Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
Technical Comparisons
Finally, to close out this look at the Rogue architecture we wanted to spend a bit of time looking at how it compares to other architectures. Unfortunately the lack of details we have on other SoC GPU architectures means we can’t make any meaningful comparisons there beyond the GFLOPs comparisons we do today (and that says nothing of real world efficiency). But we can compare it to the next best thing, which is mobile parts based on desktop GPU architectures from AMD and NVIDIA. The latter case being especially interesting, as we know Kepler will be coming to SoCs with the K1.
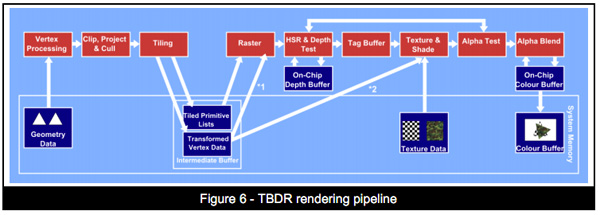
With that said, and we can’t reiterate this enough, this is just a look at theoretical performance. It is not possible to take into account efficiency measures such as memory bandwidth, ROPs, or especially early rejection optimizations such as Tile Based Deferred Rendering. TBDR is Imagination’s ace, and while other GPU firms have their own early rejection technologies, from what little we know about each of them, none of them quite matches TBDR. So Rogue’s theoretical performance aside, if Imagination is rejecting significantly more work before it hits their shaders, then they would have greater performance when all other factors were held equal. The only way to compare the real world performance of these architectures is to benchmark their real world performance, so please do not consider this the final word on performance.
For this comparison we’ll be looking at NVIDIA’s Kepler based K1, AMD’s GCN based A4-1350, and Imagination’s Rogue based GX6650 and G6230. Because Rogue is offered in multiple configurations it’s difficult to determine just how large a Rogue configuration would equal K1 or A4-1350 from a performance and size perspective, but given the anticipated integration time for Series 6XT, a 6 cluster configuration seems the most likely.
| GPU Specification Comparison | |||||||
| NVIDIA K1 | Imagination PVR GX6650 | Imagination PVR G6230 | AMD A4-1350 | NVIDIA GTX 650 | |||
| FP32 ALUs | 192 | 192 | 64 | 128 | 384 | ||
| FP32 FLOPs | 384 | 384 | 128 | 256 | 768 | ||
| Pixels/Clock (ROPs) | 4 | 12 | 4 | 4 | 16 | ||
| Texels/Clock | 8 | 12 | 4 | 8 | 32 | ||
| GFLOPS @ 300MHz | 115.2 GFLOPS | 115.2 GFLOPS | 38.4 GFLOPS | 76.8 GFLOPS | 230.4 GFLOPS | ||
| Architecture | Kepler | Rogue (6XT) | Rogue (6) | GCN 1.0 | Kepler | ||
Briefly, we can see that as far as theoretical shading performance is concerned, both the GX6650 and K1 are neck-and-neck when clockspeeds are held equal. Both of them have the same ILP dependency, so both need to be able to pull off some FP32 co-issued instructions if they are to achieve their full 384 FLOP/cycle throughput. The A4-1350 on the other hand has no such limitation, making it easier to hit its 256 FLOP/cycle throughput, but never getting the chance to go past it.
Meanwhile it was surprising to see that GX6650’s theoretical pixel throughput was so high. 12 pixels/clock (12 ROPs) is much higher than either K1 or A4-1350, and in fact is quite high for an SoC class product. Most designs use relatively few ROPs here for size and power reasons, and not all designs replicate the ROPs with the shader blocks. So having 12 ROPs here was unexpected. At the same time it remains to be seen how well real world efficiency tracks this, as ROPs are frequently memory bandwidth constrained, which makes such a large number of ROPs harder to feed.
Moving on to quickly compare texture throughput, again it’s surprising to see just how many texels GX6650 can push. TMUs regularly scale with shader core counts, so the fact that it’s three-fold what a single TMU design can do is not unexpected, but until now we had never realized just what that meant for overall texture throughput. 12 texels/clock is (thankfully) a lot of texels for a SoC GPU. That said, this is also a memory bandwidth heavy operation, so it’s difficult to say how real world performance will track it.
