative Rasterization. Maxwell 2 will offer full support for these forthcoming features, and of these features the inclusion of volume tiled resources and conservative rasterization is seen as being especially important by NVIDIA, particularly since NVIDIA is building further technologies off of them.
Volume tiled resources is for all intents and purposes tiled resources extended into the 3rd dimension. Volume tiled resources are primarily meant to be used with 3D/volumetric pixels (voxels), with the idea being that with sparse allocation, volume tiles that do not contain any useful information can avoid being allocated, avoiding tying up memory in tiles that will never be used or accessed. This kind of sparse allocation is necessary to make certain kinds of voxel techniques viable.

Meanwhile conservative rasterization is also new to Maxwell 2. Conservative rasterization is essentially a more accurate but performance intensive solution to figuring out whether a polygon covers part of a pixel. Instead of doing a quick and simple test to see if the center of the pixel is bounded by the lines of the polygon, conservative rasterization checks whether the pixel covers the polygon by testing it against the corners of the pixel. This means that conservative rasterization will catch cases where a polygon was too small to cover the center of a pixel, which results in a more accurate outcome, be it better identifying pixels a polygon resides in, or finding polygons too small to cover the center of any pixel at all.
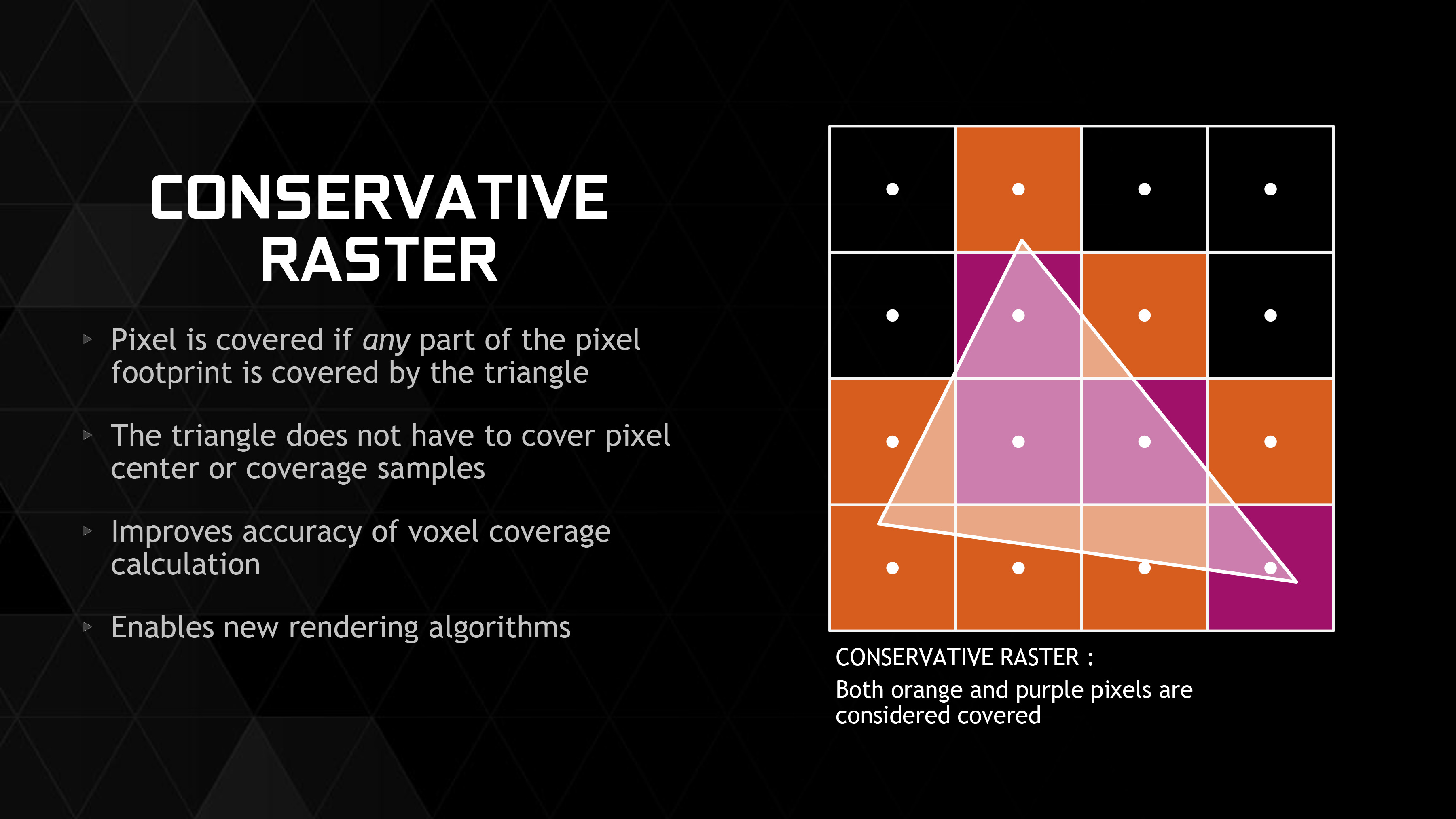
Conservative rasterization is being added to Direct3D in order to allow new algorithms to be used which would fail under the imprecise nature of point sampling. Like VTR, voxels play a big part here as conservative rasterization can be used to build a voxel. However it also has use cases in more accurate tiling and even collision detection. This feature is technically possible in existing hardware, but the performance of such an implementation would be very low as it’s essentially a workaround for the lack of necessary support in the rasterizers. By implementing conservative rasterization directly in hardware, Maxwell 2 will be able to perform the task far more quickly, which is necessary to make the resulting algorithms built on top of this functionality fast enough to be usable.
VXGI
Outside of the features covered by Direct3D 11.3, NVIDIA will also be adding features specifically to drive a new technology they are calling Voxel accelerated Global Illumination (VXGI).
At the highest level, VXGI is a manner of implementing global illumination by utilizing voxels in the calculations. Global illumination is something of a holy grail for computer graphics, as it can produce highly realistic and accurate lighting dynamically in real time. However global illumination is also very expensive, the path tracing involved taking up considerable time and resources. For this reason developers have played around with global illumination in the past – the original version of Epic’s Unreal 4 Engine Elemental demo implanted a voxel based global illumination method, for example – but it has always been too slow for practical use.

