AMD’s Jaguar Architecture: The CPU Powering Xbox One, PlayStation 4, Kabini & Temash
by Anand Lal Shimpi on May 23, 2013 12:00 AM EST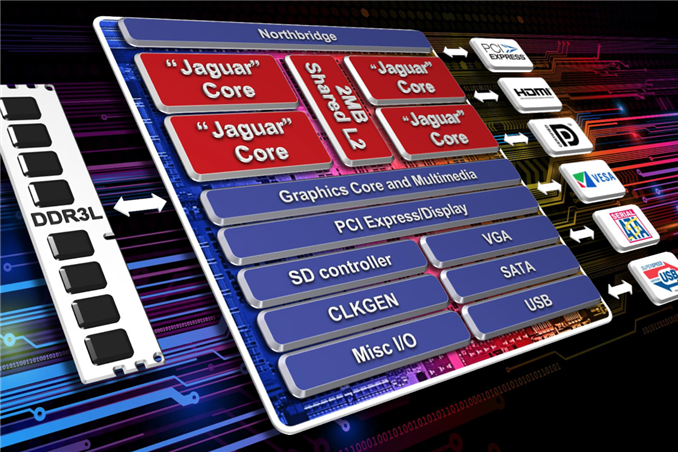
Microprocessor architectures these days are largely limited, and thus defined, by power consumption. When it comes to designing an architecture around a power envelope the rule of thumb is any given microprocessor architecture can scale to target an order of magnitude of TDPs. For example, Intel’s Core architectures (Sandy/Ivy Bridge) effectively target the 13W - 130W range. They can surely be used in parts that consume less or more power, but at those extremes it’s more efficient to build another microarchitecture to target those TDPs instead.
Both AMD and Intel feel similarly about this order of magnitude rule, and thus both have two independent microprocessor architectures that they leverage to build chips for the computing continuum. From Intel we have Atom for low power, and Core for high performance. In 2010 AMD gave us Bobcat for its low power roadmap, and Bulldozer for high performance.
Both the Bobcat and Bulldozer lines would see annual updates. In 2011 we saw Bobcat used in Ontario and Zacate SoCs, as a part of the Brazos platform. Last year AMD announced Brazos 2.0, using slightly updated versions of those very same Bobcat based SoCs. Today AMD officially launches Kabini and Temash, APUs based on the first major architectural update to Bobcat: the Jaguar core.






Jaguar: Improved 2-wide Out-of-Order
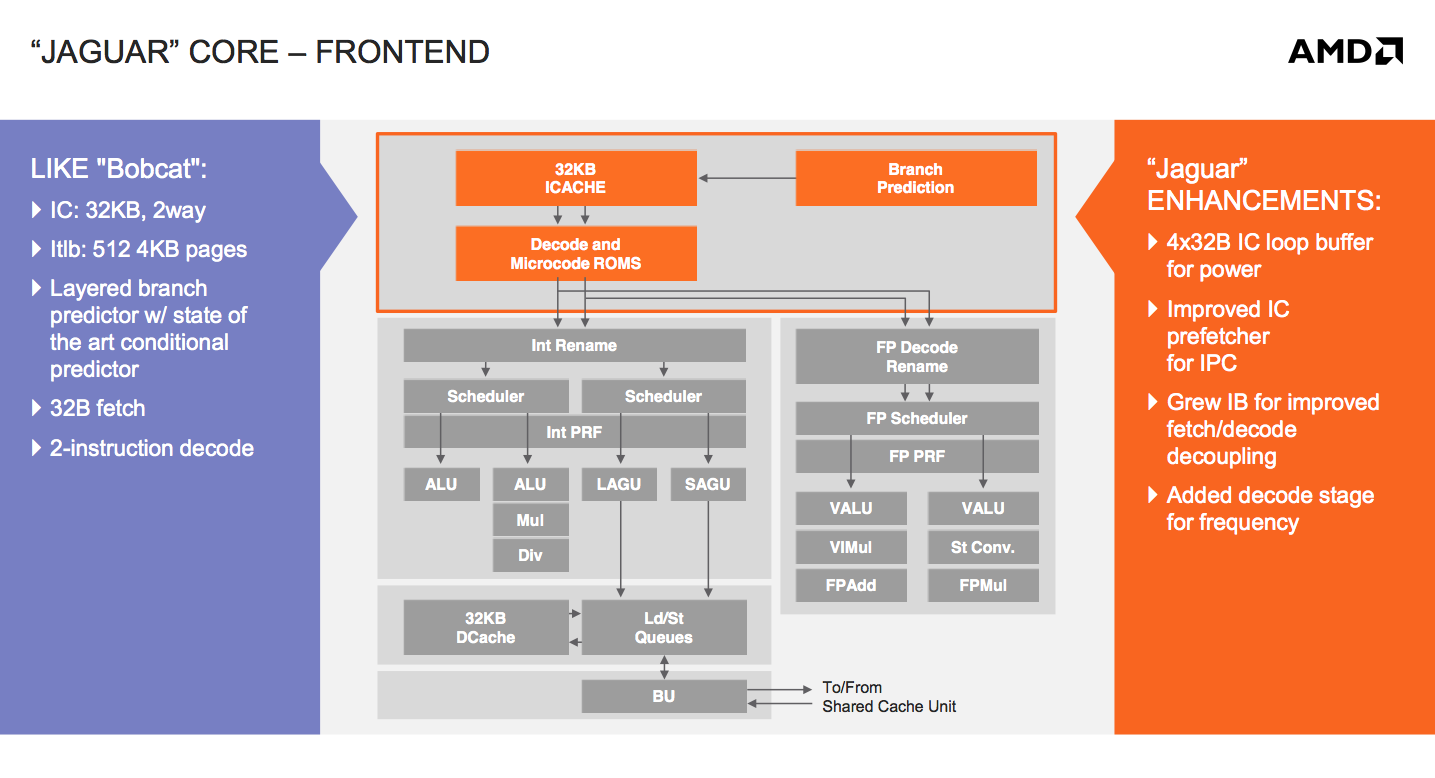
At the core-level, Jaguar still looks a lot like Bobcat. The same dual-issue, out-of-order architecture that AMD introduced in 2010 remains intact with Jaguar. The same L1 cache, front end and execution blocks are all still here. Given the ARM transition from a dual-issue, out-of-order core with Cortex A9 to a three-issue, OoO design with the Cortex A15, I expected something similar from AMD. Despite moving to a smaller manufacturing process (28nm), AMD was very focused on increasing performance within the same TDP or lower with Jaguar. The driving motivator? While Bobcat ended up in netbooks, nettops and other low cost, but thick machines, Jaguar needed to go into even thinner form factors: tablets. AMD still has no intentions of getting into the smartphone SoC space, but the Windows 8 (and Android?) tablet market is fair game. Cellular connectivity isn’t a requirement there, particularly at the lower price points, and AMD can easily be a second source alternative to Intel Atom based designs.
