ARM's Cortex A57 and Cortex A53: The First 64-bit ARMv8 CPU Cores
by Anand Lal Shimpi on October 30, 2012 11:58 AM EST- Posted in
- CPUs
- IT Computing
- Arm
- Cloud Computing
- SoCs
Yesterday AMD revealed that in 2014 it would begin production of its first ARMv8 based 64-bit Opteron CPUs. At the time we didn't know what core AMD would use, however today ARM helped fill in that blank for us with two new 64-bit core announcements: the ARM Cortex-A57 and Cortex-A53.
You may have heard of ARM's Cortex-A57 under the codename Atlas, while A53 was referred to internally as Apollo. The two are 64-bit successors to the Cortex A15 and A7, respectively. Similar to their 32-bit counterparts, the A57 and A53 can be used independently or in a big.LITTLE configuration. As a recap, big.LITTLE uses a combination of big (read: power hungry, high performance) and little (read: low power, lower performance) ARM cores on a single SoC.

By ensuring that both the big and little cores support the same ISA, the OS can dynamically swap the cores in and out of the scheduling pool depending on the workload. For example, when playing a game or browsing the web on a smartphone, a pair of A57s could be active, delivering great performance at a high power penalty. On the other hand, while just navigating through your phone's UI or checking email a pair of A53s could deliver adequate performance while saving a lot of power. A hypothetical SoC with two Cortex A57s and two Cortex A53s would still only appear to the OS as a dual-core system, but it would alternate between performance levels depending on workload.
 ARM's Cortex A57
ARM's Cortex A57
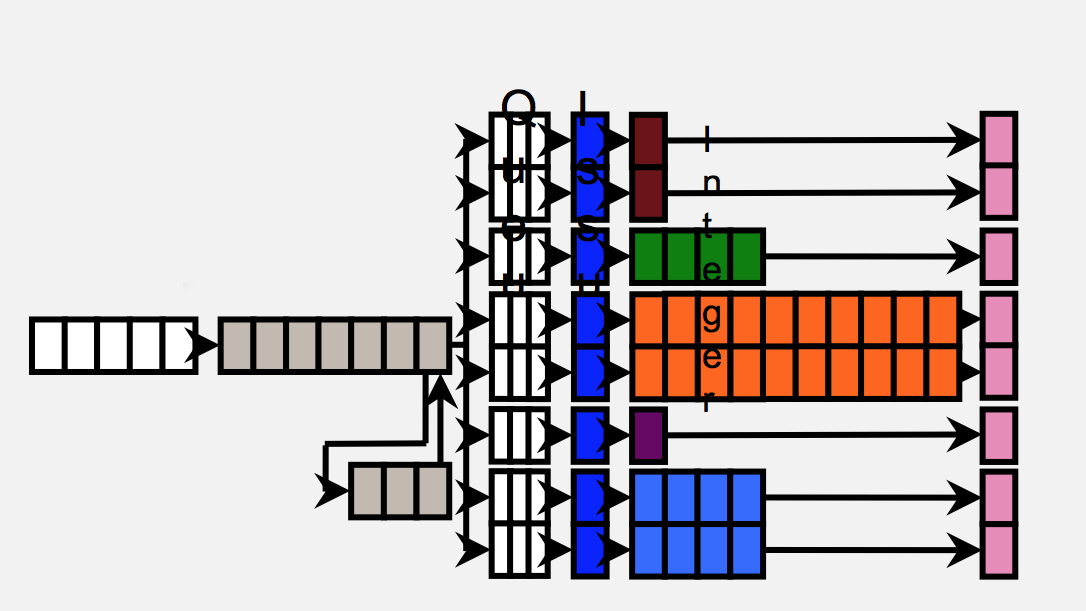
Architecturally, the Cortex A57 is much like a tweaked Cortex A15 with 64-bit support. The CPU is still a 3-wide/3-issue machine with a 15+ stage pipeline. ARM has increased the width of NEON execution units in the Cortex A57 (128-bits wide now?) as well as enabled support for IEEE-754 DP FP. There have been some other minor pipeline enhancements as well. The end result is up to a 20 - 30% increase in performance over the Cortex A15 while running 32-bit code. Running 64-bit code you'll see an additional performance advantage as the 64-bit register file is far simplified compared to the 32-bit RF.
The Cortex A57 will support configurations of up to (and beyond) 16 cores for use in server environments. Based on ARM's presentation it looks like groups of four A57 cores will share a single L2 cache.