With VXGI NVIDIA is looking to solve the voxel global illumination problem through a combination of software and hardware. VXGI proper is the software component, and describes the algorithm being used. NVIDIA has been doing considerable research into voxel based global illumination over the years, and has finally reached a point where they have an algorithm ready to go in the form of VXGI.
VXGI will eventually be made available for Unreal Engine 4 and other major game engines starting in Q4 of this year. And while the VXGI greatly benefits from the hardware features built into Maxwell 2, it is not strictly reliant on the hardware and can be implemented through more traditional means on existing hardware. VXGI is if nothing else scalable, with the algorithm being designed to scale up and down with hardware by adjusting the density of the voxel grid, which in turn influences the number of calculations required and the resulting accuracy. Maxwell 2 for its part will be capable of using denser grids due to its hardware acceleration capabilities, allowing for better performance and more accurate lighting.

It’s at this point we’ll take a break and apologize to NVIDIA’s engineers for blowing through VXGI so quickly. This is actually a really interesting technology, as global illumination offers the possibility of finally attaining realistic real-time lighting in any kind of rendered environment. However VXGI is also a complex technology that is a subject in and of itself, and we could spend all day just covering it (we’d need to cover rasterization and path tracing to fully explain it). Instead we’d suggest reading NVIDIA’s own article on the technology once that is posted, as NVIDIA is ready and willing to go into great detail in how the technology works.
Getting back to today’s launch then, the other aspect of VXGI is the hardware features that NVIDIA has implemented to accelerate the technology. Though a big part of VXGI remains brute forcing through the path and cone tracing, the other major aspect of VXGI is building the voxel grids used in these calculations. It’s here where NVIDIA has pulled together the D3D 11.3 feature set, along with additional hardware features, to greatly accelerate the process of creating the voxel grid in order to speed up the overall algorithm.
From the D3D 11.3 feature set, conservative rasterization and volumetric tiled resources will play a big part. Conservative rasterization allows the creation of more accurate voxels, owing to the more accurate determination of whether a pixel/voxel covers a given polygon. Meanwhile volumetric tiled resources will allow for the space efficient storage of voxels, allowing software to store only the voxels it needs and not the many empty voxels that would otherwise be present in a scene.