Finally, to throw in a true desktop comparison for the fun of it, we also put NVIDIA’s Kepler based GTX 650 in the chart. Clockspeeds aside, the best case scenario for even GX6650 is that it achieves half the shading throughput as GTX 650. The ROP throughput gap on the other hand is narrower (but GTX 650 will easily have 2x the memory bandwidth) and the texture throughput gap is nearly 3x wider. In practice it would be difficult to imagine the GX6650 being any closer than about 40% of the GTX 650’s performance, once again owing to the massive memory bandwidth difference between an SoC and a discrete GPU.
Final Words
Wrapping up this architectural overview of Imagination’s Rogue architecture, it’s exciting to finally see much of the underpinnings of an SoC GPU design. While we haven’t seen every facet of Rogue yet – and admittedly it’s unlikely we ever will – the information that we’ve received on Rogue so far has given us a much better perspective on how Imagination’s latest graphics architecture works, and for that matter how Series 6 and Series 6XT differ from one-another.
Ultimately we still can’t do true apples-to-apples comparisons with these integrated GPUs (we can’t separate the CPU and memory controller from the GPU), but it should be helpful for better understanding why certain products perform the way they do, and determining what the stronger products might be in the long run. So it’s with some hope and a bit of luck that this might get the ball rolling with the other SoC GPU vendors, getting them to open up their doors a bit more so that we can see what’s inside their designs.
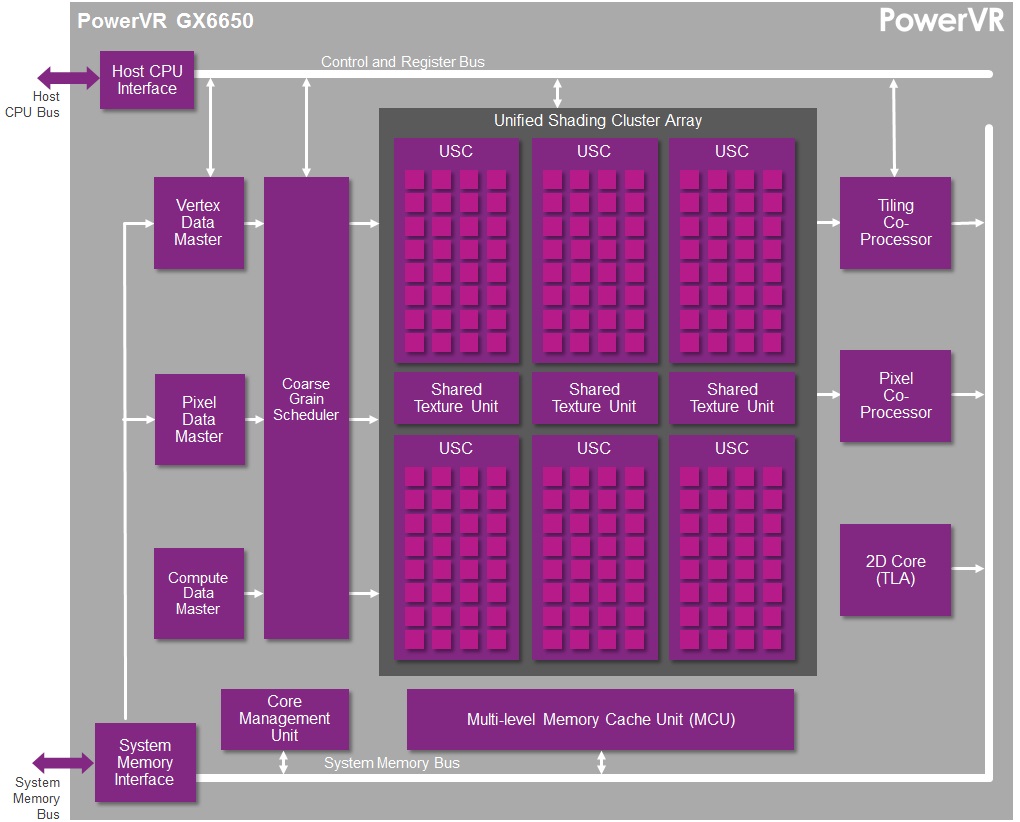
Coming back full circle to Imagination, we’re left with one of the big reasons why they’re opening up in the first place: core wars. Imagination is keen on not being seen as being left behind on core counts, and while we don’t expect the “core” terminology to go away any time soon, now that we have these low level Rogue architecture details, we can agree that Imagination does have a salient point as far as counting cores and ALUs is concerned.