The average number of instructions executed per clock (IPC) is still below 1 for most client workloads. There’s a certain amount of burst traffic to be expected but given the types of dependencies you see in most use cases, AMD felt the gain from making the machine wider wasn’t worth the power tradeoff. There’s also the danger of making the cat-cores too powerful. While just making them 3-issue to begin with wouldn’t dramatically close the gap between the cat-cores and the Bulldozer family, there’s still a desire for there to be clear separation between the two microarchitectures.
The move to a three-issue design would certainly increase performance, but AMD’s tablet ambitions and power sensitivity meant it would save that transition for another day. I should point out that ARM is increasingly looking like the odd-man-out here, with both Jaguar and Intel’s Silvermont retaining the dual-issue design of their predecessors. Part of this has to do with the fact that while AMD and Intel are very focused on driving power down, ARM has aspirations of moving up in the performance/power chain.
The width of the front end is only one lever AMD could have used to increase performance. While it was a pretty big lever that AMD chose not to pull, there are other smaller levers that were exercised in Jaguar.
There’s now a 4 x 32-byte loop buffer for the instruction cache. Whenever a loop is detected, instead of fetching instructions executed in the loop from the L1 I-cache over and over again, they’re serviced from this small loop buffer. If this sounds like a trace cache or decoded micro-op cache, don’t get too excited, Jaguar’s loop buffer is neither of these things. There are no pipeline savings or powered down fetch/decode units. The only benefit to the new loop buffer is the instruction cache doesn’t have to be fired up during every iteration of a buffered loop. In other words, this is a very specific play to reduce power consumption - not to improve performance.
All microprocessors see tons of simulation work before they’re ever brought to market. Even once a design is done, additional profiling is used to identify bottlenecks, which are then prioritized for addressing in future designs. All bottleneck removal has to be vetted against power, cost and schedule constraints. Given an infinite budget across all vectors you could eliminate all bottlenecks, but you’d likely take an infinite amount of time to complete the design. Taking all of those realities into account usually means making tradeoffs, even when improving a design.