Joining these features as the final VXGI-centric feature for Maxwell 2 is a feature NVIDIA is calling Multi-Projection Acceleration. The idea behind MPA is that there are certain scenarios where the same geometry needs to be projected multiple times – voxels being a big case of this due to being 6 sided – and that for performance reasons it is desirable to do all of these projections much more quickly than simply iterating though every necessary projection in shaders. In these scenarios being able to quickly project geometry to all the necessary surfaces is a significant performance advantage.
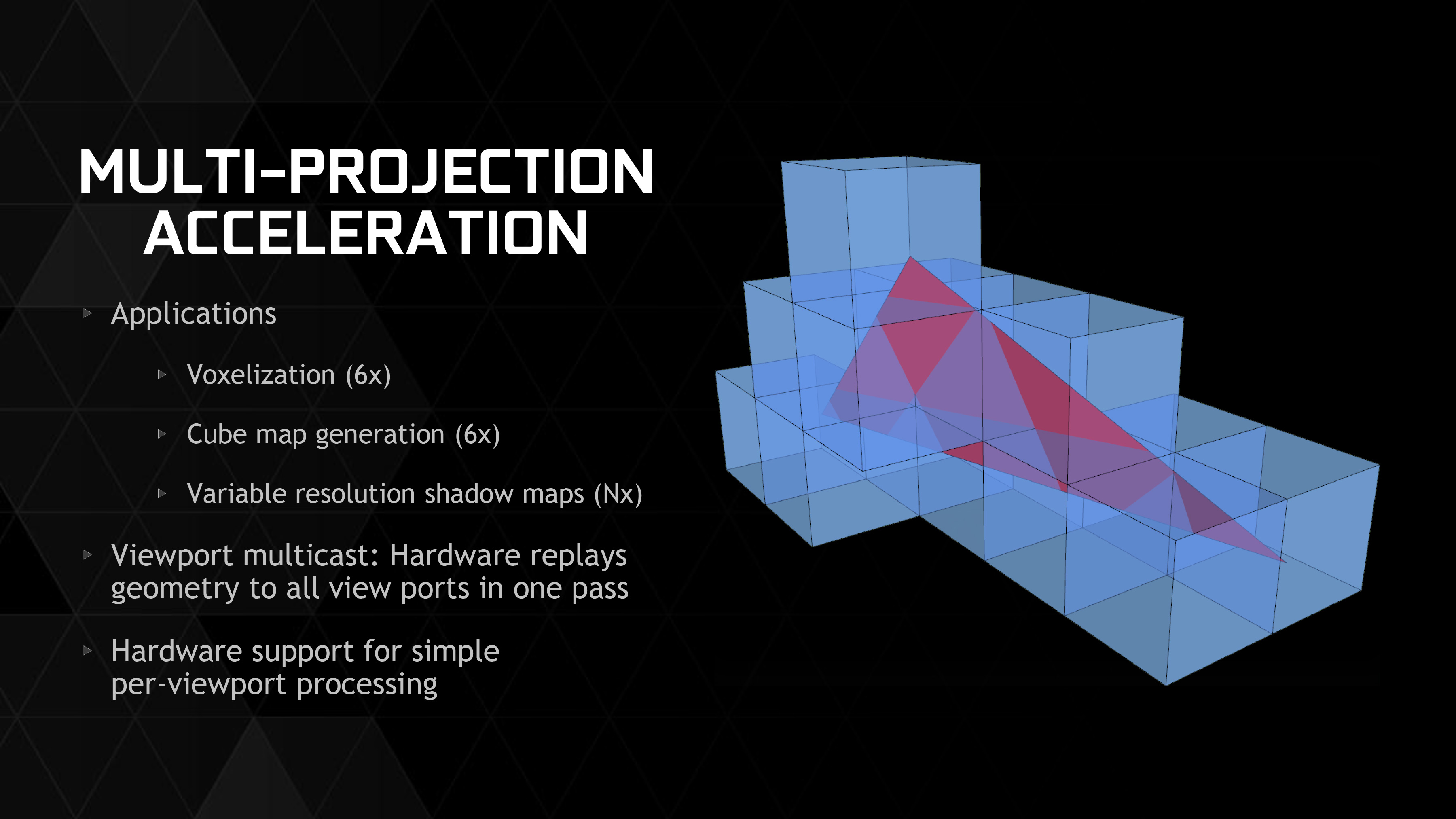
A big part of MPA is a sub-feature called viewport multicast. In viewport multicast Maxwell 2 can replay the necessary geometry to all of the viewports in a single pass. At the hardware level this involves giving the hardware the ability to automatically determine when it needs to engage in viewport multicast, based on its understanding of the workload it's receiving. This is once again a case where something is being done in a fixed-function like fashion for performance reasons, rather than being shuffled off to slower shader hardware.