ARM's Cortex A53
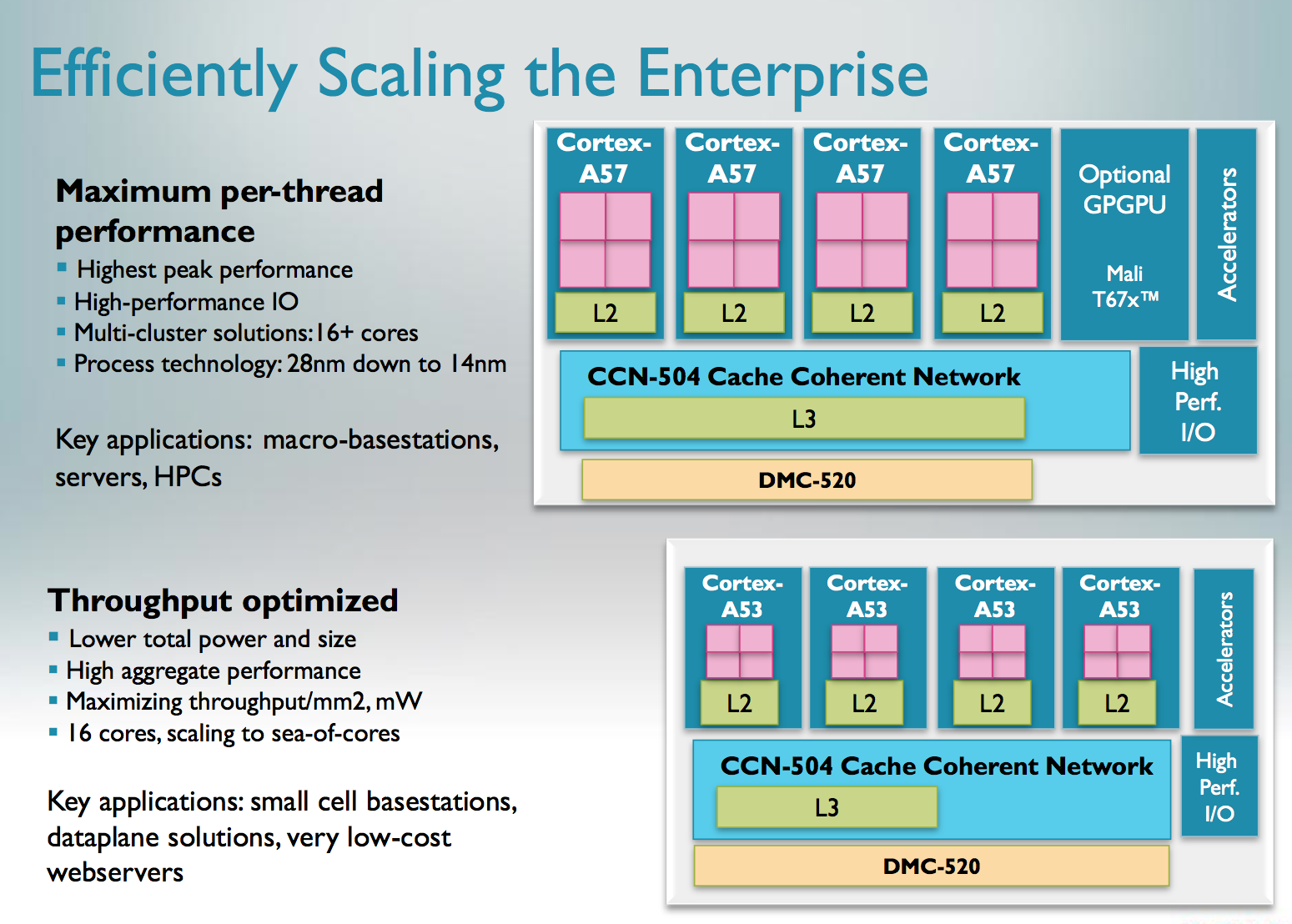
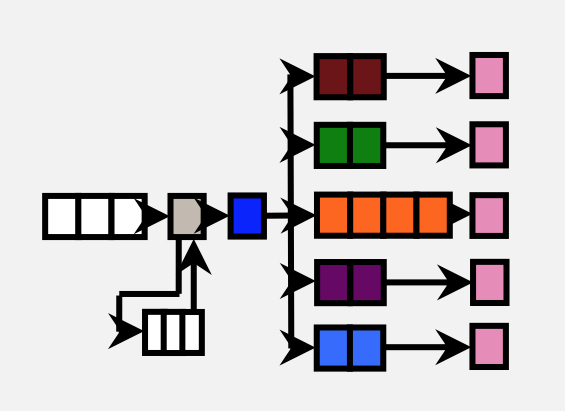
Similarly, the Cortex A53 is a tweaked version of the Cortex A7 with 64-bit support. ARM didn't provide as many details here other than to confirm that we're still looking at a simple, in-order architecture with an 8 stage pipeline. The A53 can be used in server environments as well since it's ISA compatible with the A57.