We saw the first example of a clear tradeoff when AMD stuck with a 2-issue front end for Jaguar. Not including a decoded micro-op cache and opting for a simpler loop buffer instead is an example of another. AMD likely noticed a lot of power being wasted during loops, and the addition of a loop buffer was probably the best balance of complexity, power savings and cost.
AMD also improved the instruction cache prefetcher, not because of an over abundance of bandwidth but by revisiting the Bobcat design and spending some more time on the implementation in Jaguar. The IC prefetcher improvements are simply AMD doing things better in Jaguar, not being under the same pressure to introduce a brand new architecture as was the case with Bobcat.
The instruction buffer between the instruction cache and decoders grew in size with Jaguar, a sort of half step towards the more heavily decoupled fetch/decode stages in Bulldozer.
Jaguar adds support for new instructions (SSE4.1/4.2, AES, CLMUL, MOVBE, AVX, F16C, BMI1) as well as 40-bit physical addressing.
The final change to the front of Jaguar was the addition of another decode stage, purely for frequency gains. It turns out that in Bobcat the decoder was one of the critical paths limiting maximum frequency. Adding another decode stage simply gave AMD enough wiggle room to hit their frequency targets for Jaguar at 28nm.








78 Comments
View All Comments
vision33r - Thursday, May 23, 2013 - link
Real shame is that AMD has not gotten into the mobile market at all. APUs like this would've been great for tablets.jeffkibuule - Thursday, May 23, 2013 - link
Even if AMD makes the chip, and OEM has to be willing to use it.duploxxx - Thursday, May 23, 2013 - link
exactly the problem, current atom is a horrible cpu in wathever device, whatever frequency you put it. have used them in notebooks and even now in a tablet. Bobcat on the other hand was awesome in the netbook range. THe temash would be way better suited for all these devices but as usual OEM focus on the blue brand with market jingles and dominancy and in the end its the end consumer (WE) that suffer from it and if it continues like this we will even suffer more. (less innovative, higher prices, dominant predefined design (something already horrible today) but many people fail to see that........as if they think there Intel system they just bought is a better suited device for everything...mganai - Thursday, May 23, 2013 - link
Intel's been going easy on AMD these past few years.Plus, Atom is finally due for its big update this year, following which we'll be seeing a more frequent update schedule in line with their Core processors.
The heterogeneous solution was what won the PS4 and XB1 for AMD.
thebeastie - Saturday, May 25, 2013 - link
Simple, Money! Why roll as fast as you can when your already the fastest and aren't going to be bringing any more money then you are now.Bobs_Your_Uncle - Saturday, May 25, 2013 - link
I'd read an interesting perspective on why Intel refrained from "kicking AMD to the curb & on down into the storm sewer" (sorry; can't recall the source). In essence, given the scope of Intel's unquestioned dominance in their chosen markets, (& mobile's on the radar), were they to act with any obvious & direct intent to further weaken, (or even try & finish off), AMD, Intel would find themselves in an extremely difficult, exceedingly complex & decidedly unpleasant set of circumstances.By decimating their only possible source of true competition, Intel would be responsible for invoking upon themselves intense anti-trust scrutiny; a result that would be inevitable assuming regulatory agencies were functioning properly.
By backing off a bit, Intel may well cede some amount of business to AMD, but they retain a legitimate market competitor & at the same time continue collecting very healthy margins. The premiums charged on sales can then be used to continue funding aggressive Intel R&D, and, uh, marketing related expenditures, too.
spartaman64 - Wednesday, June 4, 2014 - link
for a company that could "kick amd to the curb" intel is awfully nervous about amd's kaveriWolfpup - Wednesday, June 12, 2013 - link
Yeah, but regardless AMD's had the FAR better CPU now for years. I've been running the lowest end version of it for a couple of years in a tiny notebook, and from the beginning wished people were using it for tablets.Flunk - Friday, June 6, 2014 - link
When you say current Atom, are you referring to Baytrail? Previous Atoms were pretty bad for Windows boxes, in my personal experience. But the new generation is significantly more powerful (About on par with a Core 2 Duo on benchmarks). They seem pretty reasonable for basic office tasks, this may not include all the lowest-end versions.Flunk - Friday, June 6, 2014 - link
NVM, followed the wrong link and didn't see the date. Thought this was about something else. May 2013 Atoms sucked.