Alongside voxelization, NVIDIA tells us that MPA should also be applicable to cube map generation and shadow map generation. Both of which make plenty of sense in this case: in both scenarios you are projecting the same geometry multiple times, whether it’s to faces of a cube or to shadow maps of increasing resolution. As a result MPA should have some benefits even in renderers that aren’t using VXGI, though clearly the greatest benefits are still going to be when VXGI is in play.
NVIDIA believes that the overall performance improvement to voxelization from these technologies will be very significant. In their own testing of the technology in rendering a scene set in San Miguel de Allende, Mexico (a common test scene for global illumination), NVIDIA has found that Maxwell 2’s hardware acceleration features tripled their voxelization performance.
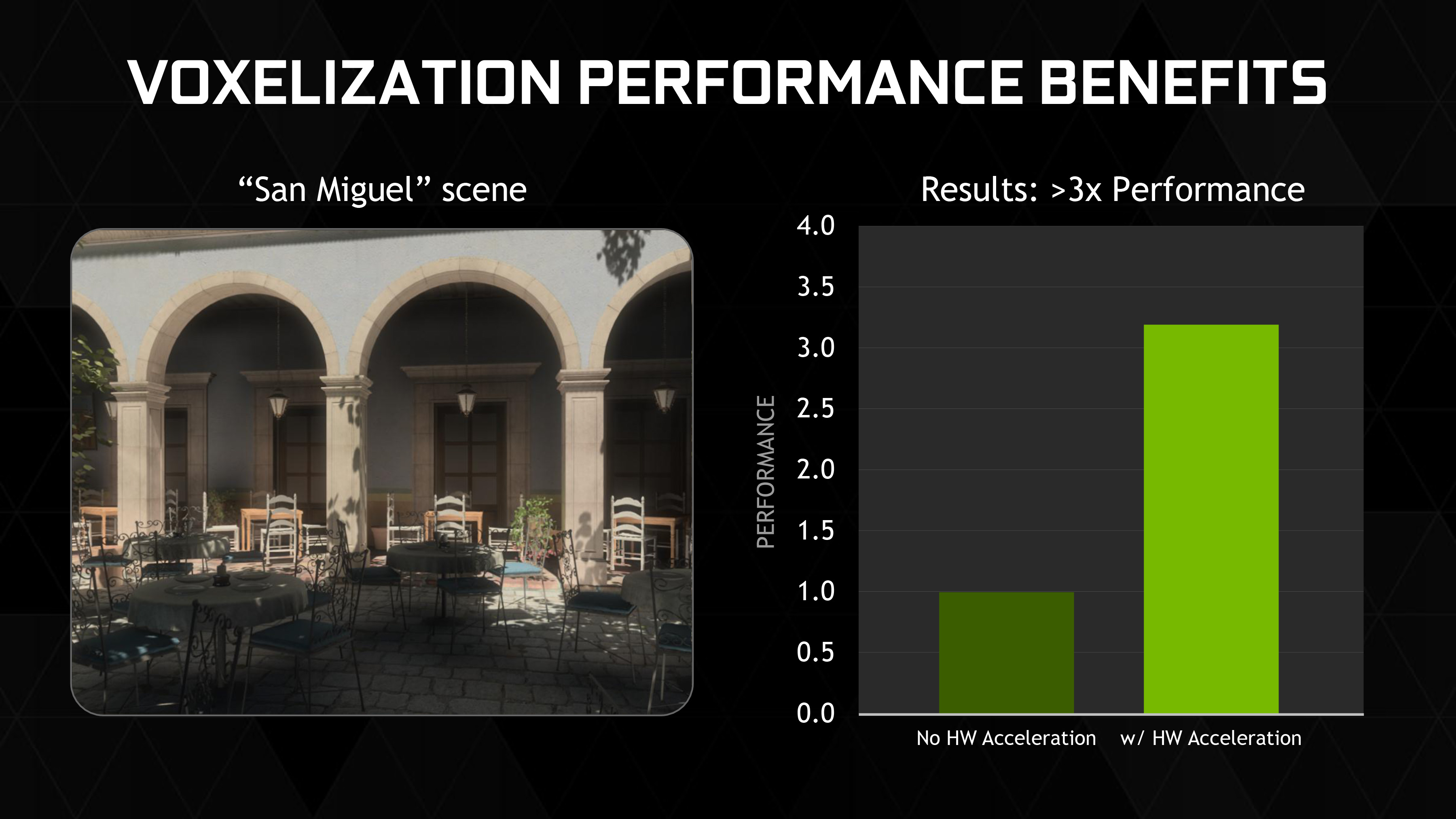
Overall NVIDIA is heavily betting on VXGI at this time both to further set apart Maxwell 2 based cards from the competition, and to further advance the state of PC graphics. In the gaming space in particular NVIDIA has a significant interest in making sure PC games aren’t just straight console ports that run at higher framerates and resolutions. This is the situation that has spurred on the development of GameWorks and technologies like VXGI, so that game developers can enhance the PC ports of their games with technologies that improve their overall rendering quality. Maxwell 2 in turn is the realization that while some of these features can be performed in software/shaders on today’s hardware, these features will be even more useful and impressive when backed with dedicated hardware to improve their performance.
Finally, we’ll close out our look at VXGI with a preview of NVIDIA’s GTX 900 series tech demo, which is a rendered recreation of a photo/scene involving Buzz Aldrin and the Apollo 11 moon landing. The Apollo 11 demo is designed to show off the full capabilities of VXGI, utilizing the lighting technique to correctly and dynamically emulate specular, diffuse, and other forms of lighting that occur in reality. At editors’ day NVIDIA originally attempted to pass off the rendering as the original