ARM claims that on the same process node (32nm) the Cortex A53 is able to deliver the same performance as a Cortex A9 but at roughly 60% of the die area. The performance claims apply to both integer and floating point workloads. ARM tells me that it simply reduced a lot of the buffering and data structure size, while more efficiently improving performance. From looking at Apple's Swift it's very obvious that a lot can be done simply by improving the memory interface of ARM's Cortex A9. It's possible that ARM addressed that shortcoming while balancing out the gains by removing other performance enhancing elements of the core.

Both CPU cores are able to run 32-bit and 64-bit ARM code, as well as a mix of both so long as the OS is 64-bit.
Completed Cortex A57 and A53 core designs will be delivered to partners (including AMD and Samsung) by the middle of next year. Silicon based on these cores should be ready by late 2013/early 2014, with production following 6 - 12 months after that. AMD claimed it would have an ARMv8 based Opteron in production in 2014, which seems possible (although aggressive) based on what ARM told me.
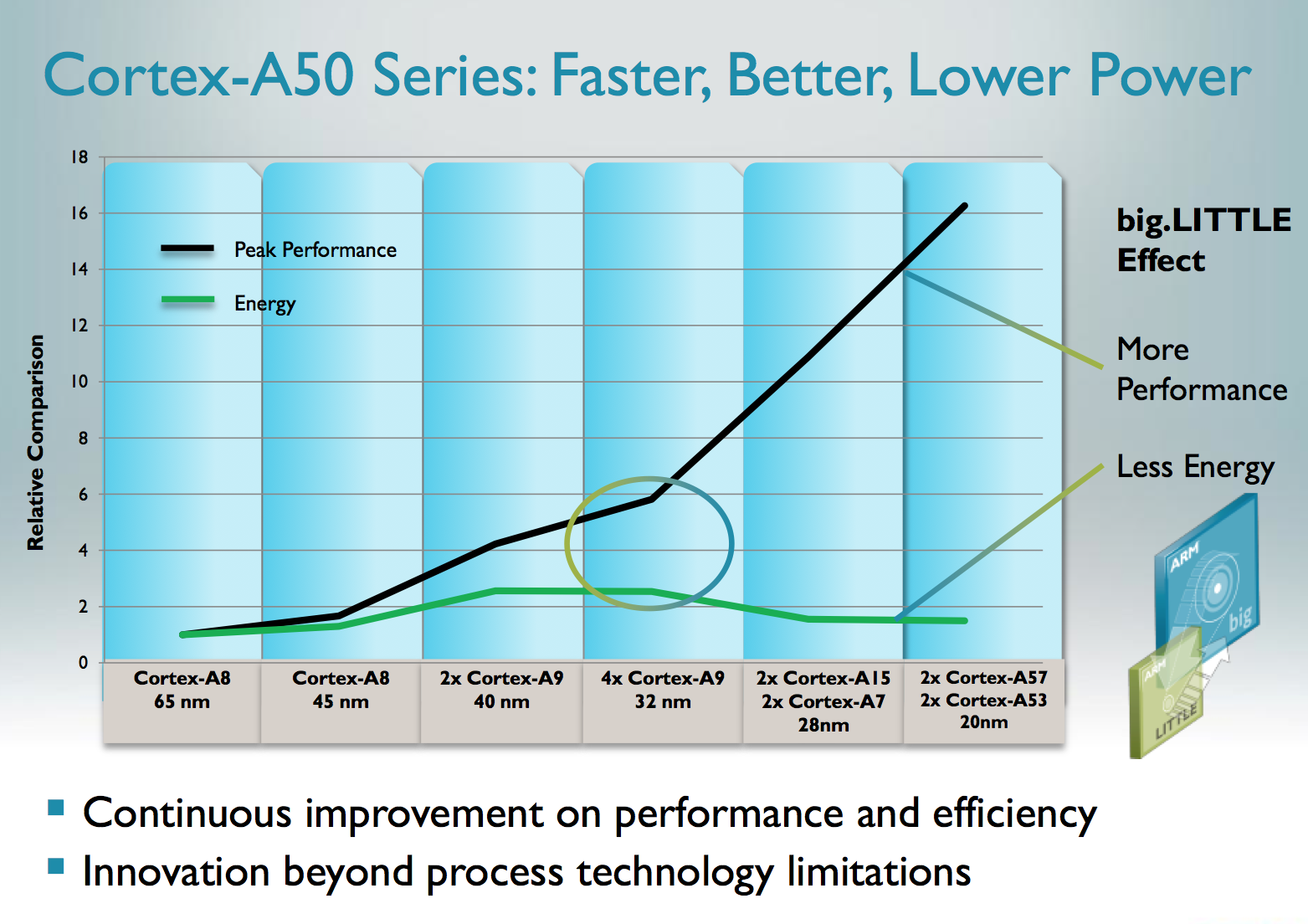
ARM expects the first designs to appear at 28nm and 20nm. There's an obvious path to 14nm as well.