For the purposes of FP32 operations a Rogue USC is essentially equivalent to a 32 core design, with an ILP reliance similar to what we’re seeing out of NVIDIA right now, though perhaps greater than some other designs. Or as Imagination likes to compare it to, a 6 USC design would be equivalent to a 192 core design. This speaks nothing of real world performance – without real world hardware it can’t, there are too many external variables – but it does give us an idea of how many clusters Imagination’s customers would need to achieve various degrees of theoretical performance, including what it would take to beat the competition.








95 Comments
View All Comments
dragonsqrrl - Tuesday, February 25, 2014 - link
... and the 64-bit architecture in the A7 is a completely different story. Apple wasn't first to market with 64-bit because they had an accelerated development schedule compared to other chipmakers. Apple was first to market because they started development first, ahead of everyone else.Apple doesn't develop Series 6, they license it, and we know when it becomes available for integration and when devices based on it come to market. We also know how long it usually takes between tapeout of an SOC, production, and final availability in devices, and based on this it would be very difficult if not impossible for Apple to put a 6XT in the A8 if they keep to their regular release schedule. I think going from an ~18 to ~8 month schedule is a bit much even for Apple, especially considering the new process shrink.
michael2k - Wednesday, February 26, 2014 - link
It's available for license now. Doesn't that normally mean that, as soon as the computer finishes synthesizing the design, it can be taped out now as well? The issue then is how much work needs to be done to get the design to work at the desired power envelope and clock, and if said work is worth it.Samus - Monday, February 24, 2014 - link
Considering the highly parallel nature of graphics processing, PowerVR's low core count and non-linear arrangement will make then weak in real-world gaming but strong in synthetic GFLOPS since their cores are stronger.For example, ATI has the weakest GPU cores of everybody but they cram over 2000 onto a GPU, seems to be doing pretty good for their performance.
michael2k - Tuesday, February 25, 2014 - link
Your example is irrelevant since ATI has no mobile solution and PowerVR has been the strongest in real world gaming since, well, until the K1 ships, PowerVR has had no real competition.Adreno is technically competent, but Qualcomm isn't seeking to push their transistor budget too high.
extide - Friday, February 28, 2014 - link
Wow, so you basically didn't read the article at all did you? This nonsense is exactly what this article is trying to prevent. Lol.Anders CT - Tuesday, February 25, 2014 - link
And what chip is using a GX6650 GPU? None existing that I know of.The Tegra K1 is a chip. Kepler and PowerVR 6XT is GPU architectures. And kepler has been around for several years.
dragonsqrrl - Wednesday, February 26, 2014 - link
Not sure how to respond to this, other than you completely misinterpreted my comment.dragonsqrrl - Wednesday, February 26, 2014 - link
Apologies, you weren't responding to my comment. I was wondering why it made no sense in the context of what I said.The comments section on Anandtech makes it really difficult sometimes to see who's responding to who, especially when it gets really long like this.
Sonicadvance1 - Monday, February 24, 2014 - link
So they have 2x Float32 ALU cores, 4x Float16 ALU cores, and a SFU core.This has no mention of Integer cores.
Am I to assume that integers won't run on the F32/F16 cores but instead of the SFU core so using integers will be 1/6th the speed of floats?
Seems like a large drawback, Mali and Adreno both run integers at the same speed as 32bit floats.
ryszu - Monday, February 24, 2014 - link
Integer happens on the F32 hardware.