photo, and while after a moment it’s clear that it’s a rendering – among other things it lacks the graininess of a 1969 film based camera – it comes very, very close. In showcasing the Apollo 11 tech demo, NVIDIA’s hope is that one day games will be able to achieve similarly accurate lighting effects through the use of VXGI.
















274 Comments
View All Comments
TheJian - Saturday, September 20, 2014 - link
http://blogs.nvidia.com/blog/2014/09/19/maxwell-an...Did I miss it in the article or did you guys just purposely forget to mention NV claims it does DX12 too? see their own blog. Microsoft's DX12 demo runs on ...MAXWELL. Did I just miss the DX12 talk in the article? Every other review I've read mentions this (techpowerup, tomshardware, hardocp etc etc). Must be that AMD Center still having it's effect on your articles ;)
They were running a converted elemental demo (converted to dx12) and Fable Legends from MS. Yet curiously missing info from this site's review. No surprise I guess with only an AMD portal still :(
From the link above:
"Part of McMullen’s presentation was the announcement of a broadly accessible early access program for developers wishing to target DX12. Microsoft will supply the developer with DX12, UE4-DX12 and the source for Epic’s Elemental demo ported to run on the DX12-based engine. In his talk, McMullen demonstrated Maxwell running Elemental at speed and flawlessly. As a development platform for this effort, NVIDIA’s GeForce GPUs and Maxwell in particular is a natural vehicle for DX12 development."
So maxwell is a dev platform for dx12, but you guys leave that little detail out so newbs will think it doesn't do it? Major discussion of dx11 stuff missing before, now up to 11.3 but no "oh and it runs all of dx12 btw".
One more comment on 980: If it's a reference launch how come other sites already have OC versions (IE, tomshardware has a Windforce OC 980, though stupidly as usual they downclocked it and the two OC/superclocked 970's they had to ref clocks...ROFL - like you'd buy an OC card and downclock them)? IT seems to be a launch of OC all around. Newegg even has them in stock (check EVGA OC version):
http://www.newegg.com/Product/Product.aspx?Item=N8...