It's interesting to note ARM's commitment to big.LITTLE as a strategy for pushing mobile SoC performance forward. I'm curious to see how the first A15/A7 designs work out. It's also good to see ARM not letting up on pushing its architectures forward.









117 Comments
View All Comments
mayankleoboy1 - Tuesday, October 30, 2012 - link
Great for ARM that it has so many performance improving avenues open. Unlike x86, which has basically stagnated....A5 - Tuesday, October 30, 2012 - link
Yeah, 10% IPC improvements every year is "stagnation".ARM is just going through the same super-growth period that x86 went through in the 90s.
ssj4Gogeta - Wednesday, October 31, 2012 - link
It continues to amaze me how Intel keep increasing the IPC every year while AMD desperately try to tackle the problem by throwing more cores at it.Pipperox - Wednesday, October 31, 2012 - link
This is not entirely true.What you say is correct with the 6x core Thuban, but not with Bulldozer and Piledriver/Trinity architecture.
They didn't simply "throw more cores at it", they designed new cores which are smaller and simpler and share resources, so that they could increase the number of cores without creating a monster chip in terms of size (which would have been difficult and expensive to produce, and dissipate a lot more power).
So in the end Intel and AMD took 2 different strategies to increase performance: Intel increases the efficiency of the existing cores, AMD changed architecture creating cores which individually are slower but where it is easier to pack more of them on a chip.
Also with Trinity/Piledriver AMD achieved a solid 15% IPC improvement, without increasing core count (sort of like an Intel's "tock").
maroon1 - Friday, November 2, 2012 - link
"without creating a monster chip in terms of size"The die size of Bulldozer/Piledriver is 315mm^2
Ivy bridge with HD4000 iGPU is only 160mm^2
Thats almost twice as big as ivy bridge
parkerm35 - Wednesday, December 19, 2012 - link
That might have a lot to do with Intel using 22nm and AMD using 32nm.....Doh!gruffi - Monday, January 7, 2013 - link
Not comparable. Orochi is 32 nm, Ivy Bridge is 22 nm. 22 nm has a theoretical area advantage of factor ~2.12. Furthermore, Orochi is a server design, while Ivy Bridge is a client design. Normally, server designs are always bigger than client designs (more cache, more interconnects, etc). The only useful comparison is a core logic comparison. Bulldozer on 32 nm is ~19 mm^2, Sandy Bridge on 32 nm is ~18 mm^2. So, architecture-wise not much difference at all. The rest is just design-specific and also depends on the process node.gruffi - Monday, January 7, 2013 - link
LOL, poor troll attempt. AMD increases IPC as well, Stars -> Husky, Bulldozer -> Piledriver, Bobcat -> Jaguar. AMD doesn't throw more cores at the problem, but Intel desperately does. When AMD launched Barcelona back in 2007, they had 4 physical cores. The current Orochi design, more than 5 years later, also has only 4 physical cores. That's a core increase of exactly zero percent per die! AMD tries to improve performance with a better multithreading technology than Hyperthreading on core level. Even if the AMD marketing says so, Orochi is not really 8-core. It's more like 4-core with 8 threads. Now compare it with Intel. Back in 2007 they had their C2Q, which actually was only a double dual-core (Conroe). Then there was Nehalem (4 cores), Dunnington (6 cores), Nehalem EX / Sandy Bridge E (8-cores) and Westmere EX (10 cores). That's a core increase of exactly 400 percent per die over 5 years! Ivy Bridge EX is rumored to have up to 15 (16) cores per die. So, the truth is, AMD increases IPC and tries to implement better core technologies. While Intel mostly just throws more cores in. And it amazes me how AMD continues their innovative designs (Trinity / Kaveri, Kabini) with much less resources, while Intel does the same old and boring stuff over and over again with just little tweaks. If they wouldn't have their manufacturing advantage, they would completely suck ass.jakoh - Thursday, June 11, 2015 - link
Lets end this debate, Intel is infront (14nm), regardless of how they both tackle problems.andrewaggb - Tuesday, October 30, 2012 - link
I don't know that x86 has stagnated, intel keeps upping performance and reducing power every year. It's not revolutionary, but it's constant improvement. Atom 2 might be good.ARM is definitely more interesting at the moment.