And with a $10 rebate so only $559 and a $5 gift card also.
"This model is factory overclocked to 1241 MHz Base Clock/1342 MHz Boost Clock (1126 MHz/1216 MHz for reference design)"
Who would buy ref for $10 diff? IN fact the ref cards are $569 at newegg, so you save buying the faster card...LOL.
cactusdog - Saturday, September 20, 2014 - link
TheJian, Wow, Did you read the article? Did you read the conclusion? AT says the 980 is "remarkable" , "well engineered", "impeccable design" and has "no competition" They covered almost all of Nvidia marketing talking points and you're going to accuse them of a conspiracy? Are you fking retarded??Daniel Egger - Saturday, September 20, 2014 - link
It would be nice to rather than just talk about about the 750 Ti to also include it in comparisons to see it clearer in perspective what it means to go from Maxwell I to Maxwell II in terms of performance, power consumption, noise and (while we are at it) performance per Watt and performance per $.Also where're the benchmarks for the GTX 970? I sure respect that this card is in a different ballpark but the somewhat reasonable power output might actually make the GTX 970 a viable candidate for an HTPC build. Is it also possible to use it with just one additional 6 Pin connector (since as you mentioned this would be within the specs without any overclocking) or does it absolutely need 2 of them?
SkyBill40 - Saturday, September 20, 2014 - link
As was noted in the review at least twice, they were having issues with the 970 and thus it won't be tested in full until next week (along with the 980 in SLI).MrSpadge - Saturday, September 20, 2014 - link
Wow! This makes me upgrade from a GTX660Ti - not because of gaming (my card is fast enough for my needs) but because of the power efficiency gains for GP-GPU (running GPU-Grid under BOINC). Thank you nVidia for this marvelous chip and fair prices!jarfin - Saturday, September 20, 2014 - link
i still CANT understand amd 'uber' option.its totally out of test,bcoz its just 'oc'd' button,nothing else.
its must be just r290x and not anantech 'amd canter' way uber way.
and,i cant help that feeling,what is strong,that anatech is going badly amd company way,bcoz they have 'amd center own sector.
so,its mean ppl cant read them review for nvidia vs radeon cards race without thinking something that anatech keep raden side way or another.
and,its so clear thats it.
btw
i hope anantech get clear that amd card R9200 series is just competition for nvidia 90 series,bcoz that every1 kow amd skippedd 8000 series and put R9 200 series for nvidia 700 series,but its should be 8000 series.
so now,generation of gpu both side is even.
meaning that next amd r9 300 series or what it is coming amd company battle nvidia NEXT level gpu card,NOT 900 series.
there is clear both gpu card history for net.
thank you all
p.s. where is nvidia center??
Gigaplex - Saturday, September 20, 2014 - link
Uber mode is not an overclock. It's a fan speed profile change to reduce thermal throttling (underclock) at the expense of noise.dexgen - Saturday, September 20, 2014 - link
Ryan, Is it possible to see the average clock speeds in different tests after increasing the power and temperature limit in afterburner?And also once the review units for non-reference cards come in it would be very nice to see what the average clock speeds for different cards with and without increased power limit would be. That would be a great comparison for people deciding which card to buy.
silverblue - Saturday, September 20, 2014 - link
Exceptional by NVIDIA; it's always good to see a more powerful yet more frugal card especially at the top end.AMD's power consumption could be tackled - at least partly - by some re-engineering. Do they need a super-wide memory bus when NVIDIA are getting by with half the width and moderately faster RAM? Tonga has lossless delta colour compression which largely negates the need for a wide bus, although they did shoot themselves in the foot by not clocking the memory a little higher to anticipate situations where this may not help the 285 overcome the 280.
Perhaps AMD could divert some of their scant resources towards shoring up their D3D performance to calm down some of the criticism because it does seem like they're leaving performance on the table and perhaps making Mantle look better than it might be as a result.
Luke212 - Saturday, September 20, 2014 - link
Where are the SGEMM compute benchmarks you used to put on high end reviews?